Python 爬虫-Scrapy爬虫框架
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫-Scrapy爬虫框架相关的知识,希望对你有一定的参考价值。
2017-07-29 17:50:29
Scrapy是一个快速功能强大的网络爬虫框架。
Scrapy不是一个函数功能库,而是一个爬虫框架。爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
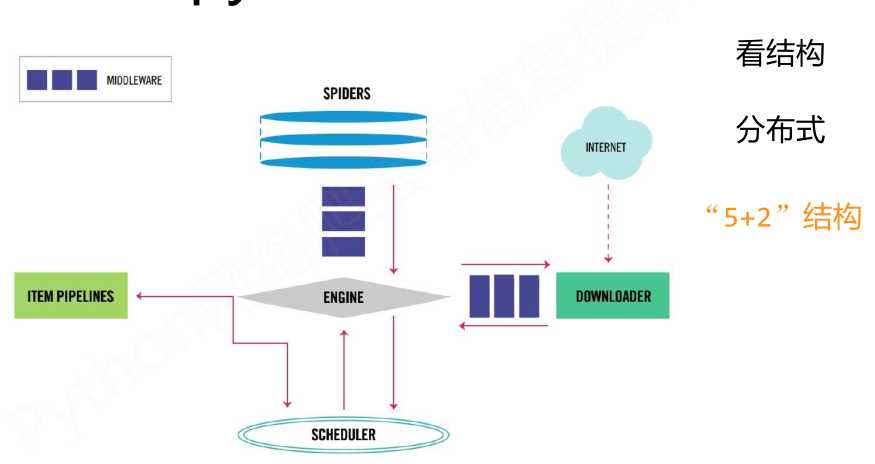
一、Scrapy框架介绍
- 5+2结构,5个主要模块加2个中间件。
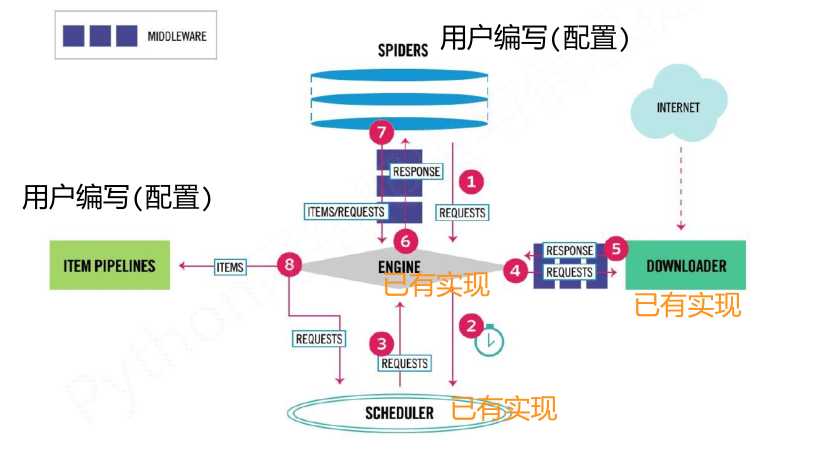
(1)Engine:控制所有模块之间的数据流;根据条件触发事件。不需要用户修改
(2)Downloader:根据请求下载网页。不需要用户修改
(3)Scheduler:对所有爬取请求进行调度管理。不需要用户修改
(4)Downloader Middleware:实施Engine、Scheduler和Downloader之间进行用户可配置的控制,进行修改、丢弃、新增请求或响应。用户可以编写配置代码
(5)Spider:解析Downloader返回的响应(Response);产生爬取项(scraped item);产生额外的爬取请求(Request)。需要用户编写配置代码
(6)Item Pipelines:以流水线方式处理Spider产生的爬取项;由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型;可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库。需要用户编写配置代码
(7)Spider Middleware:对请求和爬取项的再处理,进行修改、丢弃、新增请求或爬取项。用户可以编写配置代码
- 流程介绍
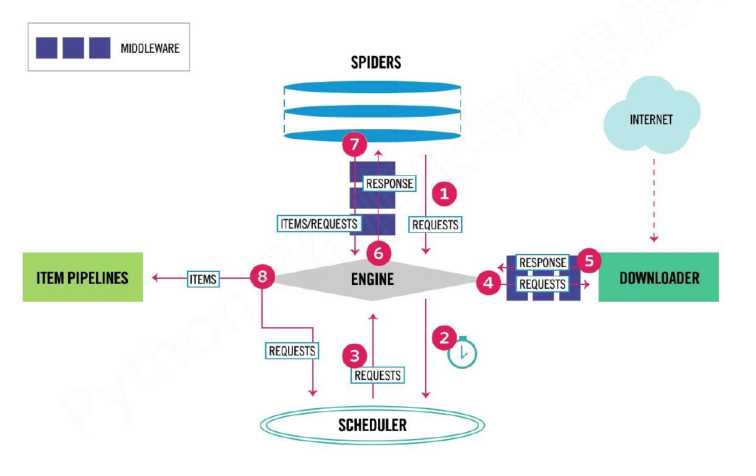
数据流的三个路径--1:
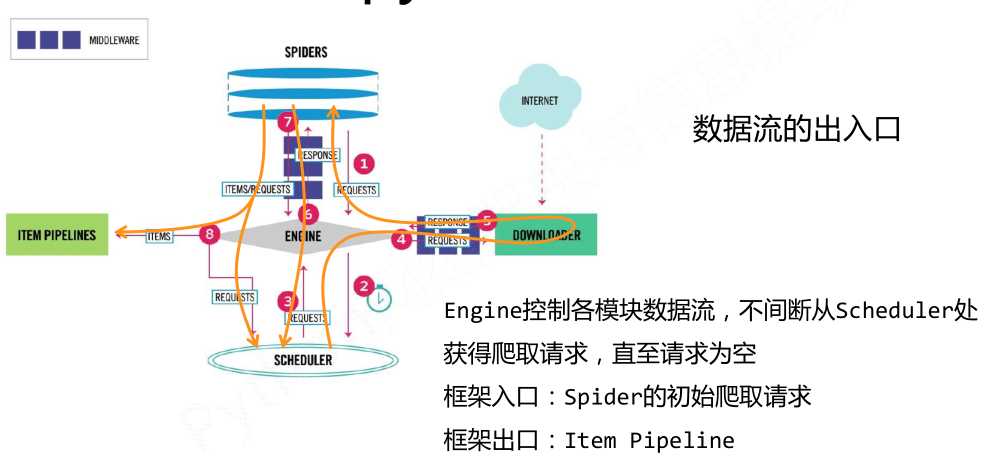
1 Engine从Spider处获得爬取请求(Request)
2 Engine将爬取请求转发给Scheduler,用于调度
数据流的三个路径--2:
3 Engine从Scheduler处获得下一个要爬取的请求
4 Engine将爬取请求通过中间件发送给Downloader
5 爬取网页后,Downloader形成响应(Response,通过中间件发给Engine
6 Engine将收到的响应通过中间件发送给Spider处理
数据流的三个路径--3:
7 Spider处理响应后产生爬取项(scraped Item和新的爬取请求(Requests)给Engine
8 Engine将爬取项发送给Item Pipeline(框架出口)
9 Engine将爬取请求发送给Scheduler
- 数据流的出入口以及用户需要配置的部分
二、Scrapy库 和 Requests库的比较
相同点:
- 两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
- 两者可用性都好,文档丰富,入门简单
- 两者都没有处理js、提交表单、应对验证码等功能(可扩展)
区别:
- 非常小的需求,requests库
- 不太小的需求,Scrapy框架,能够持续的爬取信息,并积累成自己的爬取库
- 定制程度很高的需求(不考虑规模),自搭框架,requests > Scrapy

以上是关于Python 爬虫-Scrapy爬虫框架的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫教程-31-创建 Scrapy 爬虫框架项目