Caffe 执行python实例并可视化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Caffe 执行python实例并可视化相关的知识,希望对你有一定的参考价值。
. 配置python
安装的python需要是 Anaconda2,启动命令行执行如下安装。
1.1.安装 jupyter
pip install jupyter
1.2.安装ipython ipython-notebook
conda install ipython ipython-notebook
conda install python-matplotlib python-scipy python-pandas python-sympy python-nose
安装完成后执行
jupyter notebook
1.3 重新编译 pycaffe 库,把编译好的 build\\x64\\Release\\pycaffe\\caffe 拷贝到 C:\\Anaconda2\\Lib\\site-packages即可,执行如下语句测试安装是否通过
python import caffe
2. 运行caffe的python版并可视化
2.1 获取CaffeNet网络并储存到models/bvlc_reference_caffenet目录下
cd caffe_windows python ./scripts/download_model_binary.py models/bvlc_reference_caffenet
2.2 启动ipython
cd ./python
ipython notebook
若启动成功的话,将会弹出如下的窗口:
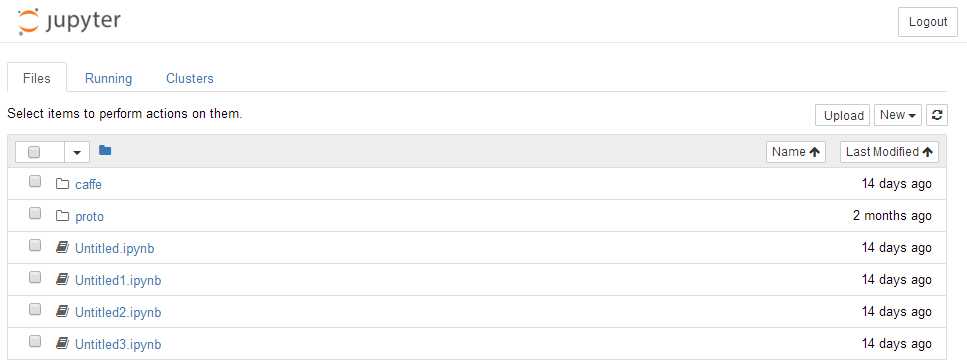
随后单机“New” -> 选择 “Python2”
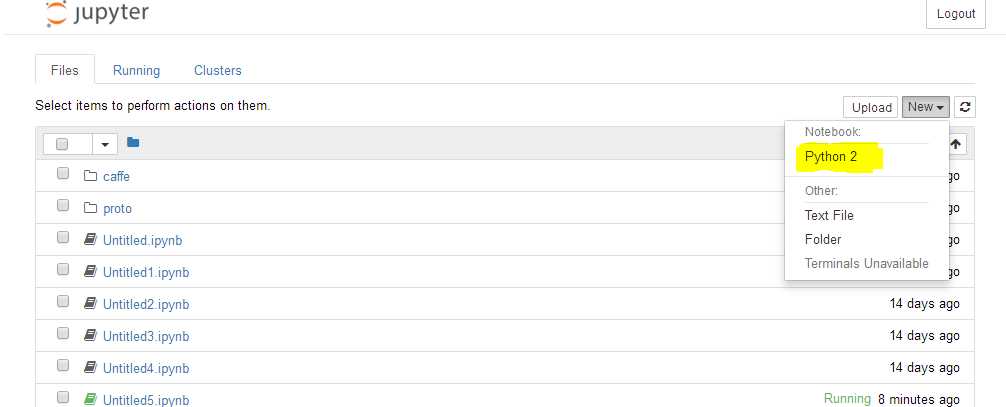
会弹出如下所示的新建tab页:
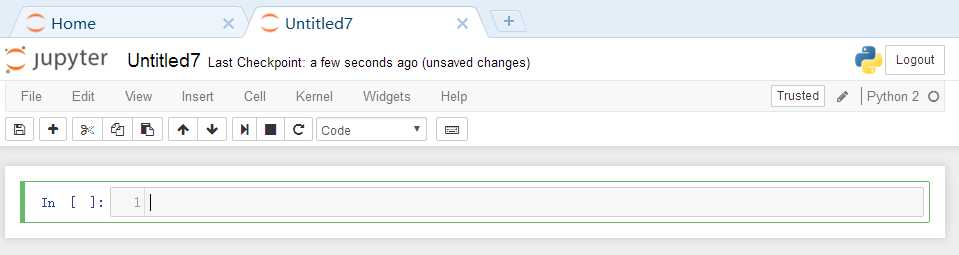
在输入框中输入如下python脚本:
import numpy as np import matplotlib.pyplot as plt %matplotlib inline # Make sure that caffe is on the python path: caffe_root = ‘../‘ # this file is expected to be in {caffe_root}/examples #这里注意路径一定要设置正确,记得前后可能都有“/”,路径的使用是 #{caffe_root}/examples,记得 caffe-root 中的 python 文件夹需要包括 caffe 文件夹。 #caffe_root = ‘/home/bids/caffer-root/‘ #为何设置为具体路径反而不能运行呢 import sys sys.path.insert(0, caffe_root + ‘python‘) import caffe #把 ipython 的路径改到指定的地方(这里是说刚开始在终端输入ipython notebook命令时,一定要确保是在包含caffe的python文件夹,这就是上面代码(×)),以便可以调入 caffe 模块,如果不改路径,import 这个指令只会在当前目录查找,是找不到 caffe 的。 plt.rcParams[‘figure.figsize‘] = (10, 10) plt.rcParams[‘image.interpolation‘] = ‘nearest‘ plt.rcParams[‘image.cmap‘] = ‘gray‘ #显示的图表大小为 10,图形的插值是以最近为原则,图像颜色是灰色 import os if not os.path.isfile(caffe_root + ‘models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel‘): print("Downloading pre-trained CaffeNet model...") !../scripts/download_model_binary.py ../models/bvlc_reference_caffenet #设置网络为测试阶段,并加载网络模型prototxt和数据平均值mean_npy caffe.set_mode_cpu()# 采用CPU运算 net = caffe.Net(caffe_root + ‘models/bvlc_reference_caffenet/deploy.prototxt‘,caffe_root + ‘models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel‘,caffe.TEST) # input preprocessing: ‘data‘ is the name of the input blob == net.inputs[0] transformer = caffe.io.Transformer({‘data‘: net.blobs[‘data‘].data.shape}) transformer.set_transpose(‘data‘, (2,0,1)) transformer.set_mean(‘data‘, np.load(caffe_root + ‘python/caffe/imagenet/ilsvrc_2012_mean.npy‘).mean(1).mean(1)) # mean pixel,ImageNet的均值 transformer.set_raw_scale(‘data‘, 255) # the reference model operates on images in [0,255] range instead of [0,1]。参考模型运行在【0,255】的灰度,而不是【0,1】 transformer.set_channel_swap(‘data‘, (2,1,0)) # the reference model has channels in BGR order instead of RGB,因为参考模型本来频道是 BGR,所以要将RGB转换 # set net to batch size of 50 net.blobs[‘data‘].reshape(50,3,227,227) #加载测试图片,并预测分类结果。 net.blobs[‘data‘].data[...] = transformer.preprocess(‘data‘, caffe.io.load_image(caffe_root + ‘examples/images/cat.jpg‘)) out = net.forward() print("Predicted class is #{}.".format(out[‘prob‘][0].argmax())) plt.imshow(transformer.deprocess(‘data‘, net.blobs[‘data‘].data[0])) #plt.show() # load labels,加载标签,并输出top_k imagenet_labels_filename = caffe_root + ‘data/ilsvrc12/synset_words.txt‘ try: labels = np.loadtxt(imagenet_labels_filename, str, delimiter=‘\\t‘) except: !../data/ilsvrc12/get_ilsvrc_aux.sh labels = np.loadtxt(imagenet_labels_filename, str, delimiter=‘\\t‘) # sort top k predictions from softmax output top_k = net.blobs[‘prob‘].data[0].flatten().argsort()[-1:-6:-1] print labels[top_k] # CPU 与 GPU 比较运算时间 # CPU mode net.forward() # call once for allocation %timeit net.forward() # GPU mode caffe.set_device(0) caffe.set_mode_gpu() net.forward() # call once for allocation %timeit net.forward() #****提取特征并可视化**** # for each layer, show the output shape for layer_name, blob in net.blobs.iteritems(): print layer_name + ‘\\t‘ + str(blob.data.shape) #网络的特征存储在net.blobs,参数和bias存储在net.params,以下代码输出每一层的名称和大小。这里亦可手动把它们存储下来。 [(k, v.data.shape) for k, v in net.blobs.items()] #显示出各层的参数和形状,第一个是批次,第二个 feature map 数目,第三和第四是每个神经元中图片的长和宽,可以看出,输入是 227*227 的图片,三个频道,卷积是 32 个卷积核卷三个频道,因此有 96 个 feature map [(k, v[0].data.shape) for k, v in net.params.items()] #输出:一些网络的参数 #**可视化的辅助函数** # take an array of shape (n, height, width) or (n, height, width, channels)用一个格式是(数量,高,宽)或(数量,高,宽,频道)的阵列 # and visualize each (height, width) thing in a grid of size approx. sqrt(n) by sqrt(n)每个可视化的都是在一个由一个个网格组成 def vis_square(data, padsize=1, padval=0): data -= data.min() data /= data.max() # force the number of filters to be square n = int(np.ceil(np.sqrt(data.shape[0]))) padding = ((0, n ** 2 - data.shape[0]), (0, padsize), (0, padsize)) + ((0, 0),) * (data.ndim - 3) data = np.pad(data, padding, mode=‘constant‘, constant_values=(padval, padval)) # tile the filters into an image data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1))) data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:]) plt.imshow(data) #根据每一层的名称,选择需要可视化的层,可以可视化filter(参数)和output(特征) # the parameters are a list of [weights, biases],各层的特征,第一个卷积层,共96个过滤器 filters = net.params[‘conv1‘][0].data vis_square(filters.transpose(0, 2, 3, 1)) #使用 ipt.show()观看图像 plt.show() #显示特征 filters_b = net.params[‘conv1‘][1].data print filters_b #过滤后的输出,96 张 featuremap feat = net.blobs[‘conv1‘].data[4, :96] vis_square(feat, padval=1) #使用 ipt.show()观看图像: plt.show() #显示特征 filters_b = net.params[‘conv1‘][1].data print filters_b feat = net.blobs[‘conv1‘].data[0, :36] vis_square(feat, padval=1) #第二个卷积层:有 128 个滤波器,每个尺寸为 5X5X48。我们只显示前面 48 个滤波器,每一个滤波器为一行。输入: filters = net.params[‘conv2‘][0].data vis_square(filters[:48].reshape(48**2, 5, 5)) #使用 ipt.show()观看图像: plt.show() #显示特征 filters_b = net.params[‘conv2‘][1].data print filters_b #第二层输出 256 张 feature,这里显示 36 张。输入: feat = net.blobs[‘conv2‘].data[4, :36] vis_square(feat, padval=1) #使用 ipt.show()观看图像 plt.show() #显示特征 filters_b = net.params[‘conv2‘][1].data print filters_b feat = net.blobs[‘conv2‘].data[0, :36] vis_square(feat, padval=1) #第三个卷积层:全部 384 个 feature map,输入: feat = net.blobs[‘conv3‘].data[4] vis_square(feat, padval=0.5) #使用 ipt.show()观看图像: plt.show() #第四个卷积层:全部 384 个 feature map,输入: feat = net.blobs[‘conv4‘].data[4] vis_square(feat, padval=0.5) #使用 ipt.show()观看图像: plt.show() #第五个卷积层:全部 256 个 feature map,输入: feat = net.blobs[‘conv5‘].data[4] vis_square(feat, padval=0.5) #使用 ipt.show()观看图像: plt.show() #第五个 pooling 层:我们也可以观察 pooling 层,输入: feat = net.blobs[‘pool5‘].data[4] vis_square(feat, padval=1) #使用 ipt.show()观看图像: plt.show() #用caffe 的python接口提取和保存特征比较方便。 features = net.blobs[‘conv5‘].data # 提取卷积层 5 的特征 np.savetxt(‘conv5_feature.txt‘, features, fmt=‘%s‘) # 将特征存储到本文文件中 #然后我们看看第六层(第一个全连接层)输出后的直方分布: feat = net.blobs[‘fc6‘].data[4] plt.subplot(2, 1, 1) plt.plot(feat.flat) plt.subplot(2, 1, 2) _ = plt.hist(feat.flat[feat.flat > 0], bins=100) #使用 ipt.show()观看图像: plt.show() #第七层(第二个全连接层)输出后的直方分布:可以看出值的分布没有这么平均了。 feat = net.blobs[‘fc7‘].data[4] plt.subplot(2, 1, 1) plt.plot(feat.flat) plt.subplot(2, 1, 2) _ = plt.hist(feat.flat[feat.flat > 0], bins=100) #使用 ipt.show()观看图像: plt.show() #The final probability output, prob feat = net.blobs[‘prob‘].data[0] plt.plot(feat.flat) #最后看看标签:Let‘s see the top 5 predicted labels. # load labels imagenet_labels_filename = caffe_root + ‘data/ilsvrc12/synset_words.txt‘ try: labels = np.loadtxt(imagenet_labels_filename, str, delimiter=‘\\t‘) except: !../data/ilsvrc12/get_ilsvrc_aux.sh labels = np.loadtxt(imagenet_labels_filename, str, delimiter=‘\\t‘) # sort top k predictions from softmax output top_k = net.blobs[‘prob‘].data[0].flatten().argsort()[-1:-6:-1] print labels[top_k]
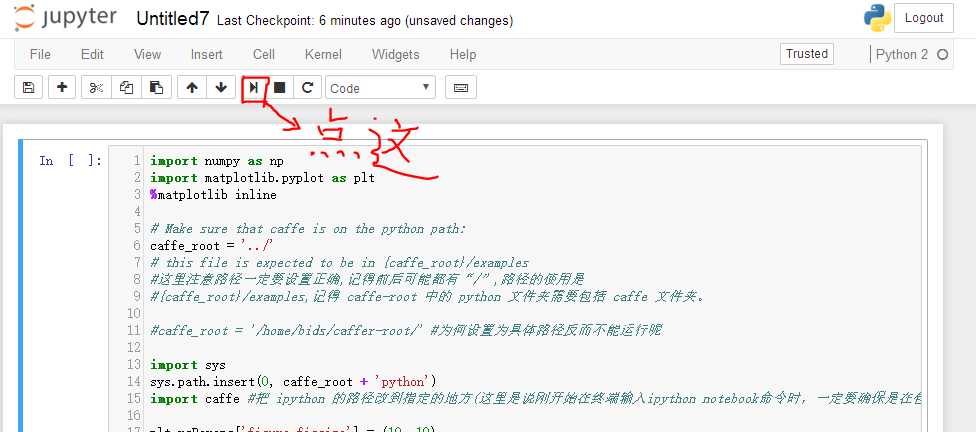
随后点击如下按钮执行脚本:
以上是关于Caffe 执行python实例并可视化的主要内容,如果未能解决你的问题,请参考以下文章