Python模块学习4collections模块
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python模块学习4collections模块相关的知识,希望对你有一定的参考价值。
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple() |
factory function for creating tuple subclasses with named fields |
deque |
list-like container with fast appends and pops on either end |
ChainMap |
dict-like class for creating a single view of multiple mappings |
Counter |
dict subclass for counting hashable objects |
OrderedDict |
dict subclass that remembers the order entries were added |
defaultdict |
dict subclass that calls a factory function to supply missing values |
UserDict |
wrapper around dictionary objects for easier dict subclassing |
UserList |
wrapper around list objects for easier list subclassing |
UserString |
wrapper around string objects for easier string subclassing |
1、namedtuple()
namedtuple 是一个函数,它用来创建一个自定义的元组对象,并且规定了元组元素的个数,并可以用属性而不是索引来引用元组的某个元素。可以通过 namedtuple 来定义一种数据类型,它具备元组的不变性,又可以根据属性来引用,十分方便。
1 >>> # 基本用法 2 >>> Point = namedtuple(‘Point‘, [‘x‘, ‘y‘]) 3 >>> p = Point(11, y=22) # instantiate with positional or keyword arguments 4 >>> p[0] + p[1] # 跟tuple一样,可用index 5 33 6 >>> x, y = p # 跟tuple一样赋值 7 >>> x, y 8 (11, 22) 9 >>> p.x + p.y # 可用name取值 10 33 11 >>> p # readable __repr__ with a name=value style 12 Point(x=11, y=22)
somenamedtuple._make(iterable) # 直接把可迭代的数列转换为namedtuple
somenamedtuple._asdict() # 把“name”和值对应起来
somenamedtuple._replace(**kwargs) # 该值,tuple是不可变的,这里有_replace方法可该值
somenamedtuple._source # ...
somenamedtuple._fields # 该namedtuple里值的名称
1 >>>#somenamedtuple._make(iterable) # 直接把可迭代的数列转换为namedtuple 2 >>> t = [11, 22] 3 >>> Point._make(t) 4 Point(x=11, y=22)
1 >>> # somenamedtuple._asdict() # 把“name”和值对应起来 2 >>> p = Point(x=11, y=22) 3 >>> p._asdict() 4 OrderedDict([(‘x‘, 11), (‘y‘, 22)])
1 >>> # somenamedtuple._replace(**kwargs) # tuple是不可变的,但namedtuple有_replace方法可改值 2 >>> p = Point(x=11, y=22) 3 >>> p._replace(x=33) 4 Point(x=33, y=22)
1 >>> # somenamedtuple._source # ...
1 >>> # somenamedtuple._fields # 该namedtuple里值的名称 2 >>> p._fields # view the field names 3 (‘x‘, ‘y‘)
2、deque()
使用list 存储数据时,按照索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈。
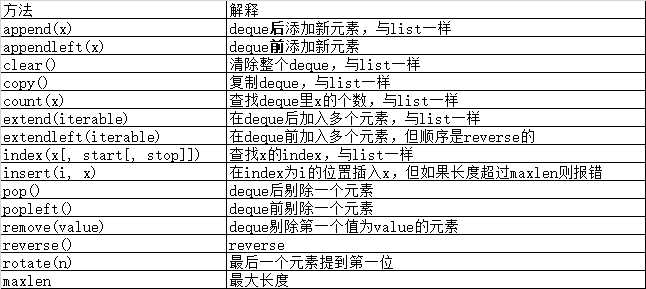
1 >>> from collections import deque 2 >>> d = deque(‘ghi‘) # make a new deque with three items 3 >>> for elem in d: # iterate over the deque‘s elements 4 ... print(elem.upper()) 5 G 6 H 7 I 8 9 >>> d.append(‘j‘) # add a new entry to the right side 10 >>> d.appendleft(‘f‘) # add a new entry to the left side 11 >>> d # show the representation of the deque 12 deque([‘f‘, ‘g‘, ‘h‘, ‘i‘, ‘j‘]) 13 14 >>> d.pop() # return and remove the rightmost item 15 ‘j‘ 16 >>> d.popleft() # return and remove the leftmost item 17 ‘f‘ 18 >>> list(d) # list the contents of the deque 19 [‘g‘, ‘h‘, ‘i‘] 20 >>> d[0] # peek at leftmost item 21 ‘g‘ 22 >>> d[-1] # peek at rightmost item 23 ‘i‘ 24 25 >>> list(reversed(d)) # list the contents of a deque in reverse 26 [‘i‘, ‘h‘, ‘g‘] 27 >>> ‘h‘ in d # search the deque 28 True 29 >>> d.extend(‘jkl‘) # add multiple elements at once 30 >>> d 31 deque([‘g‘, ‘h‘, ‘i‘, ‘j‘, ‘k‘, ‘l‘]) 32 >>> d.rotate(1) # right rotation 33 >>> d 34 deque([‘l‘, ‘g‘, ‘h‘, ‘i‘, ‘j‘, ‘k‘]) 35 >>> d.rotate(-1) # left rotation 36 >>> d 37 deque([‘g‘, ‘h‘, ‘i‘, ‘j‘, ‘k‘, ‘l‘]) 38 39 >>> deque(reversed(d)) # make a new deque in reverse order 40 deque([‘l‘, ‘k‘, ‘j‘, ‘i‘, ‘h‘, ‘g‘]) 41 >>> d.clear() # empty the deque 42 >>> d.pop() # cannot pop from an empty deque 43 Traceback (most recent call last): 44 File "<pyshell#6>", line 1, in -toplevel- 45 d.pop() 46 IndexError: pop from an empty deque 47 48 >>> d.extendleft(‘abc‘) # extendleft() reverses the input order 49 >>> d 50 deque([‘c‘, ‘b‘, ‘a‘])
4、Counter()
Basic:可通过tuple、dict、list、str初始化Counter
>>> c = Counter() # a new, empty counter >>> c = Counter(‘gallahad‘) # a new counter from an iterable >>> c = Counter({‘red‘: 4, ‘blue‘: 2}) # a new counter from a mapping >>> c = Counter(cats=4, dogs=8) # a new counter from keyword args >>> c = Counter([‘eggs‘, ‘ham‘]) >>> c[‘bacon‘] # count of a missing element is zero 0
Counter对象类似于字典,如果某个项缺失,会返回0,而不是报出KeyError;
1 >>> c = Counter([‘eggs‘,‘ham‘]) 2 >>> c[‘bacon‘]#没有‘bacon‘ 3 0 4 >>> c[‘eggs‘]#有‘eggs‘ 5 1
将一个元素的数目设置为0,并不能将它从counter中删除,使用del可以将这个元素删除;
1 >>> c 2 Counter({‘eggs‘: 1, ‘ham‘: 1}) 3 >>> c[‘eggs‘] = 0 4 >>> c 5 Counter({‘ham‘: 1, ‘eggs‘: 0})#‘eggs‘依然存在 6 >>> del c[‘eggs‘] 7 >>> c 8 Counter({‘ham‘: 1})#‘eggs‘不存在
Counter对象支持以下三个字典不支持的方法,elements(),most_common(),subtract();
element(),返回一个迭代器,每个元素重复的次数为它的数目,顺序是任意的顺序,如果一个元素的数目少于1,那么elements()就会忽略它;
1 >>> c = Counter(a=2,b=4,c=0,d=-2,e = 1) 2 >>> c 3 Counter({‘b‘: 4, ‘a‘: 2, ‘e‘: 1, ‘c‘: 0, ‘d‘: -2}) 4 >>> list(c.elements()) 5 [‘a‘, ‘a‘, ‘b‘, ‘b‘, ‘b‘, ‘b‘, ‘e‘]
most_common(),返回一个列表,包含counter中n个最大数目的元素
,如果忽略n或者为None,most_common()将会返回counter中的所有元素,元素有着相同数目的将会以任意顺序排列;
1 >>> Counter(‘abracadabra‘).most_common(3) 2 [(‘a‘, 5), (‘r‘, 2), (‘b‘, 2)] 3 >>> Counter(‘abracadabra‘).most_common() 4 [(‘a‘, 5), (‘r‘, 2), (‘b‘, 2), (‘c‘, 1), (‘d‘, 1)] 5 >>> Counter(‘abracadabra‘).most_common(None) 6 [(‘a‘, 5), (‘r‘, 2), (‘b‘, 2), (‘c‘, 1), (‘d‘, 1)]
subtract(),从一个可迭代对象中或者另一个映射(或counter)中,元素相减,类似于dict.update(),但是subtracts 数目而不是替换它们,输入和输出都有可能为0或者为负;
1 >>> c = Counter(a=4,b=2,c=0,d=-2) 2 >>> d = Counter(a=1,b=2,c=-3,d=4) 3 >>> c.subtract(d) 4 >>> c 5 Counter({‘a‘: 3, ‘c‘: 3, ‘b‘: 0, ‘d‘: -6})
update(),从一个可迭代对象中或者另一个映射(或counter)中所有元素相加,类似于dict.update,是数目相加而非替换它们,另外,可迭代对象是一个元素序列,而非(key,value)对构成的序列;
1 >>> c 2 Counter({‘a‘: 4, ‘b‘: 2, ‘c‘: 0, ‘d‘: -2}) 3 >>> d 4 Counter({‘d‘: 4, ‘b‘: 2, ‘a‘: 1, ‘c‘: -3}) 5 >>> c.update(d) 6 >>> c 7 Counter({‘a‘: 5, ‘b‘: 4, ‘d‘: 2, ‘c‘: -3})
Counter对象常见的操作
1 >>> c 2 Counter({‘a‘: 5, ‘b‘: 4, ‘d‘: 2, ‘c‘: -3}) 3 >>> sum(c.values())# 统计所有的数目 4 8 5 >>> list(c)# 列出所有唯一的元素 6 [‘a‘, ‘c‘, ‘b‘, ‘d‘] 7 >>> set(c)# 转换为set 8 set([‘a‘, ‘c‘, ‘b‘, ‘d‘]) 9 >>> dict(c)# 转换为常规的dict 10 {‘a‘: 5, ‘c‘: -3, ‘b‘: 4, ‘d‘: 2} 11 >>> c.items()# 转换为(elem,cnt)对构成的列表 12 [(‘a‘, 5), (‘c‘, -3), (‘b‘, 4), (‘d‘, 2)] 13 >>> c.most_common()[:-4:-1]# 输出n个数目最小元素 14 [(‘c‘, -3), (‘d‘, 2), (‘b‘, 4)] 15 >>> c += Counter()# 删除数目为0和为负的元素 16 >>> c 17 Counter({‘a‘: 5, ‘b‘: 4, ‘d‘: 2}) 18 >>> Counter(dict(c.items()))# 从(elem,cnt)对构成的列表转换为counter 19 Counter({‘a‘: 5, ‘b‘: 4, ‘d‘: 2}) 20 >>> c.clear()# 清空counter 21 >>> c 22 Counter()
在Counter对象进行数学操作,得多集合(counter中元素数目大于0)加法和减法操作,是相加或者相减对应元素的数目;交集和并集返回对应数目的最小值和最大值;每个操作均接受暑促是有符号的数目,但是输出并不包含数目为0或者为负的元素;
1 >>> c = Counter(a=3,b=1,c=-2) 2 >>> d = Counter(a=1,b=2,c=4) 3 >>> c+d#求和 4 Counter({‘a‘: 4, ‘b‘: 3, ‘c‘: 2}) 5 >>> c-d#求差 6 Counter({‘a‘: 2}) 7 >>> c & d#求交集 8 Counter({‘a‘: 1, ‘b‘: 1}) 9 >>> c | d#求并集 10 Counter({‘c‘: 4, ‘a‘: 3, ‘b‘: 2})
5、OrderedDict()
OrderedDict类似于正常的词典,只是它记住了元素插入的顺序,当在有序的词典上迭代时,返回的元素就是它们第一次添加的顺序。
basic
1 >>> d = {"banana":3,"apple":2,"pear":1,"orange":4} 2 >>> # dict sorted by key 3 >>> OrderedDict(sorted(d.items(),key = lambda t:t[0])) 4 OrderedDict([(‘apple‘, 2), (‘banana‘, 3), (‘orange‘, 4), (‘pear‘, 1)]) 5 >>> # dict sorted by value 6 >>> OrderedDict(sorted(d.items(),key = lambda t:t[1])) 7 OrderedDict([(‘pear‘, 1), (‘apple‘, 2), (‘banana‘, 3), (‘orange‘, 4)]) 8 >>> # dict sorted by length of key string 9 >>>a = OrderedDict(sorted(d.items(),key = lambda t:len(t[0]))) 10 >>>a 11 OrderedDict([(‘pear‘, 1), (‘apple‘, 2), (‘orange‘, 4), (‘banana‘, 3)]) 12 >>> del a[‘apple‘] 13 >>> a 14 OrderedDict([(‘pear‘, 1), (‘orange‘, 4), (‘banana‘, 3)]) 15 >>> a["apple"] = 2 16 >>> a 17 OrderedDict([(‘pear‘, 1), (‘orange‘, 4), (‘banana‘, 3), (‘apple‘, 2)])
popitem(last=True)
- popitem方法返回和删除一个(key,value)对,如果last=True,就以LIFO方式执行,否则以FIFO方式执行。
move_to_end(key, last=True)- move_to_end方法,last=True时,把字典里某一元素移动到OrderedDict的最后一位;last=False时,把字典里某一元素移动到OrderedDict的第一位。
1 >>> d = OrderedDict.fromkeys(‘abcde‘) 2 >>> d.move_to_end(‘b‘) 3 >>> ‘‘.join(d.keys()) 4 ‘acdeb‘ 5 >>> d.move_to_end(‘b‘, last=False) 6 >>> ‘‘.join(d.keys()) 7 ‘bacde‘
实例用法:
当元素删除时,排好序的词典保持着排序的顺序;但是当新元素添加时,就会被添加到末尾,就不能保持已排序。
创建一个有序的词典,可以记住最后插入的key的顺序,如果一个新的元素要重写已经存在的元素,那么原始的插入位置就会改变成末尾,
1 >>> class LastUpdatedOrderedDict(OrderedDict): 2 ... def __setitem__(self,key,value): 3 ... if key in self: 4 ... del self[key] 5 ... OrderedDict.__setitem__(self, key, value) 6 ... 7 >>> obj = LastUpdatedOrderedDict() 8 >>> obj["apple"] = 2 9 >>> obj["windows"] = 3 10 >>> obj 11 LastUpdatedOrderedDict([(‘apple‘, 2), (‘windows‘, 3)]) 12 >>> obj["apple"] = 1 13 >>> obj 14 LastUpdatedOrderedDict([(‘windows‘, 3), (‘apple‘, 1)])
一个有序的词典可以和Counter类一起使用,counter对象就可以记住元素首次出现的顺序:
1 from collections import Counter,OrderedDict 2 class OrderedCounter(Counter,OrderedDict): 3 def __repr__(self): 4 return "%s(%r)"%(self.__class__.__name__,OrderedDict(self)) 5 6 def __reduce__(self): 7 return self.__class__,(OrderedDict(self)) 8 9 #和OrderDict一起使用的Counter对象 10 obj = OrderedCounter() 11 wordList = ["b","a","c","a","c","a"] 12 for word in wordList: 13 obj[word] += 1 14 print(obj) 15 16 # 普通的Counter对象 17 cnt = Counter() 18 wordList = ["b","a","c","a","c","a"] 19 for word in wordList: 20 cnt[word] += 1 21 print(cnt) 22 23 >>>OrderedCounter(OrderedDict([(‘b‘, 1), (‘a‘, 3), (‘c‘, 2)])) 24 >>>Counter({‘a‘: 3, ‘c‘: 2, ‘b‘: 1})
6、defaultdict
defaultdict是内置数据类型dict的一个子类,基本功能与dict一样,只是重写了一个方法__missing__(key)和增加了一个可写的对象变量default_factory。
basic:
以下的default_factory分别为list、int、set
1 >>> s = [(‘yellow‘, 1), (‘blue‘, 2), (‘yellow‘, 3), (‘blue‘, 4), (‘red‘, 1)] 2 >>> d = defaultdict(list) 3 >>> for k, v in s: 4 ... d[k].append(v) 5 ... 6 >>> sorted(d.items()) 7 [(‘blue‘, [2, 4]), (‘red‘, [1]), (‘yellow‘, [1, 3])] 8 >>> d = {} 9 >>> for k, v in s: 10 ... d.setdefault(k, []).append(v) 11 ... 12 >>> sorted(d.items()) 13 [(‘blue‘, [2, 4]), (‘red‘, [1]), (‘yellow‘, [1, 3])] 14 15 >>> s = ‘mississippi‘ 16 >>> d = defaultdict(int) 17 >>> for k in s: 18 ... d[k] += 1 19 ... 20 >>> sorted(d.items()) 21 [(‘i‘, 4), (‘m‘, 1), (‘p‘, 2), (‘s‘, 4)] 22 >>> a = defaultdict(set) 23 >>> a[‘1‘].add(1) 24 >>> a[‘1‘].add(‘a‘) 25 >>> a[‘2‘].add(2) 26 >>> a[‘2‘].add(‘b‘) 27 >>> a 28 defaultdict(<class ‘set‘>, {‘1‘: {1, ‘a‘}, ‘2‘: {2, ‘b‘}})
1 >>> s = [(‘red‘, 1), (‘blue‘, 2), (‘red‘, 3), (‘blue‘, 4), (‘red‘, 1), (‘blue‘, 2 4)] 3 >>> d = defaultdict(set) 4 >>> for k,v in s:d[k].add(v) 5 ... 6 >>> d.items() 7 [(‘blue‘, set([2, 4])), (‘red‘, set([1, 3]))]
默认的,初始化后,未输入数据前,会有一个默认值如下:
1 >>> l = defaultdict(list) 2 >>> s = defaultdict(set) 3 >>> i = defaultdict(int) 4 >>> l[‘test‘] 5 [] 6 >>> s[‘test‘] 7 set() 8 >>> i[‘test‘] 9 0
此时,可初始化一个lambda函数,则默认值可为自己定义的值:
>>> def constant_factory(value): ... return lambda: value >>> d = defaultdict(constant_factory(‘<missing>‘)) >>> d.update(name=‘John‘, action=‘ran‘) >>> ‘%(name)s %(action)s to %(object)s‘ % d ‘John ran to <missing>‘
以上是关于Python模块学习4collections模块的主要内容,如果未能解决你的问题,请参考以下文章