python函数:函数进阶
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python函数:函数进阶相关的知识,希望对你有一定的参考价值。
昨天说了函数的一些最基本的定义,今天我们继续研究函数。今天主要研究的是函数的命名空间、作用域、函数名的本质、闭包等等
预习:


1、写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作 2、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。 3、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 dic = {"k1": "v1v1", "k2": [11,22,33,44]} PS:字典中的value只能是字符串或列表
一、命名空间
命名空间的本质:存放名字与值的绑定关系
命名空间
局部命名空间
全局命名空间
内置命名空间
*内置命名空间中存放了python解释器为我们提供的名字:input,print,str,list,tuple...它们都是我们熟悉的,拿过来就可以用的方法。
三种命名空间之间的加载与取值顺序:
加载顺序:内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
取值:
在局部调用:局部命名空间->全局命名空间->内置命名空间
x = 1 def f(x): print(x) print(10)
在全局调用:全局命名空间->内置命名空间
x = 1 def f(x): print(x) f(10) print(x)
print(max)
二、作用域
为什么要有作用域的概念:
为了函数内的变量不会影响到全局
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
作用域:
小范围的可以用大范围的但是大范围的不能用小范围的
范围从大到小(图)

在小范围内,如果要用一个变量,是当前这个小范围有的,就用自己的如果在小范围内没有,就用上一级的,上一级没有就用上上一级的,以此类推。如果都没有,报错
globals和locals方法
a = 20 b = 50 def func(): x = 1 y = 2 print(globals()) #全局作用域中的名字 print(locals()) #局部作用域中的名字 func() print(globals()) #全局作用域中的名字 print(locals()) #全局的局部还是全局
global关键字
a = 10 def func(): a = 20 def func1(): global a #改变全局变量 a = 20 print(a) func() print(a) func1() print(a)
三、函数的嵌套和作用域链
函数的嵌套调用
def max2(x,y): m = x if x>y else y return m def max4(a,b,c,d): res1 = max2(a,b) res2 = max2(res1,c) res3 = max2(res2,d) return res3 max4(23,-7,31,11)
函数的嵌套定义
def f1(): print("in f1") def f2(): print("in f2") f2() f1()
def f1(): def f2(): def f3(): print("in f3") print("in f2") f3() print("in f1") f2() f1()
函数的作用域链
def f1(): a = 1 def f2(): print(a) f2() f1()
def f1(): a = 1 def f2(): def f3(): print(a) f3() f2() f1()
def f1(): a = 1 def f2(): a = 2 f2() print(‘a in f1 : ‘,a) f1()
nolocal关键字
1、外部必须有这个变量
2、在内部函数声明nonlocal变量之前不能再出现同名变量
3、内部修改这个变量如果想在外部有这个变量的第一层函数中生效
def f(): a = 3 def f1(): a = 1 def f2(): nonlocal a #仅改变外一层变量值 a = 2 f2() print(‘a in f1 : ‘, a) f1() print(‘a in f : ‘,a) f()
四、函数名的本质
函数名本质上就是函数的内存地址
1、可以被引用
def func(): print(‘in func‘) f = func print(f)
2、可以被当作容器类型的元素
def f1(): print(‘f1‘) def f2(): print(‘f2‘) def f3(): print(‘f3‘) l = [f1,f2,f3] d = {‘f1‘:f1,‘f2‘:f2,‘f3‘:f3} #调用 l[0]() d[‘f2‘]()
3、可以当作函数的参数和返回值
def func(): print(‘func‘) def func2(f): f() func2(func)
def func(): def func2(): print(‘hello‘) return func2 f2 = func() f2() f = func
第一类对象(first-class object)指
1、可在运行期创建
2、可用作函数参数或返回值
3、可存入变量的实体。
不明白就记住一句话,就当普通变量用
五、闭包
闭包函数:内部函数,包含了对外部作用域中变量的引用,内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数
#函数内部定义的函数称为内部函数
闭包
1、闭 内部的函数
2、包 包含了对外部函数作用域中变量的引用
def func(): name = ‘eva‘ def inner(): print(name)
def func(): name = ‘eva‘ def inner(): print(name) return inner f = func() f()
判断闭包函数的方法__closure__
#输出的__closure__有cell元素 :是闭包函数 def func(): name = ‘eva‘ def inner(): print(name) print(inner.__closure__) return inner f = func() f() #输出的__closure__为None :不是闭包函数 name = ‘egon‘ def func2(): def inner(): print(name) print(inner.__closure__) return inner f2 = func2() f2()
def wrapper(): money = 1000 def func(): name = ‘eva‘ def inner(): print(name,money) return inner return func f = wrapper() i = f() i()
from urllib.request import urlopen def index(): url = "http://www.cnblogs.com/liluning/" def get(): return urlopen(url).read() return get cnblogs = index() content = cnblogs() print(content)
总结图:
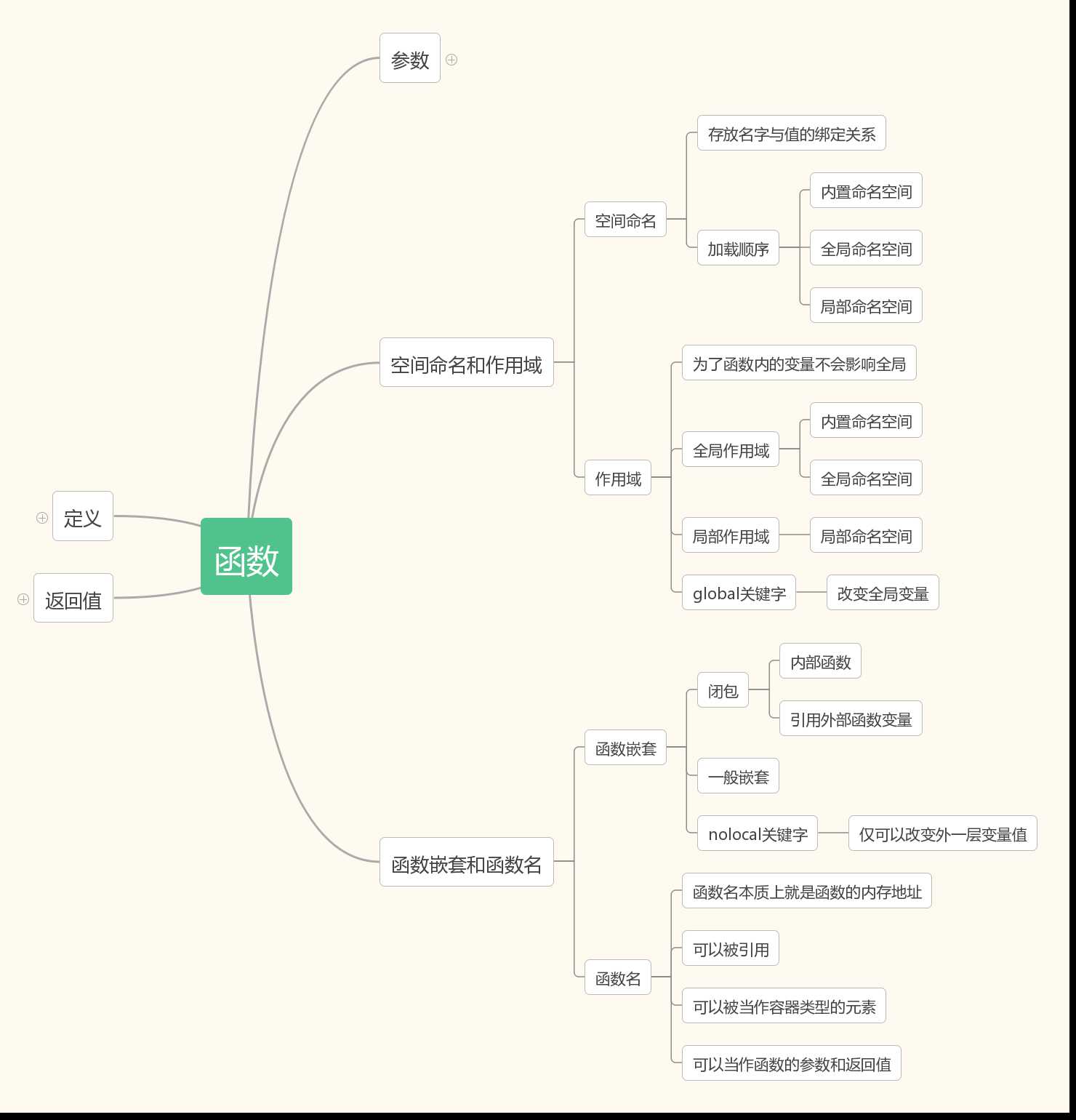
预习答案
import os def file_l(demo,i,j) : ‘‘‘ 用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作 :param demo:传入的文件 :param i:需要修改的字符串 :param j:要改变后的字符串 :return:返回源文件和改后文件的句柄 ‘‘‘ with open(demo, ‘r‘, encoding=‘utf-8‘) as read_f, open("demo1.py", ‘w‘, encoding=‘utf-8‘) as write_f : for line in read_f : write_f.write(line.replace(i, j)) return read_f,write_f file_l1,file_l2 = file_l("demo.py","def","hahaha") os.remove(file_l1.name) os.rename(file_l2.name, file_l1.name) def space_l(str) : ‘‘‘ 检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。 :param str: 传入数据 :return: 布尔值 ‘‘‘ for i in str : if i.isspace() : return False return True msg = "hello world!" print(space_l(msg)) def length(dic) : ‘‘‘ 检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容, 并将新内容返回给调用者。 :param dic: :return: ‘‘‘ for i in dic : if len(dic[i]) > 2 : dic[i] = dic[i][0:2] return dic dic = {"k1": "v1v1", "k2": [11,22,33,44]} length(dic) print(dic)
小知识点:
#三元运算 # a = 20 # b = 10 # if a > b: # c = 5 # else: # c = 10 #if条件成立的结果 if 条件 else else条件成立的结果 # a = 20 # b = 10 # c = 5 if a>b else 10 # print(c)
课外娱乐:
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren‘t special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you‘re Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it‘s a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let‘s do more of those!
在python之禅中提到过:命名空间是一种绝妙的理念,让我们尽情的使用发挥吧!
以上是关于python函数:函数进阶的主要内容,如果未能解决你的问题,请参考以下文章