深入消息队列MQ,看这篇就够了!
Posted 直争朝夕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入消息队列MQ,看这篇就够了!相关的知识,希望对你有一定的参考价值。
大厂面试爱问消息队列 MQ。
因为消息队列MQ,既是大型分布式系统不可缺少的中间件,也是高并发系统的基石中间件。
如果你想要快速掌握消息队列 MQ 最内核的知识,以及消息队列MQ的主流应用场景、主流产品与选型、设计一个消息队列MQ方法......
推荐查看并收藏本篇,基本上都讲齐全了。


下面我将通过图文并茂的方式,对消息队列MQ进行完整解析。
——不啰嗦了,下面进入正文!嘀嘀!准备上车了!!——
消息队列MQ概述
消息队列(Message Queue,简称MQ),指保存消息的一个容器,本质是个队列。
消息(Message)是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
下图便是消息队列的基本模型,向消息队列中存放数据的叫做生产者,从消息队列中获取数据的叫做消费者。


消息队列MQ应用场景
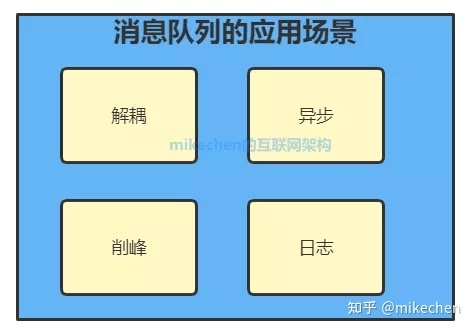
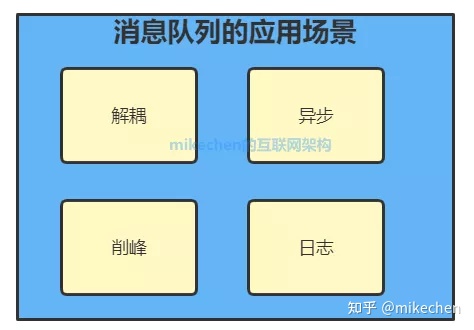
1.异步处理
消息队列的主要特点是异步处理,主要目的是减少请求响应时间,实现非核心流程异步化,提高系统响应性能。
举一个用户注册的例子,用户注册成功后,系统需要发送注短信注册成功通知,以及赠送注册成功的积分。
1)同步
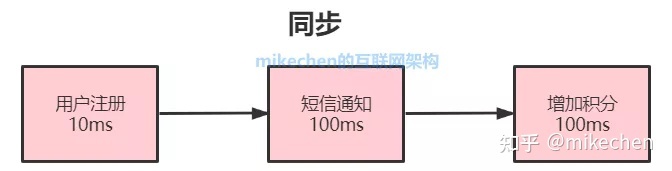
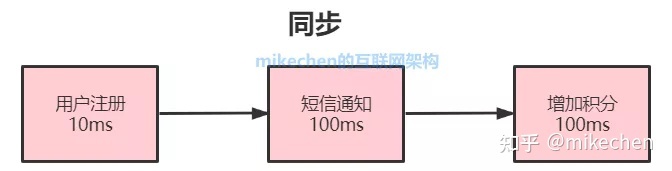
同步的总耗时:10ms+100ms+100ms=210ms
由于短信通知与增加积分为非核心流程,为了提升系统响应性能,从而我把它改造为异步。
2)异步
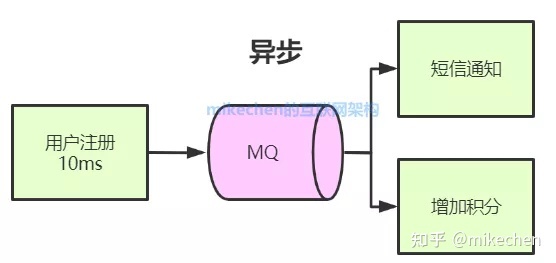
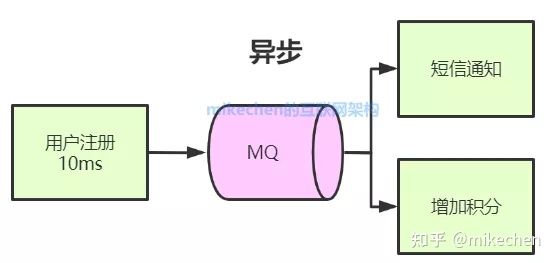
改造后就变成上图,之前需要等用户注册10ms+短信通知100ms+增加积分100ms才能返回,现在把短信通知和增加积分改为异步的形式,用户注册后写入消息10ms左右立即返回成功给客户端,无需等待耗时较久的同步(短信+积分)就可以返回,从而极大的提升了系统的吞吐量。
所以异步的典型场景就是将比较耗时而且不需要即时(同步)返回结果的操作,通过消息队列来实现异步化。
2.应用解耦
使用了消息队列后,只要保证消息格式不变,消息的发送方和接收方并不需要彼此联系,也不需要受对方的影响,即解耦。
每个成员不必受其他成员影响,可以更独立自主,只通过消息队列MQ来联系,典型的上下游解耦如下图所示:
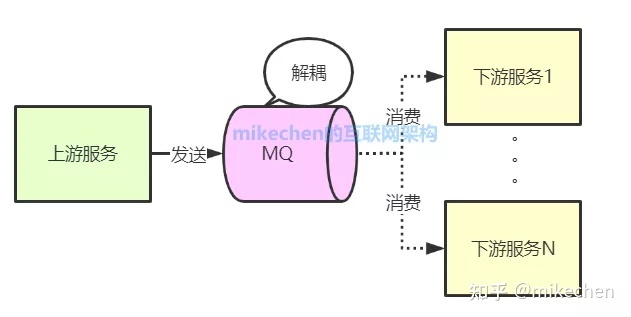
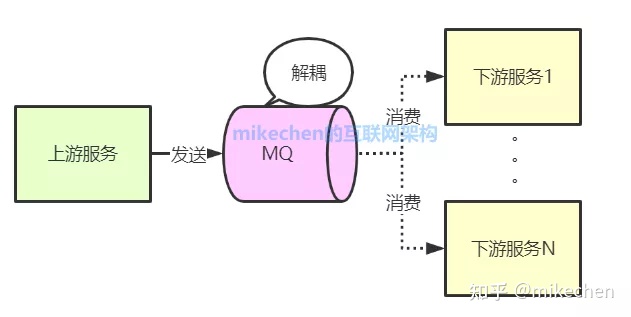
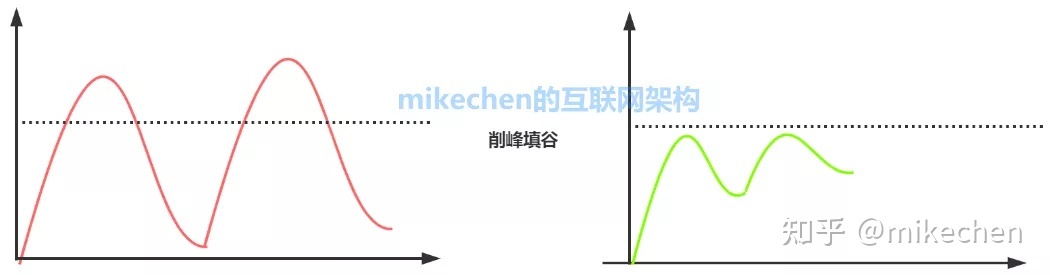
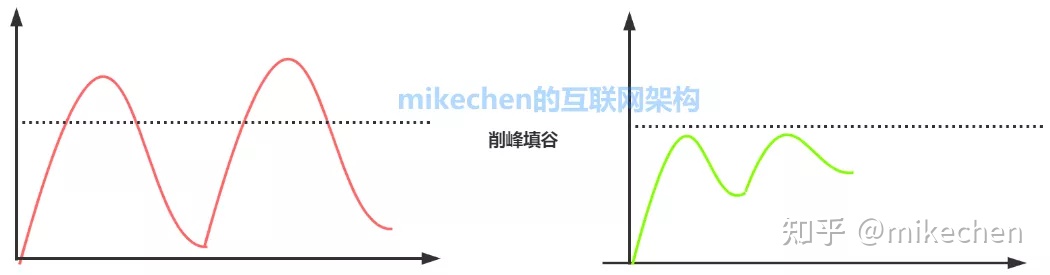
3.流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
这种场景中系统的峰值流量往往集中于一小段时间内,所以为了防止系统在短时间内的峰值流量冲垮,往往采用消息队列来削弱峰值流量,相当于消息队列做了一次缓冲。
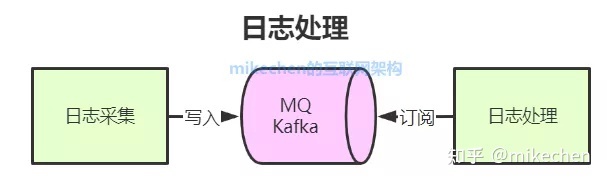
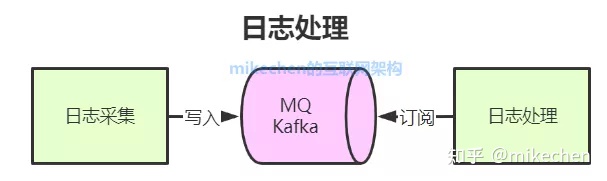
4日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。
消息队列MQ设计
1. 整体架构


上图为整体架构,会涉及三类角色:
1)Producer 消息生产者:负责产生和发送消息到 Broker;
2)Broker 消息处理中心:负责消息存储、确认、重试等,一般其中会包含多个 queue;
3)Consumer 消息消费者:负责从 Broker 中获取消息,并进行相应处理;
2.详细设计
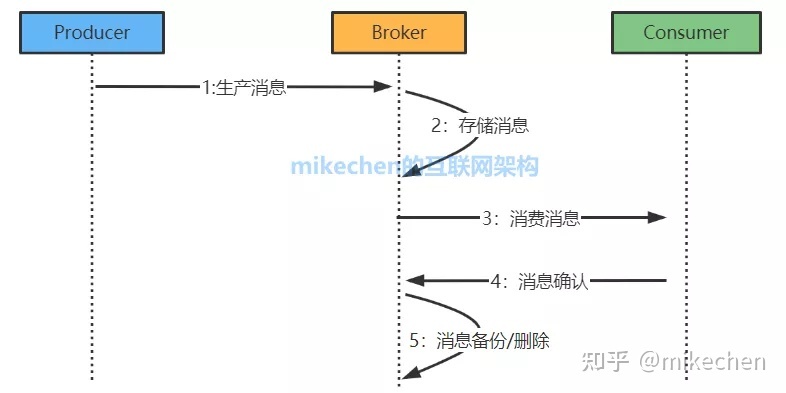
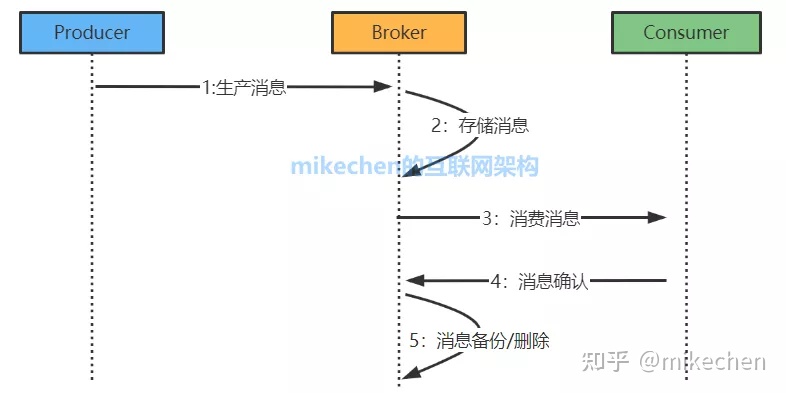
详细的流程如上图,producer发送给broker,broker发送给consumer,consumer回复消费确认,broker删除/备份消息等。
1)RPC 通信
图上的第一个步骤:Producer生产消息向Broker发送会涉及到通信的问题,同样Consumer 消费消息也会涉及到通信的问题。
上图中的Producer,Broker,Consumer最后就通过RPC将数据流串起来了,所以需要解决通信的问题。
你可以基于Netty 来做底层通信,用 Zookeeper、Euraka 等来做注册中心,然后自定义一套新的通信协议。
也可以直接利用成熟的 RPC 框架 Dubbo 或者 Thrift 实现即可,这样不需要考虑服务注册与发现、负载均衡、通信协议、序列化方式等一系列问题了。
2)Broker存储
图上第二个步骤,消息到达服务端后需要存储到Broker。
大家关注的流量削峰、最终一致性等需求都是需要Broker先存储下来,然后选择时机投递,这才达到流量削峰、泄洪的目的,所以Broker一个非常重要的功能就是存储。
存储可以做成很多方式,比如存储在内存里,存储在分布式KV里,存储在磁盘里,存储在数据库里等等,存储的选型需要综合考虑性能/高可用和开发维护成本等诸多因素。
目前主流的方案:追加写日志文件(数据部分) + 索引文件的方式,索引设计上可以考虑稠密索引或者稀疏索引,查找消息可以利用跳转表、二份查找等,还可以通过操作系统的页缓存、零拷贝等技术来提升磁盘文件的读写性能。
3)消费模型
图上第三个步骤,消息到达Broker后,最终还是需要Consumer去消费消息,这里就会涉及到到消费模型。
这里的消费模型,目前主要就两种:单播和广播。所谓单播,就是点到点;而广播,是一点对多点。
详细的单播和广播消费模型,下面我会图文详解。
4)高级特性
图上第四个步骤,如果Consumer端把消息消费了,除了需要消息确认,还会涉及到比如:重复消息、顺序消息、消息延迟、事务消息等需要考虑的高级特性。
消息队列MQ模型
消息队列MQ主要包含两种模型:点对点与发布订阅两种模型。
1.点对点模型
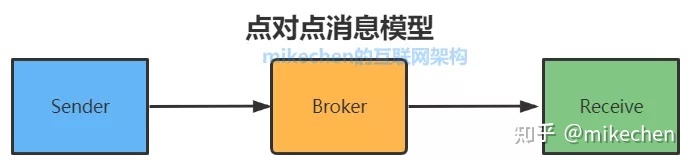
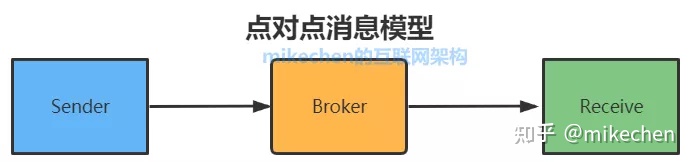
点对点模用于 消息生产者 和 消息消费者 之间 点到点 的通信,包含三个角色:
- 消息队列(Queue)
- 发送者(Sender)
- 接收者(Receiver)
每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,可以放在 内存 中也可以 持久化,直到他们被消费或超时。
特点
- 每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者之间在时间上没有依赖性
- 接收者在成功接收消息之后需向队列应答成功
2.发布订阅消息模型Topic
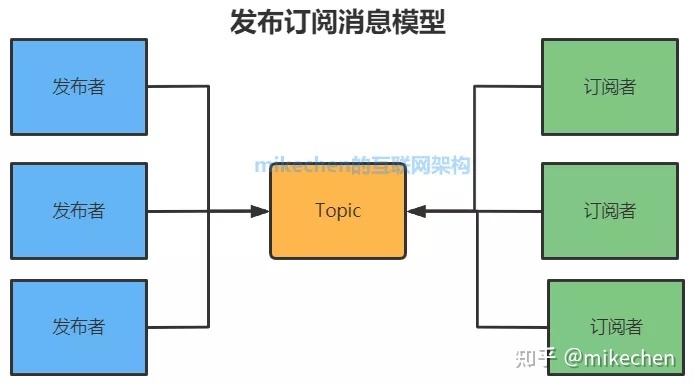
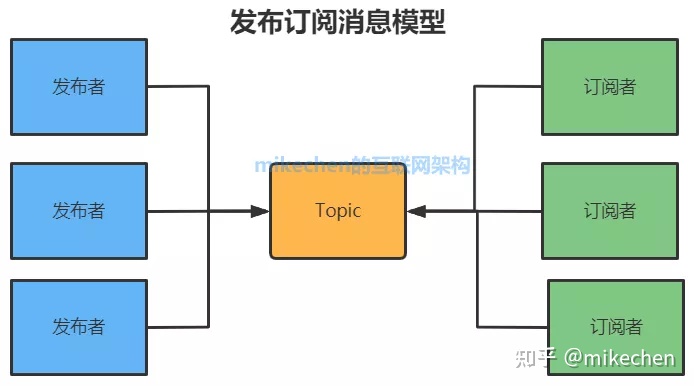
发布订阅模型包含三个角色:
- 主题(Topic)
- 发布者(Publisher)
- 订阅者(Subscriber)
多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
特点
- 每个消息可以有多个消费者:和点对点方式不同,发布消息可以被所有订阅者消费
- 发布者和订阅者之间有时间上的依赖性。
- 针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者必须保持运行的状态。
消息队列MQ产品选型
1.ActiveMQ


ActiveMQ官网地址:http://activemq.apache.org
Apache出品,最早使用的消息队列产品,时间比较长了,最近版本更新比较缓慢,性能在万级/秒。
2.RabbitMQ


RabbitMQ官网地址:http://www.rabbitmq.com
RabbitMQ是erlang语言开发,结合erlang语言本身的并发优势,支持很多的协议:AMQP,XMPP, SMTP, STOMP,性能在万级/秒,其整体架构图如下所示:
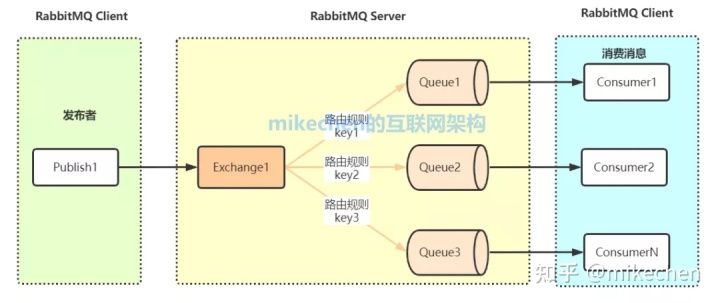

3.Kafka


Kafka官网地址:http://kafka.apache.org
Kafka是由Apache软件基金会开发的一个开源消息系统项目,由Scala写成。Kafka最初是由LinkedIn开发,并于2011年初开源。Kafka是一个分布式的、分区的、多复本的日志提交服务,性能在百万级/秒,其整体架构图如下所示:
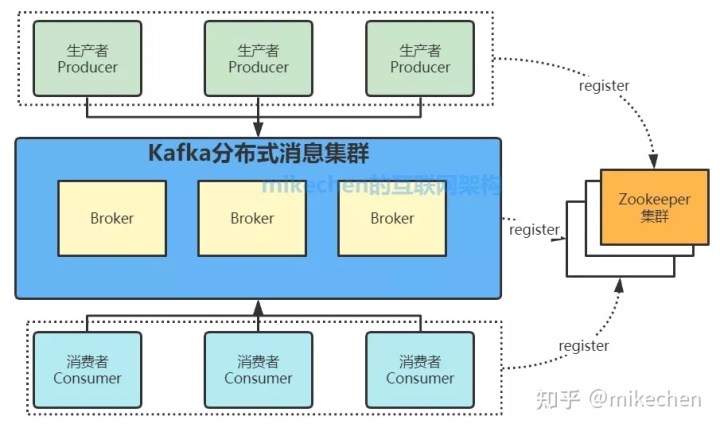
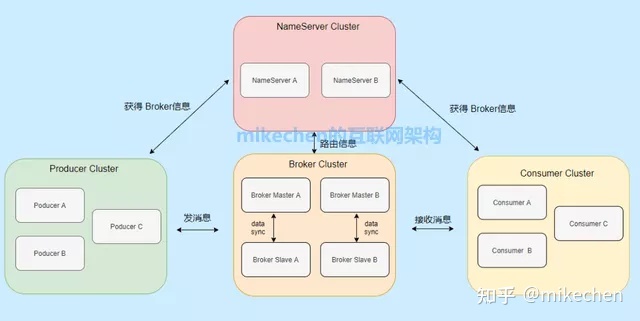
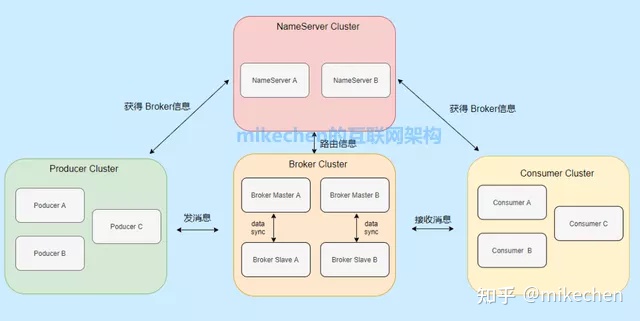
4.RocketMQ


RocketMQ官网地址:http://rocketmq.apache.org
阿里开源的消息中间件,纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点,参考Kafka而设计的,性能在十万级/秒,其整体架构图如下所示:
5.Pulsar


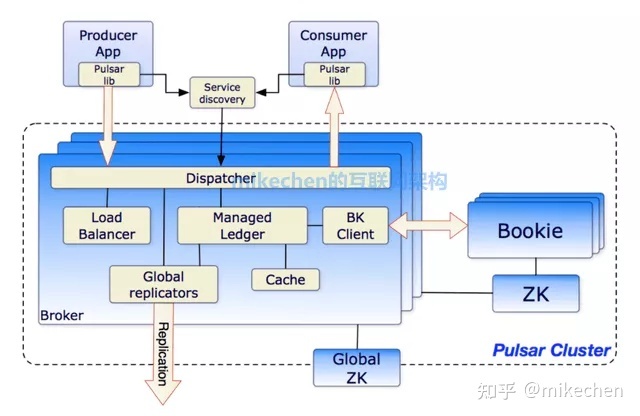
Pulsar官网地址:http://pulsar.apache.org
Apache Pulsar是Apache软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算最佳解决方案,其整体架构图如下所示:
6.消息队列选型
广泛来说,电商、金融等对事务性要求很高的,可以考虑RocketMQ,技术挑战不是特别高,用 RabbitMQ 是不错的选择,如果是大数据领域的实时计算、日志采集等场景可以考虑 Kafka。
写在最后
上面主要从消息队列MQ的核心设计、应用场景、主流产品等来讲解,目的是让大家对消息队列 MQ 有一个清晰的全局认识,把消息队列MQ的体系脉络给建立起来,大方向上搞明白很关键!
以上就是消息队列MQ的介绍,建议收藏,以便时常温故。点击我的头像,主页get更多的【视频版详解】及【架构技术连载】。
---END--
我是Mike,10余年BAT一线大厂架构技术倾囊相授。
Mike分享的每篇深度技术文,都是花上2-5天时间精心创作的。大家看了如果觉得还行,谢谢顺手【点赞+收藏+转发】一键三连支持下。
以上是关于深入消息队列MQ,看这篇就够了!的主要内容,如果未能解决你的问题,请参考以下文章