阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href相关的知识,希望对你有一定的参考价值。
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href
1.查找以<a>开头的所有文本,然后判断href是否在<a>里面,如果<a>里面有href,就像<a href=" " >,然后提取href的值。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a"):
if ‘href‘ in link.attrs:
print(link.attrs[‘href‘])
运行结果:
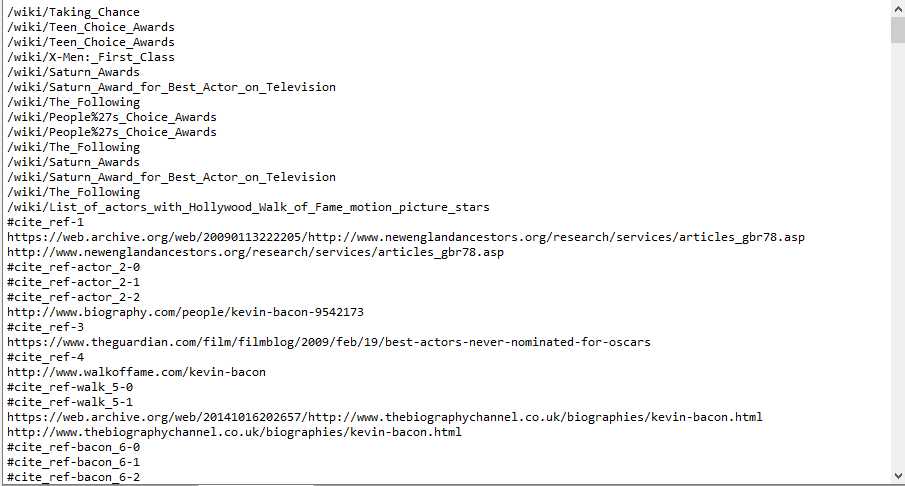
在网页源代码的定位:

2.提取以 /wiki/开头的文本
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html,"lxml")
for link in bsObj.find("div", {"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$")):
if ‘href‘ in link.attrs:
print(link.attrs[‘href‘])
运行结果:

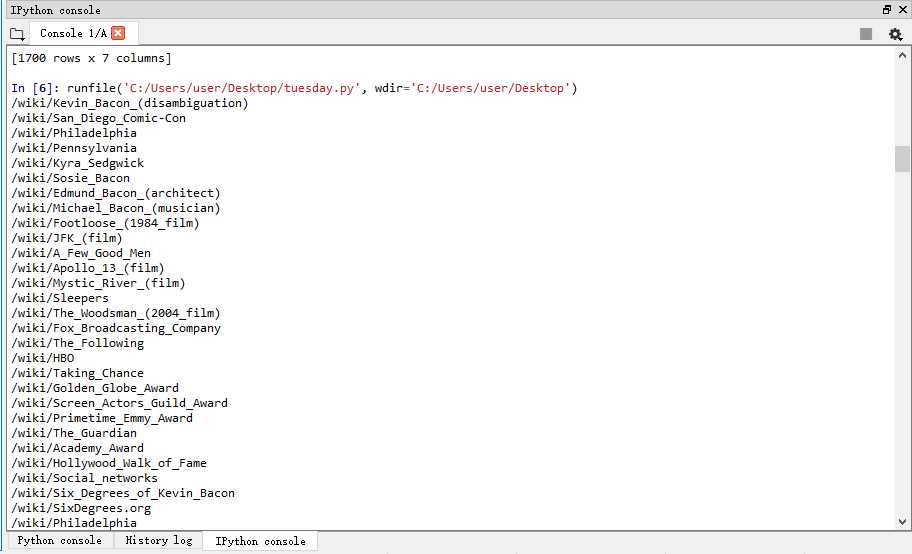
3.连环着提取不同网页以/wiki开头的文本
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html,"lxml")
return bsObj.find("div", {"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
运行结果:
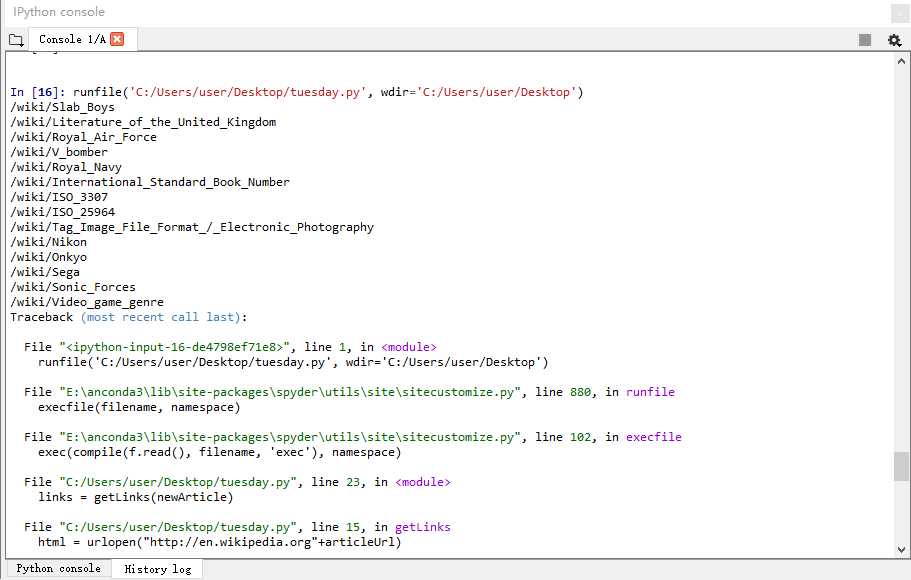
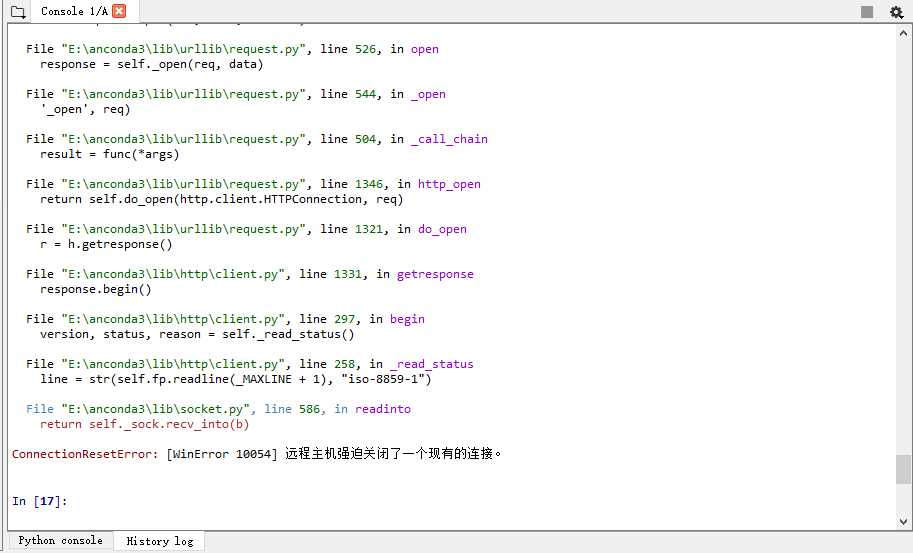
运行一段时间之后,会报错:远程主机强迫关闭了一个现有的连接,这是网站拒绝程序的连接吗?
以上是关于阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href的主要内容,如果未能解决你的问题,请参考以下文章