基于python的二元霍夫曼编码译码详细设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python的二元霍夫曼编码译码详细设计相关的知识,希望对你有一定的参考价值。
一、设计题目
对一幅BMP格式的灰度图像(个人证件照片)进行二元霍夫曼编码和译码
二、算法设计
(1)二元霍夫曼编码:
①:图像灰度处理:
利用python的PIL自带的灰度图像转换函数,首先将彩色图片转为灰度的bmp图像,此时每个像素点可以用单个像素点来表示。
②:二元霍夫曼编码:
程序流程图:
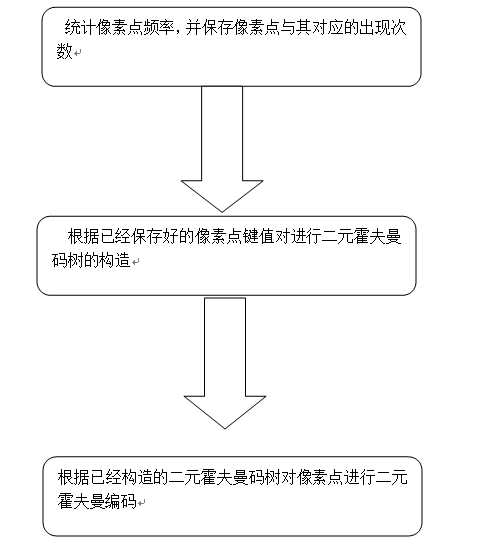
详细设计:
- 统计像素点频率,首先通过python自带的PIL库的图像像素点读取函数read()获取灰度图像的所有像素点,通过循环遍历每个像素点,将每个出现的像素点值以及其次数以键值对的形式放入到python的字典中。
①:首先构造用以表示节点的类,其中每个节点包括一下成员属性:
self.left = left
self.right = right
self.parent = parent
self.weight = weight
self.code = code
②:遍历已经保存好的像素点频率字典,将图片中出现的像素点全部定义为叶子节点,通过类的code以及weight来表示对应的像素点值和该像素点出现的次数。
③:此时叶子结点中的权值为乱序,此时依据每个叶子结点的权重所有的叶子结点进行从小到大的排序;
④:每次取权值最小的两个节点最为要被替换的节点,将这两个节点的权值进行相加,然后生成新的节点,同时将这两个节点从叶子结点列表中去除,同时将新生成的节点放入叶子节点列表,同时对列表进行排序;
⑤:重复步骤④,直到列表中还剩下一个节点,此时这个节点便为头节点。
3.
①:根据已经构造好的二元霍夫曼编码树,由叶子节点开始遍历整棵树,左边赋予码字1,右边赋予码字0,每次向下遍历一次,若节点为非根节点,则依次将码符号放在码字左边,若遍历到根节点,则将该叶子结点所表示的像素值以及对应编成的码字放到码字字典中;
②:重复步骤①,直到所有的叶子节点都有其对应的二元霍夫曼码字。
③:经过步骤②,此时像素的码字字典已经生成,此时回归到原图片,根据遍历原图片的像素点,依次在码字列表中查找其对应的码字,将所有像素点对应的码字拼接在一起。
4.此时由于为二元霍夫曼编码,则编码结果为01字符串,此时为了对信息量进行压缩,采用将8个string类似的值转为一个byte,首先填充编码结果使其长度为8的倍数,并增加冗余位数保存原使编码结果最后多余位数的值以及其长度。填充完毕后,只需每次取编码结果的八位转为一个byte存入到txt中即可。
(2)二元霍夫曼译码:
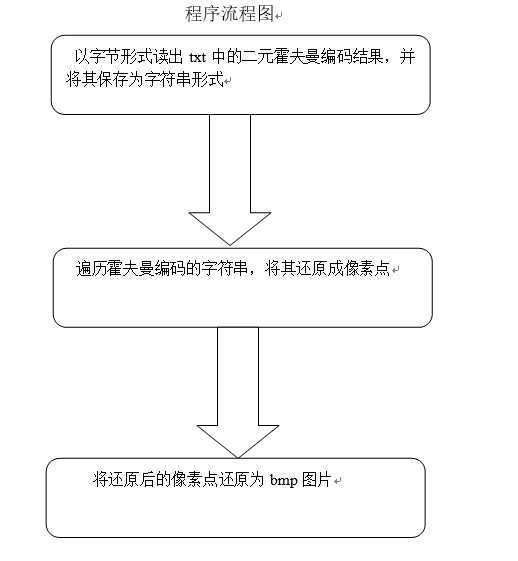
详细设计:
1.每次读取txt中的一个字节,将其还原为字符串,直到txt中的所有字节被读取结束 ,则所得到的字符串则为霍夫曼编码的结果。
2.
①遍历霍夫曼编码的结果,根据霍夫曼编码已经生成的码字列表,对原始像素点进行还原,并根据还原后的像素点生成原始bmp图片。
②:对于每一个被遍历到的字符均在码字列表中进行查找,若未找到则加上后续一个字符,继续查找;
③:重复步骤③,直到在码字列表中找到该码字对应的像素点,将其码字对应的像素值放入到像素点列表中,重复以上查找还原像素值的步骤直到所有字符串均被遍历完。
三、模块划分
(1)二元霍夫曼编码部分:
①:类:
class node:
def __init__(self, right=None, left=None, parent=None, weight=0, code=None):
self.left = left
self.right = right
self.parent = parent
self.weight = weight
self.code = code
功能:表示叶子节点的类
②:函数:
def picture_convert():
功能:此函数完成彩色图转为灰度图的功能
③:函数:
def pin_lv_tong_ji(list):
功能:统计每个像素出现的次数
④:函数
def gou_zao_ye_zi(xiang_su_zhi):
功能:此函数主要为生成叶子结点,将每个节点赋予权值与像素值
⑤:函数
def sort_by_weight(list_node):
功能:根据每个叶子结点的权重对叶子结点列表进行排序
⑥:函数
def huo_fu_man_shu(listnode):
功能:根据叶子结点列表,生成对应的霍夫曼编码树
⑦:函数
def er_yuan_huo_fu_man_bian_ma(picture):
功能:此函数为进行二元霍夫曼编码的主函数,通过对其他函数的调用完成对像素点的编码
⑧:函数
def zi_jie_xie_ru():
功能:由于霍夫曼编码结果为string类型,此时应将其转为byte保存,此函数完成将编码结果的字节存入
(2)二元霍夫曼译码部分:
①:函数:
def zi_jie_du_qu(qqqq):
功能:根据霍夫曼编码生成的txt文件读取其中的字节恢复为字符串形式的编码结果
②函数:
def er_yuan_huo_fu_man_yi_ma(kuan,gao)
功能:此为二元霍夫曼译码的主函数,通过调用其他函数来还原原始的bmp图像
四、测试数据
测试采取图片像素点个数大小两种bmp图进行:
图片1信息:
名称:new.bmp

大小: 255 KB (261,366 字节)
像素点个数为: 260288
灰度图宽为448像素
灰度图高为581像素
图片2信息:
名称:test1.bmp

大小:12.7 KB (13,078 字节)
像素点个数: 12000
灰度图宽:96像素
灰度图高:125像素
六、测试情况及结果分析:
(一)二元霍夫曼编码过程:
图片1测试结果:
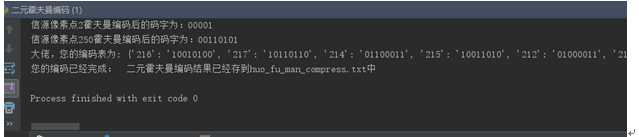
程序运行后将会生成霍夫曼编码表,并且将最终的编码结果存入到当前程序运行目录下的huo_fu_man_compress.txt中
由于存入为字节形式,以txt形式查看会显示乱码,属于正常情况。

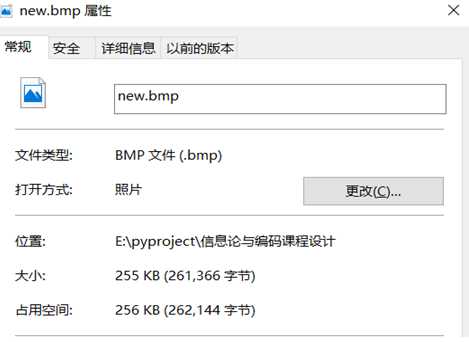
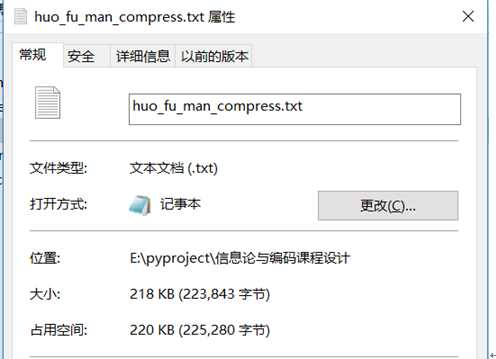
原始图像大小为255kb,经过霍夫曼编码最终大小为218kb,大小缩减了接近15%。
图片2测试结果:
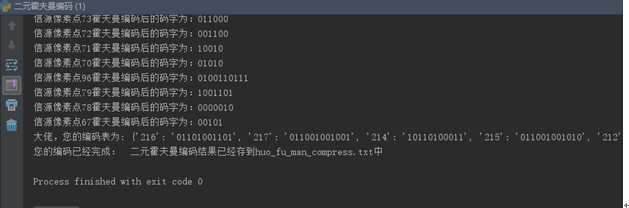
由程序运行结果可得出二元霍夫曼游程编码结果保存到
er_yuan_huo_fu_man_youcheng_compress.txt中

由于存入为字节形式,以txt形式查看会显示乱码,属于正常情况。
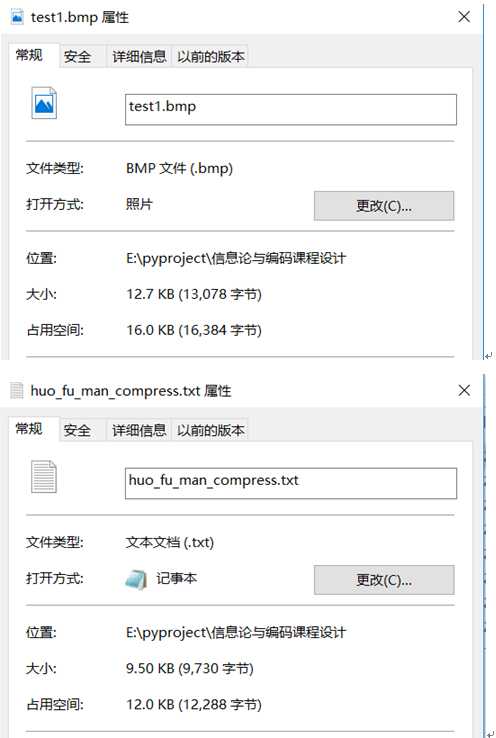
原始图片大小为12.7kb,编码结果文件为9.5kb,大小缩减了接近26%。
(二)二元霍夫曼译码过程:
图一测试结果:
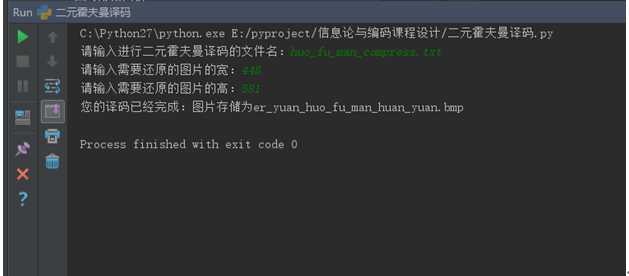
根据编码生成的huo_fu_man_compress.txt还原原始bmp图片并保存为
er_yuan_huo_fu_man_huan_yuan.bmp
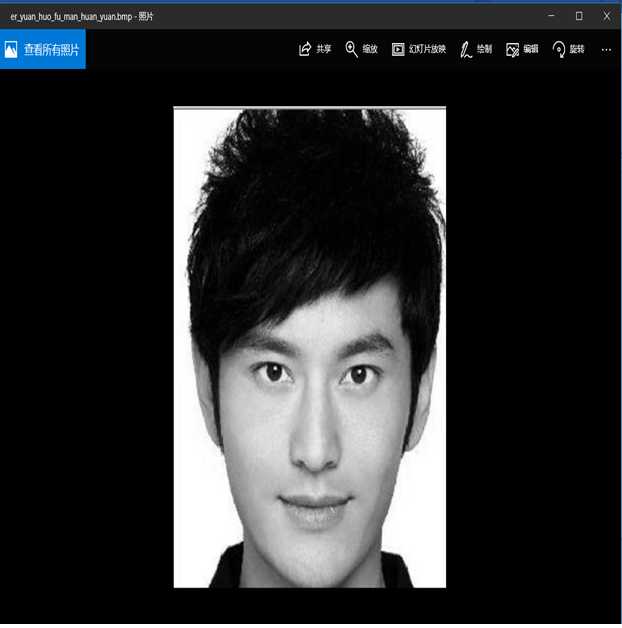
还原后的图片与原始图片相符合,译码成功
图片2测试结果:
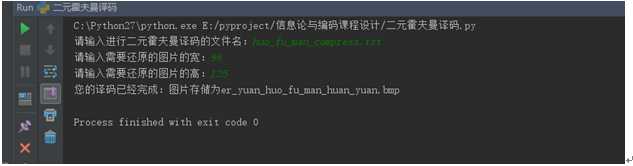
根据编码生成的huo_fu_man_compress.txt还原原始bmp图片并保存为
er_yuan_huo_fu_man_huan_yuan.bmp
还原后的图片与原始图片相符合,译码成功
结果分析:
Bmp灰度图片经过二元霍夫曼编码后,文件大小总能够缩小,即所占空间减小,即达到了压缩的效果,压缩效率会由像素点出现频率的影响。
等长码编码位数的影响。
以上是关于基于python的二元霍夫曼编码译码详细设计的主要内容,如果未能解决你的问题,请参考以下文章