Python爬虫基础之lxml
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫基础之lxml相关的知识,希望对你有一定的参考价值。
一、Python lxml的基本应用
1 <html> 2 <head> 3 <title> 4 The Dormouse‘s story 5 </title> 6 </head> 7 <body> 8 <p class="title"> 9 <b> 10 The Dormouse‘s story 11 </b> 12 </p> 13 <p class="story"> 14 Once upon a time there were three little sisters; and their names were 15 <a class="sister" href="http://example.com/elsie" id="link1"> 16 Elsie 17 </a> 18 , 19 <a class="sister" href="http://example.com/lacie" id="link2"> 20 Lacie 21 </a> 22 and 23 <a class="sister" href="http://example.com/tillie" id="link3"> 24 Tillie 25 </a> 26 ; and they lived at the bottom of a well. 27 </p> 28 <p class="story"> 29 ... 30 </p> 31 </body> 32 </html>
1.使用lxml.etree和lxml.cssselect解析html源码
1 from lxml import etree, cssselect 2 from cssselect import GenericTranslator, SelectorError 3 4 parser = etree.HTMLParser(remove_blank_text=True) 5 document = etree.fromstring(html_doc, parser) 6 7 # 使用CSS选择器 8 sel = cssselect.CSSSelector(‘p a‘) 9 results_sel_href = [e.get(‘href‘) for e in sel(document)] # 打印a标签的href属性 10 results_sel_text = [e.text for e in sel(document)] # 打印<a></a>之间的文本 11 print(results_sel_href) 12 print(results_sel_text) 13 14 # 使用CSS样式 15 results_css = [e.get(‘href‘) for e in document.cssselect(‘p a‘)] 16 print(results_css) 17 18 19 # 使用xpath 20 try: 21 expression = GenericTranslator().css_to_xpath(‘p a‘) 22 print(expression) 23 except SelectorError: 24 print(‘Invalid selector.‘) 25 26 results_xpath = [e.get(‘href‘) for e in document.xpath(expression)] # document.xpath(‘//a‘) 27 print(results_xpath)
2.cleaning up html
使用html清理器,可以移除一些嵌入的脚本、标签、CSS样式等html元素,这样可以提高搜索效率。
1 # cleaning up html 2 # 1.不使用Cleaner 3 from lxml.html.clean import Cleaner 4 html_after_clean = clean_html(html_doc) 5 print(html_after_clean) 6 # <div> 7 # The Dormouse‘s story 8 # <body> 9 # <p class="title"> 10 # <b> 11 # The Dormouse‘s story 12 # </b> 13 # </p> 14 # <p class="story"> 15 # Once upon a time there were three little sisters; and their names were 16 # <a class="sister" href="http://example.com/elsie" id="link1"> 17 # Elsie 18 # </a> 19 # , 20 # <a class="sister" href="http://example.com/lacie" id="link2"> 21 # Lacie 22 # </a> 23 # and 24 # <a class="sister" href="http://example.com/tillie" id="link3"> 25 # Tillie 26 # </a> 27 # ; and they lived at the bottom of a well. 28 # </p> 29 # <p class="story"> 30 # ... 31 # </p> 32 # </body> 33 # </div> 34 35 # 2.使用Cleaner 36 cleaner = Cleaner(style=True, links=True, add_nofollow=True, page_structure=False, safe_attrs_only=False) 37 html_with_cleaner = cleaner.clean_html(html_doc) 38 print(html_with_cleaner) 39 # <html> 40 # <head> 41 # <title> 42 # The Dormouse‘s story 43 # </title> 44 # </head> 45 # <body> 46 # <p class="title"> 47 # <b> 48 # The Dormouse‘s story 49 # </b> 50 # </p> 51 # <p class="story"> 52 # Once upon a time there were three little sisters; and their names were 53 # <a class="sister" href="http://example.com/elsie" id="link1"> 54 # Elsie 55 # </a> 56 # , 57 # <a class="sister" href="http://example.com/lacie" id="link2"> 58 # Lacie 59 # </a> 60 # and 61 # <a class="sister" href="http://example.com/tillie" id="link3"> 62 # Tillie 63 # </a> 64 # ; and they lived at the bottom of a well. 65 # </p> 66 # <p class="story"> 67 # ... 68 # </p> 69 # </body> 70 # </html>
二、Python lxml的实际应用
1.解析网易云音乐html源码
这是网易云音乐华语歌曲的分类链接http://music.163.com/#/discover/playlist/?order=hot&cat=华语&limit=35&offset=0,打开Chrome F12的Elements查看到页面源码,我们发现每页的歌单都在一个iframe浮窗上面,每首单曲的信息构成一个li标签,包含歌单图片、
歌单链接、歌单名称等。
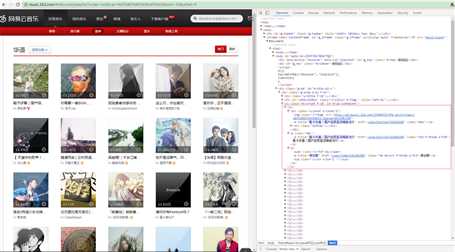
1 <ul class="m-cvrlst f-cb" id="m-pl-container"> 2 <li> 3 <div class="u-cover u-cover-1"> 4 <img class="j-flag" src="http://p1.music.126.net/FGe-rVrHlBTbnOvhMR99PQ==/109951162989189558.jpg?param=140y140" /> 5 <a title="【说唱】留住你一面,画在我心间" href="/playlist?id=832790627" class="msk"></a> 6 <div class="bottom"> 7 <a class="icon-play f-fr" title="播放" href="javascript:;" data-res-type="13" data-res-id="832790627" data-res-action="play"></a> 8 <span class="icon-headset"></span> 9 <span class="nb">1615</span> 10 </div> 11 </div> <p class="dec"> <a title="【说唱】留住你一面,画在我心间" href="/playlist?id=832790627" class="tit f-thide s-fc0">【说唱】留住你一面,画在我心间</a> </p> <p><span class="s-fc4">by</span> <a title="JediMindTricks" href="/user/home?id=17647877" class="nm nm-icn f-thide s-fc3">JediMindTricks</a> <sup class="u-icn u-icn-84 "></sup> </p> </li> 12 <li> 13 <div class="u-cover u-cover-1"> 14 <img class="j-flag" src="http://p1.music.126.net/If644P7ZrfPm_qcvtYyfzg==/18936888765458653.jpg?param=140y140" /> 15 <a title="鞋子好看|国产自赏摇滚噪音流行" href="/playlist?id=721462105" class="msk"></a> 16 <div class="bottom"> 17 <a class="icon-play f-fr" title="播放" href="javascript:;" data-res-type="13" data-res-id="721462105" data-res-action="play"></a> 18 <span class="icon-headset"></span> 19 <span class="nb">77652</span> 20 </div> 21 </div> <p class="dec"> <a title="鞋子好看|国产自赏摇滚噪音流行" href="/playlist?id=721462105" class="tit f-thide s-fc0">鞋子好看|国产自赏摇滚噪音流行</a> </p> <p><span class="s-fc4">by</span> <a title="原创君" href="/user/home?id=201586" class="nm nm-icn f-thide s-fc3">原创君</a> <sup class="u-icn u-icn-1 "></sup> </p> </li> 22 </ul>
开始解析html源码
首先实例化一个etree.HTMLParser对象,对html源码简单做下处理,创建cssselect.CSSSelector CSS选择器对象,搜索出无序列表ul下的所有li元素(_Element元素对象),再通过sel(document)遍历所有的_Element对象,使用find方法
find(self, path, namespaces=None) Finds the first matching subelement, by tag name or path. (lxml.ettr/lxml.cssselect 详细API请转义官网http://lxml.de/api/index.html)
通过xpath找到li的子元素img和a,通过_Element的属性attrib获取到属性字典,成功获取到歌单的图片链接,歌单列表链接和歌单名称。
1 from lxml import etree, cssselect 2 3 html = ‘‘‘上面提取的html源码‘‘‘ 4 parser = etree.HTMLParser(remove_blank_text=True) 5 document = etree.fromstring(html_doc, parser) 6 7 sel = cssselect.CSSSelector(‘#m-pl-container > li‘) 8 for e in sel(document): 9 img = e.find(‘.//div/img‘) 10 img_url = img.attrib[‘src‘] 11 a_msk = e.find(".//div/a[@class=‘msk‘]") 12 musicList_url = ‘http:/%s‘ % a_msk.attrib[‘href‘] 13 musicList_name = a_msk.attrib[‘title‘] 14 print(img_url,musicList_url,musicList_name)
以上是关于Python爬虫基础之lxml的主要内容,如果未能解决你的问题,请参考以下文章