《分布式技术原理与算法解析》学习笔记Day14
Posted 技术修行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《分布式技术原理与算法解析》学习笔记Day14相关的知识,希望对你有一定的参考价值。
 这篇文章主要描述流式计算,它负责处理实时数据,一般适用于数据密集型应用,另外文章来探讨了Apache Storm相关的知识。
这篇文章主要描述流式计算,它负责处理实时数据,一般适用于数据密集型应用,另外文章来探讨了Apache Storm相关的知识。
分布式计算模式:Stream
什么是流数据?
实时性任务主要是针对流数据处理,对处理时延要求很高,通常需要常驻服务进程,等待数据的随时到来随时处理,以保证低时延。
流数据有4个特征:
- 数据如流水般持续、快速到达。
- 海量数据规模,数据量可以达到TB或者PB级别。
- 对实时性要求高,随着时间流逝,数据的价值会大大降低。
- 数据顺序无法保证。
流计算一般用于处理数据密集型应用,它实时获取来自不同数据源的海量数据,进行实时分析处理,获得有价值信息。
使用流计算进行数据处理,包括3个步骤:
- 提交流式计算作业。系统再运行期间,由于收集的是同一类型的数据,执行的事同一种服务,因此流式计算作业处理逻辑不可更改。如果用户停止当前作业运行后再次提交作业,由于流计算不提供数据存储服务,因此之前已经计算完成的数据无法重新再次计算。
- 加载流逝数据进行流计算。流式计算作业一旦启动将一直处于等待事件出发的状态,一旦有小批量数据进入流逝数据存储,系统会立刻执行计算逻辑并得到结果。
- 持续输出计算结果。在得到小批量数据的计算结果后,流计算会立刻将结果数据写入在线/批量系统,无需等待整体数据的计算结果。
详细的流程如下。

流计算不提供流式数据的存储服务,数据是持续流动的,在计算完成后会立刻丢弃。流计算适用于需要处理持续到达的数据流,对数据处理有较高实时性要求的场景,为了及时处理流数据,流计算框架必须是低延迟、可扩展、高可靠的。
Apache Storm和MapReduce有什么区别?
Hadoop上运行的是“MapReduce作业”,Storm上运行的是“计算拓扑”。MapReduce的一个作业在得到结果之后会结束,而计算拓扑在没有杀死进程前会一直运行。
Storm集群包括两种节点:主节点和工作节点:
- Nimbus是整个Storm集群的守护进程,以唯一实例的方式运行在主节点上。它负责把任务分配和分发给集群的工作节点,并监控这些任务的执行情况,当某个节点故障时,它会重新将分配到该节点的任务转到其他节点。
- Supervisor是Storm集群中的工作守护进程,每个工作节点都存在一个这样的实例。它通过ZooKeeper和Nimbus守护进程通信。
Storm的结构图如下。
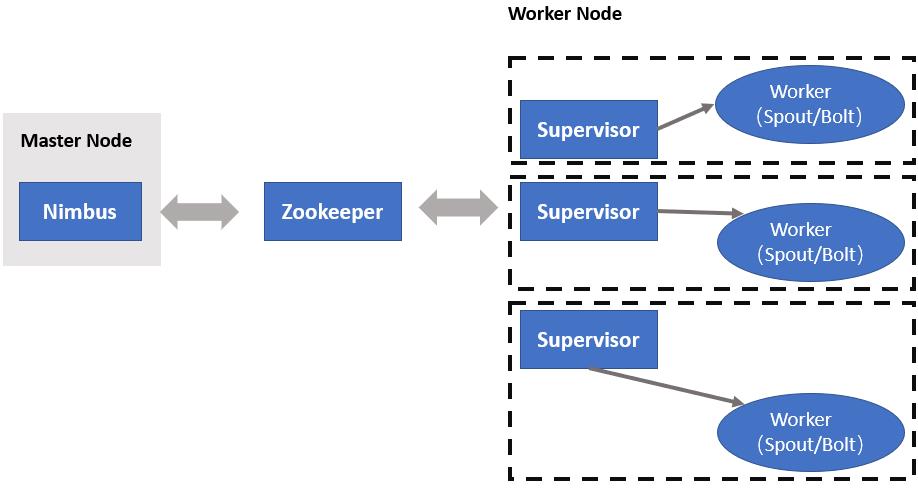
Storm为数据流转换提供了基本组件Spout和Bolt:
- Spout主要用于接收源数据,它会从一个外部的数据源读取数据元组,然后将它们发送到拓扑中。
- Bolt负责处理输入的数据流,数据处理后可能输出新的流作为下一个Bolt的输入。每个Bolt通常只具备单一的计算逻辑,复杂的数据流转换通常需要使用多个Bolt并通过多个步骤完成。
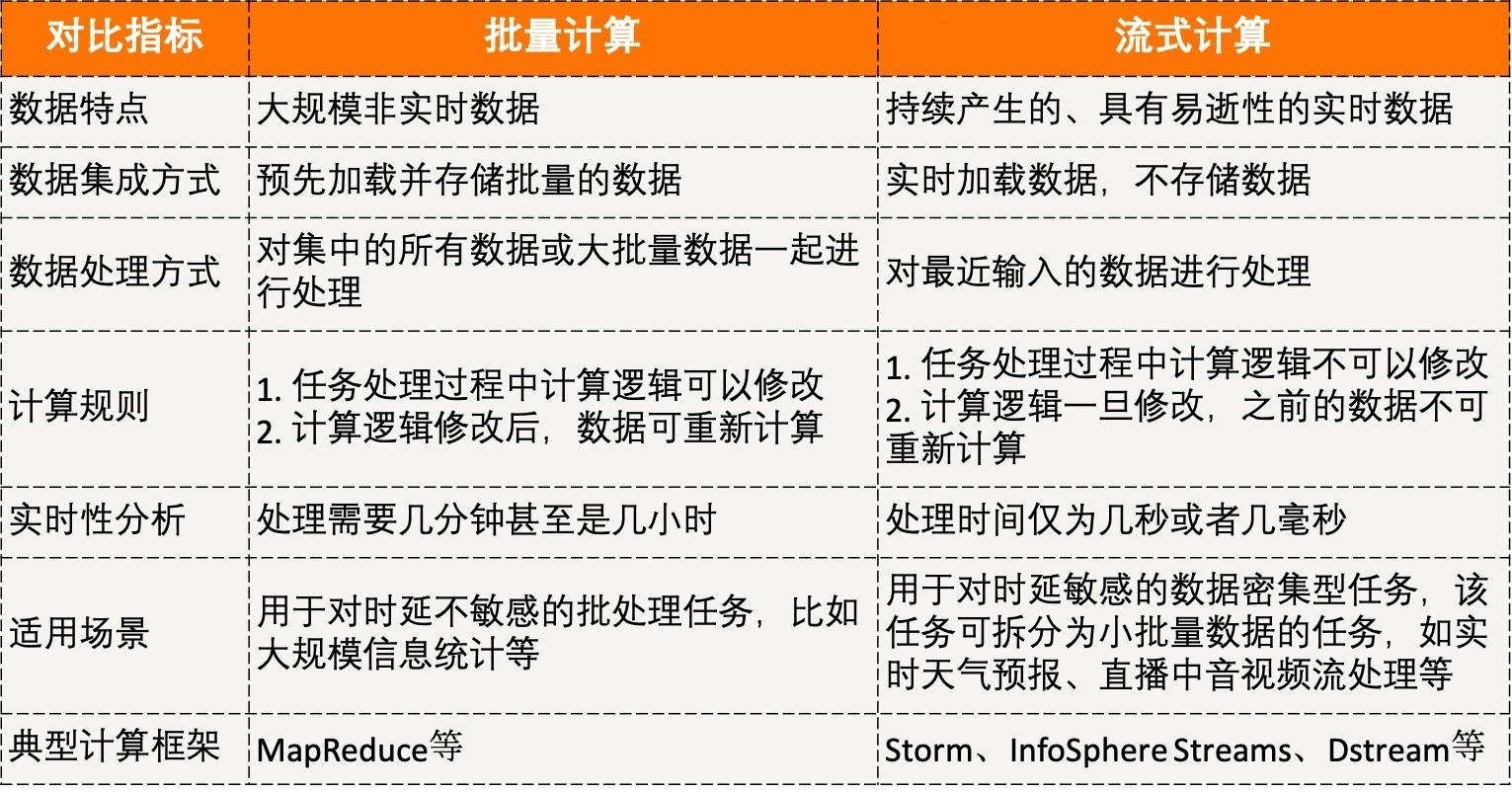
流计算和批量计算有什么区别?
它们有各自的适用场景。批量计算适用于对时延要求低的任务,流计算适用于低延时、易扩展的场景,例如直播中音视频的处理。
下面是流计算和批量计算的详细比较。
作者:李潘
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
以上是关于《分布式技术原理与算法解析》学习笔记Day14的主要内容,如果未能解决你的问题,请参考以下文章