python爬虫—— 抓取今日头条的街拍的妹子图
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫—— 抓取今日头条的街拍的妹子图相关的知识,希望对你有一定的参考价值。
AJAX 是一种用于创建快速动态网页的技术。 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
近期在学习获取js动态加载网页的爬虫,决定通过实例加深理解。
1、首先是url的研究(谷歌浏览器的审查功能)
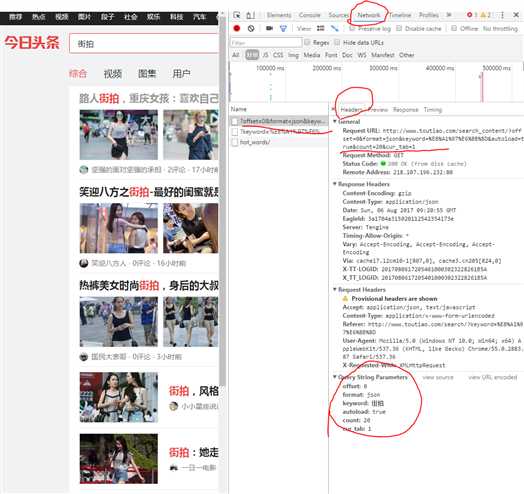
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1
对应用get方法到url上获取信息。网页对应offset=0 、keyword=%E8%A1%97%E6%8B%8D 是会变的。如果要批量爬取,就得设置循环。
当网页下拉,offset会20、40、60的变化,其实就是每次加载20个内容。
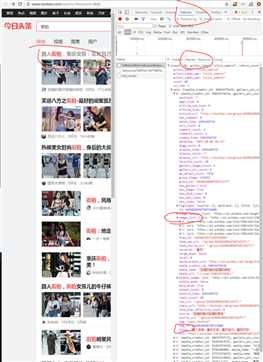
2、
通过requests获得response,进行json解析。
还是一样的网页,切换到Preview,可以看到json的数据内容。title在[‘date‘][0][‘title‘]下,其他类似。
import json import requests,os def download_pic(file,name,html): r = requests.get(html) filename=os.path.join(file,name+‘.jpg‘) with open(filename,‘wb‘) as f: f.write(r.content) url = ‘http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1‘ res = requests.get(url) json_data = json.loads(res.text) data = json_data[‘data‘] for i in data: print i[‘title‘] file_path = os.getcwd()+‘\\image‘ print file_path for p in i[‘image_detail‘]: print p[‘url‘] name = p[‘url‘].split(‘/‘)[-1] download_pic(file_path,name,p[‘url‘])
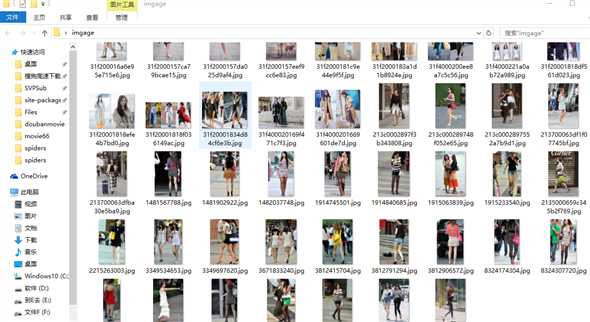
在当前目录新建image文件夹,然后爬虫下载图片。
图片名截取url链接的后面部分31e30003d4be75c719ae.jpg
例如http://p3.pstatp.com/large/31e30003d4be75c719ae
结果如下:(仅供学习交流)
循环什么的没写只爬取前20个链接的图片。
以上是关于python爬虫—— 抓取今日头条的街拍的妹子图的主要内容,如果未能解决你的问题,请参考以下文章