Python 爬虫|深入请求:http协议以及fiddler的使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫|深入请求:http协议以及fiddler的使用相关的知识,希望对你有一定的参考价值。
对于一个URL https://zhuanlan.zhihu.com/xmucpp
(1)首先浏览器解析出主机名:http://zhuanlan.zhihu.com
(2)浏览器搜索出相应主机的ip地址(DNS)
(3)浏览器解析出相应的端口号
(4)建立与主机及特定端口的联系
(5)发送请求报文(记录请求行为的一些信息及要求)
(6)获得响应报文(包括你在浏览器上看到的信息)
(7)关闭连接
现在来看一看报文的具体结构,对于构造请求行为中的headers很有帮助,只需要大概了解就好,不需要特别深入~~
1)start lines:请求报文的起始行,或称为请求行。包含了一个方法和一个请求的URL。这个方法描述了服务器应该执行的操作,请求URL描述了要对哪个资源执行这个方法。请求行中还包含HTTP的版本,用来告知服务器,客户端使用的是哪种HTTP版本
请求方法 描述
GET 从服务器获取一份文档
HEAD 只从服务器获取文档的首部
POST 向服务器发送需要处理的数据
PUT 将请求的主体部分存储在服务器上
TRACE 对可能经过代理服务器传送到服务器上去的报文进行跟踪
OPTIONS 决定可以在服务器上执行哪些方法
DELETE 从服务器上删除一份文档
其中最常见的还是get和post(对应pythonrequests库中的requests.post, requests.get)
相信 大家对上图一定不陌生吧~对,这个404就是状态码
状态码是用来反映请求状态的数字,在python中可以用requests库中的status——code来实现
整体范围 已定义范围 分类
100-199 100-101 信息提示
200-299 200-206 成功
300-399 300-305 重定向(需要重新寻找URL)
400-499 400-415 客户端错误(构造URL或者posted data错误,被反爬等
500-599 500-505 服务器错误或者你自己的代理网关出现问题
2)header,仅列出一些与爬虫相关的参数(用于应对反爬),大部分可以直接复制:
host:提供了主机名及端口号
Referer 提供给服务器客户端从那个页面链接过来的信息(有些网站会据此来反爬)
Origin:Origin字段里只包含是谁发起的请求,并没有其他信息。跟Referer不一样的 是,Origin字段并没有包含涉及到用户隐私的URL路径和请求内容,这个尤其重要。
并且Origin字段只存在于POST请求,而Referer则存在于所有类型的请求。
User agent: 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬)
proxies: 代理,一些网站会根据ip访问的频率次数等选择封ip
cookie: 特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造(python中 的一些库也可以实现)
Accept首部为客户端提供了一种将其喜好和能力告知服务器的方式,包括他们想要什么, 可以使用什么,以及最重要的,他们不想要什么。这样服务器就可以根据这些额外信息,对要发送的内容做出更明智的决定。
首部 描述
Accept 告诉服务器能够发送哪些媒体类型
Accept-Charset 告诉服务器能够发送哪些字符集
Accept-Encoding 告诉服务器能够发送哪些编码方式(最常见的是utf-8)
Accept-Language 告诉服务器能够发送哪些语言
Cache-control: 这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令
Public 所有内容都将被缓存(客户端和代理服务器都可缓存)
Private 内容只缓存到私有缓存中(仅客户端可以缓存,代理服务器不可缓存)
public max-age=xxx (xxx is numeric) 缓存的内容将在 xxx 秒后失效, 这个选项只在HTTP 1.1可用
No-store 不缓存
3)body
HTTP的第三部分是可选的实体主体部分,实体的主体是HTTP报文的负荷。就是HTTP要传输的内容。(请求报文中可能的cookie,或者post data;响应报文中的html等)
HTTP报文可以承载很多类型的数字数据,图片、视频、HTML文档等。
除了用审查元素,开发者工具看报文之外,也可以利用强大的抓包工具,下面就来介绍一下fiddler的相关信息及使用
Fiddler是一款非常流行并且实用的http抓包工具,它的原理是在本机开启了一个 http 的代理服务器,然后它会转发所有的 http 请求和响应报文,显然是支持对手机等移动端进行抓包的。
当你启动了Fiddler,程序将会把自己作为一个微软互联网服务的系统代理中去。你可以通过检查代理设置对话框来验证Fiddler是被正确地截取了web请求。操作是这样的:点击IE设置,工具,局域网设置,最后点击高级。
作为系统代理,所有的来自互联网服务的http请求报文在到达目标Web服务器的之前都会经过Fiddle,同样的,所有的Http响应报文都会在返回客户端之前流经Fiddler。
操作界面: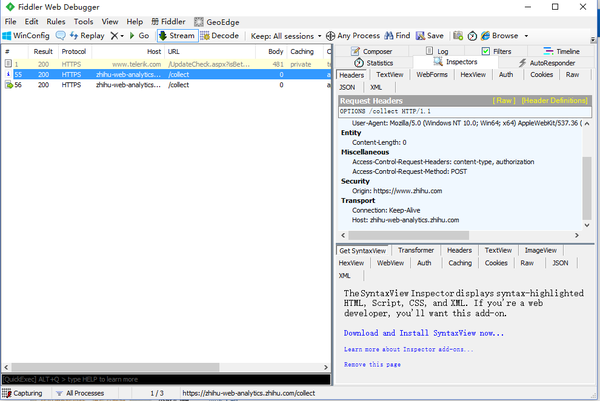
操作界面的右上部分:
Statistics :统计选中的一个或多个请求相关数据,大小、耗时 (包括DNS搜寻,http握手,TCP/Ip连接等)
Inspectors:查看Request或者Response报文的详细消息
Auto Responder: 设置一些规则将符合规则的请求指向本地。
Composer:创建发送HTTP请求 (利用fiddler U-A)
Log:日志
Filters:设置会话过滤规则
Timeline:网络请求时间
下图所示的上半部分具体显示了请求报文的具体信息,下半部分显示了响应报文的信息:
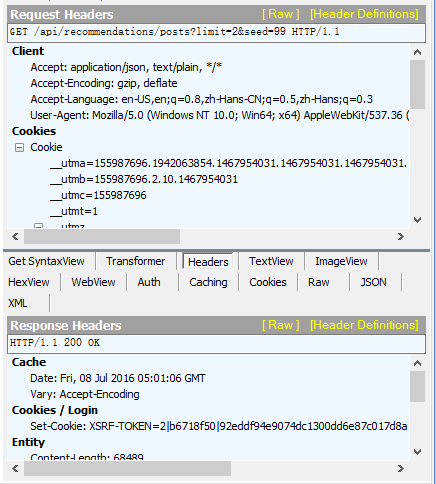 在响应以及请求报文的上半部分有一些具体的参数(如下图所示)
在响应以及请求报文的上半部分有一些具体的参数(如下图所示) headers:显示消息中的header
headers:显示消息中的header
json 用来格式化显示报文中的 json 数据(通常用于响应报文中)
cookie:直观地显示cookie参数
raw:用来显示报文的完整信息
查看这些参数,可以在python进行爬虫的时候更好的构造出 headers 信息,让python的爬虫行为更像浏览器行为,防止被反爬。
对手机等移动端进行抓包也很简单,只需要在tools-----fiddler options-----勾选allow remove computers to connect并设置好端口号-----然后让你的移动端访问相应的ip地址(在cmd中输入ipconfig即可查看本机ip)以及设置好的端口号,下载安全认证证书----在你的 wlan 设置里设置好相应的代理(ip地址以及port),这样配置就完成了。这样你就可以在fiddler中查看客户端访问的具体信息了(具体操作步骤同上文一样)
以上是关于Python 爬虫|深入请求:http协议以及fiddler的使用的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫-02:HTTPS请求与响应,以及抓包工具Fiddler的使用
Python网络爬虫与信息提取——HTTP协议及Requests库的方法