python ==》 模块和正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python ==》 模块和正则表达式相关的知识,希望对你有一定的参考价值。
今日内容:
re 模块
collentions 模块
正则表达式
1.re 模块:
re模块下常用的方法:


1 import re 2 #1.re.findall() 3 ret1 = re.findall(‘a‘,‘eva egon yuan‘) #以 ‘a‘ 为眼,找所有。 并且 以列表返回。 4 print(ret1) 5 6 #2.re.search() 7 ret2 = re.search(‘a‘,‘eva egon yuan‘).group() #从字符串里匹配 ‘a’ 8 print(ret2) 9 10 #3.re.match() 11 ret3 = re.match(‘a‘,‘abc‘).group() #匹配 ‘a’ 12 print(ret3) 13 14 # 4.re.split() 15 ret4 = re.split(‘[ab]‘,‘zxcabcd‘) #以 ‘ab’ 分割 16 print(ret4) 17 18 5.re.sub():把数字换成 ‘H’ 19 ret5 = re.sub(‘\\d‘,‘H‘,‘eva3egon4yuan4‘) 20 print(ret5) 21 22 6.匹配数字 23 obj = re.compile(‘\\d{3}‘) 24 ret6 = obj.search(‘abc123eee‘) 25 print(ret6.group()) 26 27 7.返回了一个迭代器 28 ret7 = re.finditer(‘\\d‘,‘ds3sy4784a‘) 29 print(next(ret7).group()) 30 print(next(ret7).group()) 31 print([i.group()for i in ret7]) 32 33 # 8.findall 的优先级查询 34 ret8 = re.findall (‘www.(oldboy|baidu).com‘,‘www.baidu.com‘) 35 print(ret8) 36 37 ret8 = re.findall (‘www.(?:baidu|oldboy).com‘,‘www.oldboy.com‘) 38 print(ret8) 39 40 # 9.split 的优先级 41 ret9 = re.split(‘\\d+‘,‘eva3egon4yuan‘) 42 print(ret9) 43 44 ret9 = re.split(‘(\\d+)‘,‘eva3egon4yuan‘) 45 print(ret9) 46 47 48 输出结果: 49 [‘a‘, ‘a‘] 50 a 51 a 52 [‘zxc‘, ‘‘, ‘cd‘] 53 evaHegonHyuanH 54 123 55 3 56 4 57 [‘7‘, ‘8‘, ‘4‘] 58 [‘baidu‘] 59 [‘www.oldboy.com‘] 60 [‘eva‘, ‘egon‘, ‘yuan‘] 61 [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘]
1 findall的优先级查询:
import re ret = re.findall(‘www.(baidu|oldboy).com‘, ‘www.oldboy.com‘) print(ret) # [‘oldboy‘] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘) print(ret) # [‘www.oldboy.com‘]
2 split的优先级查询:
ret=re.split("\\d+","eva3egon4yuan")
print(ret) #结果 : [‘eva‘, ‘egon‘, ‘yuan‘]
ret=re.split("(\\d+)","eva3egon4yuan")
print(ret) #结果 : [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘]
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
2.collections 模块:
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
(1).namedtuple
from collections import namedtuple point = namedtuple (‘point‘,[‘x‘,‘y‘]) p=point(1,2) print(p) 结果: point(x=1, y=2)
(2).deque:
from collections import deque q = deque([‘a‘,‘b‘,‘c‘]) q.append(‘x‘) q.appendleft(‘y‘) print(q) 结果: deque([‘y‘, ‘a‘, ‘b‘, ‘c‘, ‘x‘])
(3).counter:
c = Counter(‘abcdeabcdabcaba‘)
print c
输出:
Counter({‘a‘: 5, ‘b‘: 4, ‘c‘: 3, ‘d‘: 2, ‘e‘: 1})
(4).Orderedict:
from collections import OrderedDict d = ([(‘a‘,1),(‘b‘,2),(‘c‘,3),(‘zxc‘,123)]) print(d) o_d = OrderedDict([(‘a‘,1),(‘b‘,2),(‘c‘,3)]) print(o_d) 结果: [(‘a‘, 1), (‘b‘, 2), (‘c‘, 3), (‘zxc‘, 123)] OrderedDict([(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)])
(5).Defaultdict
from collections import defaultdict
values = [11,22,33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value > 66:
my_dict[‘k1‘].append(value)
else:
my_dict[‘k2‘].append(value)
print(my_dict)
结果:
defaultdict(<class ‘list‘>, {‘k2‘: [11, 22, 33, 44, 55, 66], ‘k1‘: [77, 88, 99, 90]})
3.正则表达式:
一说规则我已经知道你很晕了,现在就让我们先来看一些实际的应用。在线测试工具 http://tool.chinaz.com/regex/
首先你要知道的是,谈到正则,就只和字符串相关了。在我给你提供的工具中,你输入的每一个字都是一个字符串。
其次,如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的。
比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上。这连python的字符串操作都可以轻松做到。
那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
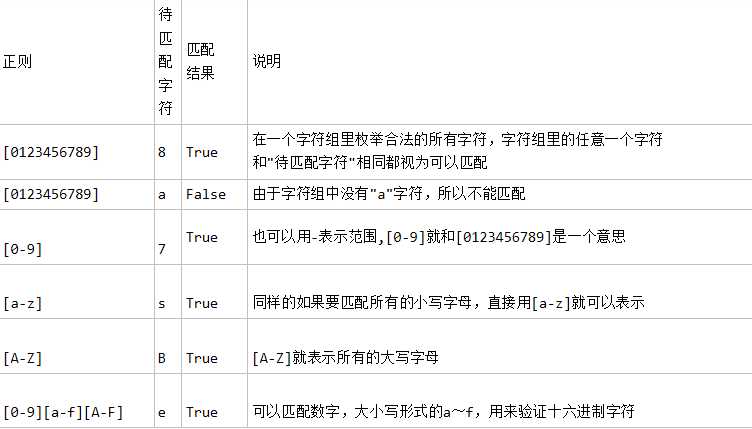
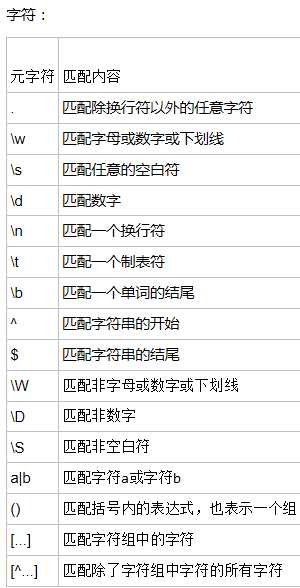
元字符: . 匹配除换行符以外的任意字符。 \\w 匹配字母或者数字或者下划线或汉字。 \\s 匹配任意的空白符 \\d 匹配数字 \\n 匹配一个换行符 \\t 匹配一个制表符 \\b 匹配一个单词的结尾 ^ 匹配字符串的开始 $ 匹配字符串的结 \\W 匹配非字母和数字或者下划线或者汉字。 \\D 匹配非数字 \\S 匹配非空白符 a | b 匹配字符a 或 字符b () 匹配括号内的表达式也表示一个组 [] 匹配字符串中的字符 [^ ] 匹配除了字符组中字符的所有字符。 量词: * 重复零次或者更多次 + 重复一次或更多次 ?重复零次或一次 {n} 重复n次 {n,} 重复n次 或 更多次 {n,m} 重复n到m次

几个常用的非贪婪匹配Pattern:
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法:
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
以上是关于python ==》 模块和正则表达式的主要内容,如果未能解决你的问题,请参考以下文章