字符集与字符编码
Posted EGBDFACE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符集与字符编码相关的知识,希望对你有一定的参考价值。
字符集
字符集是很多个字符的集合,例如 GB2312 是简体中文的字符集,它收录了六千多个常用的简体汉字及一些符号,数字,拼音等字符
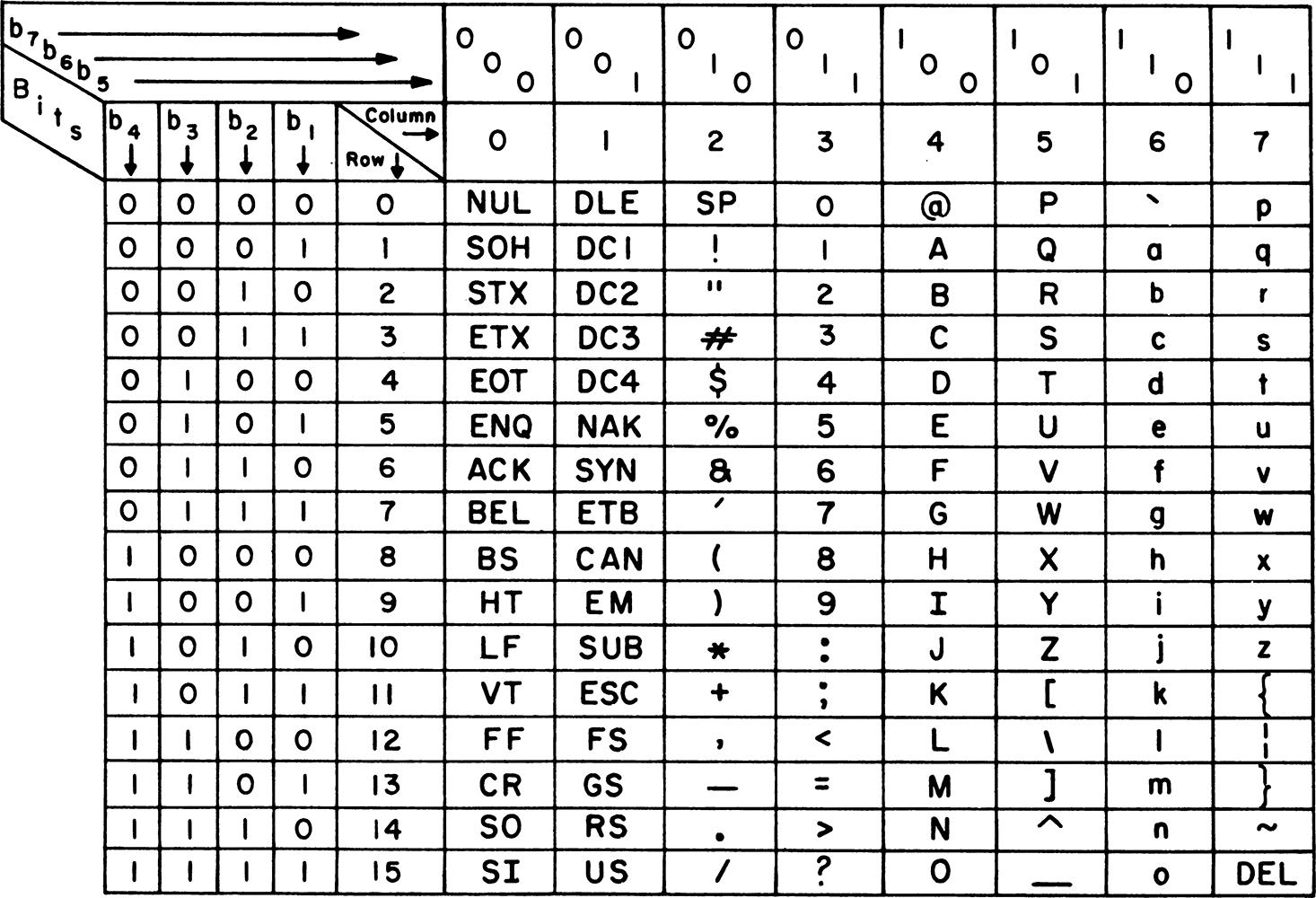
ASCII
ASCII (American Standard Code for Information Interchange 美国信息交换标准代码) 是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语。用7位二进制码表示(0x00-0x7F),共定义128个字符
Unicode
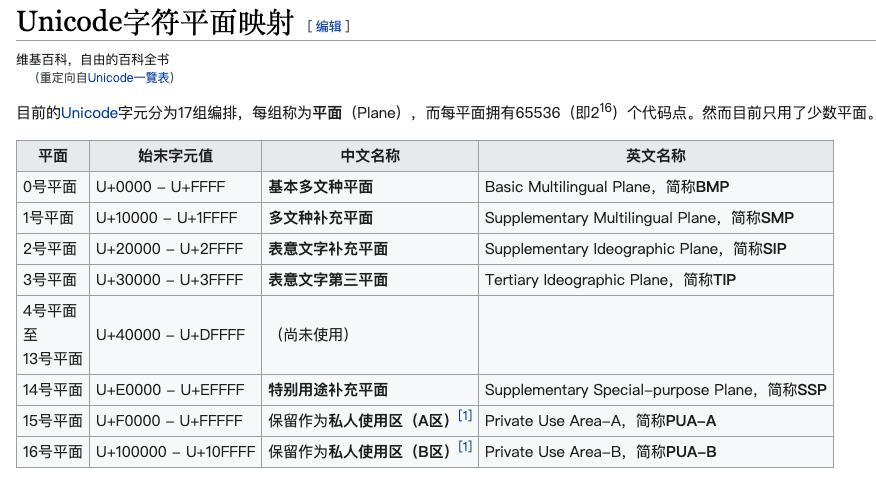
Unicode (The Unicode Standard)译作万国码、统一字元码、统一字符编码,是信息技术领域的业界标准,其整理、编码了世界上大部分的文字系统,使得电脑能以统一字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案。
其字符占用2~3个字节(0x0000-0x10FFFF)。目前分为17个组进行编排,每个组称为一个平面,每个平面拥有65536个编码点,且当前只使用了少数平面。
字符编码
字符编码是字符集的一种实现方式,把字符集中的字符映射为特定的字节或字节序列,是一种规则。
Unicode 只是规定了字符的二进制代码,但并没有规定这些二进制代码应该如何表示和存储。如ASCII用7位二进制码,只需要一个字节来进行存储。而Unicode的编码范围从0x0000到0x10FFFF,编码范围从2字节到3字节,如果都用字符都按照3字节进行存储,将造成不小的存储空间浪费。如果用变长字节进行表示,计算机如何区分是用1个字节还是3个字节表示字符? UTF-8、UTF-16、UTF-32就是为了区分这些编码表示规则中的几种,后面的数字就是表示最少需要多少比特位来表示一个字符,UTF8最少需要一个字节,UTF16和UTF32分别最少需要两个和三个字节。
UTF-8
UTF-8是一种变长字符编码,将字符编码为1-4个字节
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的, 所以 UTF-8 能兼容 ASCII 编码,这也是互联网普遍采用 UTF-8 的原因之一
- 对于 n 字节的符号( n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。所以如果第一位是1,连续有多少个 1 ,就表示当前字符占用多少个字节
UTF-16
UTF-16也是一种变长字符编码,将字符编码为2或4个字节
- 对于 Unicode 码小于 0x10000 的字符, 使用 2 个字节存储,并且是直接存储 Unicode 码,不用进行编码转换
- 对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4 个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为 110111, 前后部分各剩余 10 位二进制表示符号的 Unicode 码 减去 0x10000 的结果
- 大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码
UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 码即可,不需要任何编码转换。
参考:
https://zhuanlan.zhihu.com/p/427488961
https://www.cnblogs.com/xiaxveliang/p/17212404.html
https://mp.weixin.qq.com/s/QjU9lSekpbaF7fugZbyzkg
以上是关于字符集与字符编码的主要内容,如果未能解决你的问题,请参考以下文章