机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法相关的知识,希望对你有一定的参考价值。
(一)认识回归
回归是统计学中最有力的工具之中的一个。
机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型、连续性而定义的。
顾名思义。分类算法用于离散型分布预測,如前面讲过的KNN、决策树、朴素贝叶斯、adaboost、SVM、Logistic回归都是分类算法。回归算法用于连续型分布预測。针对的是数值型的样本,使用回归。能够在给定输入的时候预測出一个数值。这是对分类方法的提升,由于这样能够预測连续型数据而不不过离散的类别标签。
回归的目的就是建立一个回归方程用来预測目标值。回归的求解就是求这个回归方程的回归系数。预測的方法当然十分简单,回归系数乘以输入值再所有相加就得到了预測值。
1,回归的定义
回归最简单的定义是,给出一个点集D,用一个函数去拟合这个点集。而且使得点集与拟合函数间的误差最小,假设这个函数曲线是一条直线,那就被称为线性回归,假设曲线是一条二次曲线,就被称为二次回归。
2,多元线性回归
假定预測值与样本特征间的函数关系是线性的,回归分析的任务,就在于依据样本X和Y的观察值。去预计函数h,寻求变量之间近似的函数关系。定义:
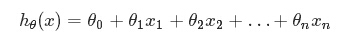
当中,n = 特征数目;
为了方便。记x0= 1。则多变量线性回归能够记为:
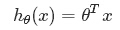 。(θ、x都表示(n+1,1)维列向量)
。(θ、x都表示(n+1,1)维列向量)
Note:注意多元和多次是两个不同的概念。“多元”指方程有多个參数。“多次”指的是方程中參数的最高次幂。多元线性方程是如果预測值y与样本全部特征值符合一个多元一次线性方程。
3,广义线性回归
用广义的线性函数:
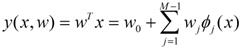
wj是系数,w就是这个系数组成的向量。它影响着不同维度的Φj(x)在回归函数中的影响度,Φ(x)是能够换成不同的函数。这种模型我们觉得是广义线性模型,Φ(x)=x时就是多元线性回归模型。
(二)线性回归的求解
说到回归,经常指的也就是线性回归。因此本文阐述的就是多元线性回归方程的求解。如果有连续型值标签(标签值分布为Y)的样本,有X={x1,x2,...,xn}个特征,回归就是求解回归系数θ=θ0,
这里的误差是指预測y值和真实y值之间的差值,使用该误差的简单累加将使得正差值和负差值相互抵消。所以採用平方误差(最小二乘法)。
平方误差能够写做:
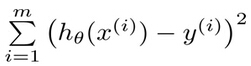
至于为何採用最小误差平方和来求解,其统计学原理可參考“对线性回归、逻辑回归、各种回归的概念学习”的“深入线性回归”一节。
在数学上。求解过程就转化为求一组θ值使求上式取到最小值,那么求解方法有梯度下降法、Normal Equation等等。梯度下降有例如以下特点:须要预先选定步长a、须要多次迭代、特征值须要Scaling(统一到同一个尺度范围)。因此比較复杂。另一种不须要迭代的求解方式--Normal Equation,简单、方便、不须要Feature Scaling。Normal Equation方法中须要计算X的转置与逆矩阵,计算量非常大,因此特征个数多时计算会非常慢,仅仅适用于特征个数小于100000时使用;当特征数量大于100000时使用梯度法。另外,当X不可逆时就有岭回归算法的用武之地了。
以下就概括一下经常使用的几种求解算法。
1。梯度下降法(Gradient Descent)
依据平方误差。定义该线性回归模型的损耗函数(Cost Function)为:
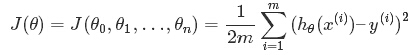 ,(系数是为了方便求导展示)
,(系数是为了方便求导展示)
线性回归的损耗函数的值与回归系数θ的关系是碗状的。仅仅有一个最小点。线性回归的求解过程如同Logistic回归,差别在于学习模型函数hθ(x)不同,梯度法具体求解过程參考“机器学习经典算法具体解释及Python实现---Logistic回归(LR)分类器”。
2,Normal Equation(也叫普通最小二乘法)
Normal Equation算法也叫做普通最小二乘法(ordinary least squares),其特点是:给定输人矩阵X,假设XTX的逆存在并能够求得的话。就能够直接採用该方法求解。
其求解理论也十分简单:既然是是求最小误差平方和。另其导数为0就可以得出回归系数。
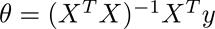
矩阵X为(m,n+1)矩阵(m表示样本数、n表示一个样本的特征数),y为(m。1)列向量。
上述公式中包括XTX, 也就是须要对矩阵求逆,因此这个方程仅仅在逆矩阵存在的时候适用。然而。矩阵的逆可能并不存在,后面“岭回归”会讨论处理方法。
3。局部加权线性回归
线性回归的一个问题是有可能出现欠拟合现象。由于它求的是具有最小均方误差的无偏预计。显而易见,假设模型欠拟合将不能取得最好的预測效果。所以有些方法同意在预计中引人一些偏差,从而减少预測的均方误差。当中的一个方法是局部加权线性回归(LocallyWeightedLinearRegression, LWLR )。在该算法中,我们给待预測点附近的每一个点赋予一定的权重.于是公式变为:

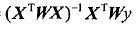 。W是(m,m)矩阵,m表示样本数。
。W是(m,m)矩阵,m表示样本数。
LWLR使用 “核”(与支持向量机中的核类似)来对附近的点赋予更高的权重。
核的类型能够自由选择,最经常使用的核就是高斯核,高斯核相应的权重例如以下:

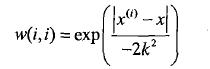 ,k须要优化选择.
,k须要优化选择.
局部加权线性回归也存在一个问题,即添加了计算量,由于它对每一个点做预測时都必须使用整个数据集。而不是计算出回归系数得到回归方程后代入计算就可以。因此该算法不被推荐。
4,岭回归(ridge regression)和缩减方法
当数据的样本数比特征数还少时候。矩阵XTX的逆不能直接计算。即便当样本数比特征数多时,XTX 的逆仍有可能无法直接计算。这是由于特征有可能高度相关。这时能够考虑使用岭回归,由于当XTX 的逆不能计算时。它仍保证能求得回归參数。简单说来。岭回归就是对矩阵XTX进行适当的修正,变为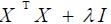 (I是单位矩阵,对角线为1,其它为0)从而使得矩阵非神秘,进而能对式子求逆。在这样的情况下,回归系数的计算公式将变成:
(I是单位矩阵,对角线为1,其它为0)从而使得矩阵非神秘,进而能对式子求逆。在这样的情况下,回归系数的计算公式将变成:

为了使用岭回归和缩减技术,首先须要对特征做标准化处理,使各特征值的取值尺度范围同样,从而保证各特征值的影响力是同样的。
怎样设置 λ 的值?通过选取不同的λ 来反复上述測试过程。终于得到一个使预測误差最小的λ 。可通过交叉验证获取最优值--在測试数据上。使误差平方和最小。
岭回归最先用来处理特征数多于样本数的情况,如今也用于在预计中加人偏差。从而得到更好的预计。其实,上述公式是在最小平方误差和公式里引入了每一个特征的惩处因子得到,为的是防止过度拟合(过于复杂的模型),在损失函数里添加一个每一个特征的惩处因子。这就是线性回归的正则化(參考“Coursera公开课笔记: 斯坦福大学机器学习第七课“正则化(Regularization)”)。
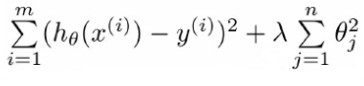
Note:θ0是一个常数,x0=1是固定的,那么θ0不须要惩处因子,岭回归公式中的I的第一个元素要为0。
这里通过引入λ来限制了全部误差平方之和,通过引人该惩处项。能够降低不重要的參数,这个技术在统计学中也叫做缩减(shrinkage )。缩减方法能够去掉不重要的參数,因此能更好地理解数据。此外,与简单的线性回归相比,缩减法能取得更好的预測效果,缩减法还能够看做是对一个数据模型的拟合採取了偏差(预測值与真实值差距)、方差(不同预測模型间的差距)折中方案,添加偏差的同一时候降低方差。
偏差方差折中是一个重要的概念。能够帮助我们理解现有模型并做出改进,从而得到更好的模型。岭回归是缩减法的一种,相当于对回归系数的大小施加了限制。
另一种非常好的缩减法是lasso。lasso难以求解,但能够使用计算简便的逐步线性回归方法来求得近似结果。另一些其它缩减方法。如lasso、LAR、PCA回归以及子集选择等。与岭回归一样,这些方法不仅能够提高预測精确率,并且能够解释回归系数。
5,回归模型性能度量
数据集上计算出的回归方程并不一定意味着它是最佳的。能够便用预測值yHat和原始值y的相关性来度量回归方程的好坏。
相关性取值范围0~1,值越高说明回归模型性能越好。
线性回归是如果值标签与特征值之间的关系是线性的。但有些时候数据间的关系可能会更加复杂。使用线性的模型就难以拟合,就须要引入多项式曲线回归(多元多次拟合)或者其它回归模型。如回归树。
(三)线性回归的Python实现
本线性回归的学习包中实现了普通最小二乘和岭回归算法,因梯度法和Logistic Regression差点儿同样。也没有特征数>10000的样本測试运算速度,所以没有实现。为了支持多种求解方法、也便于扩展其它解法,linearRegress对象採用Dict来存储相关參数(求解方法为key,回归系数和其它相关參数的List为value)。
比如岭回归算法在LRDict中的key=‘ridge’,value=[ws, lamba,xmean,var, ymean]。由于岭回归模型训练和预測中须要对样本进行feature scaling。所以才须要存储xmean,var, ymean。linearRegress对象的属性如其__init__函数所看到的:
- class linearRegress(object):
- def __init__(self,LRDict = None, **args):
- ‘‘‘currently support OLS, ridge, LWLR
- ‘‘‘
- obj_list = inspect.stack()[1][-2]
- self.__name__ = obj_list[0].split(‘=‘)[0].strip()
- if not LRDict:
- self.LRDict = {}
- else:
- self.LRDict = LRDict
- #to Numpy matraix
- if ‘OLS‘ in self.LRDict:
- self.LRDict[‘OLS‘] = mat(self.LRDict[‘OLS‘])
- if ‘ridge‘ in self.LRDict:
- self.LRDict[‘ridge‘][0] = mat(self.LRDict[‘ridge‘][0])
- self.LRDict[‘ridge‘][2] = mat(self.LRDict[‘ridge‘][2])
- self.LRDict[‘ridge‘][3] = mat(self.LRDict[‘ridge‘][3])
- self.LRDict[‘ridge‘][4] = mat(self.LRDict[‘ridge‘][4])
线性回归模型Python学习包下载地址为:
Machine Learning Linear Regression-线性回归
(四)应用和模型调优
对于须要依据一些特征的组合来预測一个值(如预測房价、菜价等)且预測值和特征组合间的关系是线性时既能够採用线性回归建立预測模型。通过机器学习算法建立起一个模型之后就须要在使用中不断的调优和修正,对于线性回归来说。最佳模型就是取得预測偏差和模型方差之间的平衡(高偏差就是欠拟合,高方差就是过拟合)。线性回归模型中模型调优和修正的方法包含:
- 获取很多其它的训练样本 - 解决高方差
- 尝试使用更少的特征的集合 - 解决高方差
- 尝试获得其它特征 - 解决高偏差
- 尝试加入多项组合特征 - 解决高偏差
- 尝试减小
- 尝试添加
具体的阐述能够參考“斯坦福大学机器学习第十课“应用机器学习的建议”
參考:
Coursera公开课笔记: 斯坦福大学机器学习第七课“正则化(Regularization)
本文作者Adan,来源于:机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法。
转载请注明出处。
以上是关于机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法的主要内容,如果未能解决你的问题,请参考以下文章
机器学习经典分类算法 —— k-均值算法(附python实现代码及数据集)