pooling的原理与Python实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pooling的原理与Python实现相关的知识,希望对你有一定的参考价值。
本文首先阐述pooling所对应的操作,然后分析pooling背后蕴含的一些道理,最后给出pooling的Python实现。
一、pooling所对应的操作
首先从整体上对pooling有一个直观的概念(也就是对pooling的输入、输出以及具体功能进行描述,但是忽略具体的实现细节):pooling的输入是一个矩阵,输出是一个矩阵;完成的功能是,对输入矩阵的一个局部区域进行运作,使得该区域对应的输出能够最佳的代表该区域的特性。如图1所示,左图黄色矩阵代表输入矩阵,右图蓝色矩阵代表输出矩阵;动态的橙色矩阵代表选定输入矩阵的一个局部区域,然后寻找出该区域的一个最佳代表出来,最后将所有选出的代表按照与原始输入矩阵对应的空间位置关系在输出矩阵中进行排序。
这一过程可以用选举过程来类比。假如要选北京市长,一种可行的做法是,北京的每一个区各选一个最符合该区权益的代表,然后由选出的代表们决定如何选取北京市长。当然了,我们希望每一个区选出的代表最能符合该区的权益。与pooling做一个简单类比,北京〈-〉输入矩阵;朝阳区、海淀区等〈-〉局部区域;各区代表〈-〉输出矩阵(如果他们开会的时候按照地理位置就坐,这就和pooling的特性很像了)。
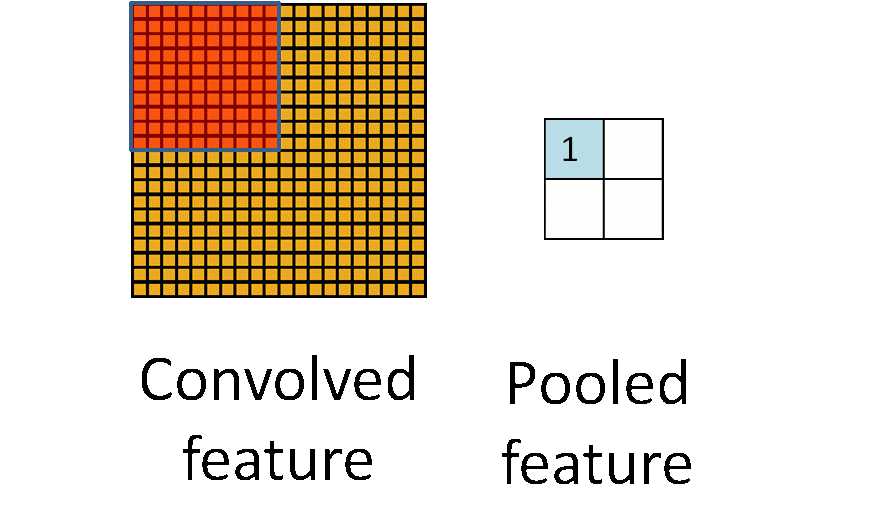
图1 pooling对特征的操作示意图
二、pooling背后蕴含的道理
在局部区域选取代表的过程中,我们一般的做法是:选取该区域最有声望的人作为代表(对应max pooling)或者选取最能代表该区域所有人一般特性的人作为代表(对应mean pooling),于此对应的是,pooling中也存在两种常用的做法:局部区域值最大的胜出作为该区域的代表或者将该区域所有的值取平均作为该区域的代表。
选取该区域最有声望的人作为代表 vs 选取最能代表该区域所有人一般特性的人作为代表 好处是:
1) 局部区域最有声望的人在选市长时不宜出现偏差,但他有可能倚老卖老,不能代表该区域一般民众的看法(局部的最大值,容易忽略该区域的一般特性)
2) 最能代表该区域所有人一般特性的人虽然能够代表该区域所有居民的最大权益,但是由于他的认知能力有限(局部均值较小,所以说他认知能力有限),在选市长时容易出现偏差。
3) 如果该区域内的人存在一定程度的自由活动的话(对应的是平移、旋转不变性),对上述两种选代表的方式基本是没有影响的。
pooling的正规解释
根据相关理论:(1)邻域大小受限造成的估计值方差增大;(2)误差造成估计均值的偏移。一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
一般情况下pooling的输入维度高、输出维度低,这在一定程度上可以理解为降维,根据上述对pooling原理的阐述,我们可以推断,这种降维过程极大的保留了输入的一些最重要的信息。在实际应用pooling的过程中,我们需要根据实际问题的特点,具体分析了。其实,知道了pooling的操作及其原理,如果她与具体问题结合的较好,则不失为一个很好的创新点哦,哈哈。
三、pooing的Python实现
笔者在写代码时的一些思考如下,核心就是将一个复杂问题拆分为一个可以直接用代码实现的问题:
1) 输入矩阵可以为mxn,也可以为mxnxp,如果直接考虑这两种形式写代码的时候无从下手(要考虑的情况有点多,并且多维的矩阵我自己容易搞晕)。仔细分析发现如果我将 mxn矩阵的pooling实现,那么mxnxp矩阵就可以运用mxn矩阵的实现轻而易举实现了。
2) 针对mxn矩阵输入,有可能图1橙色方框不能恰好覆盖输入矩阵,因此需要对输入矩阵进行扩展。扩展也很简单,只要最后一个poolStride对应的poolSize能够覆盖输入矩阵, 其他的肯定可以覆盖了。
3) 最后就是for循环进行类似操作过程处理了。
def pooling(inputMap,poolSize=3,poolStride=2,mode=‘max‘): """INPUTS: inputMap - input array of the pooling layer poolSize - X-size(equivalent to Y-size) of receptive field poolStride - the stride size between successive pooling squares OUTPUTS: outputMap - output array of the pooling layer Padding mode - ‘edge‘ """ # inputMap sizes in_row,in_col = np.shape(inputMap) # outputMap sizes out_row,out_col = int(np.floor(in_row/poolStride)),int(np.floor(in_col/poolStride)) row_remainder,col_remainder = np.mod(in_row,poolStride),np.mod(in_col,poolStride) if row_remainder != 0: out_row +=1 if col_remainder != 0: out_col +=1 outputMap = np.zeros((out_row,out_col)) # padding temp_map = np.lib.pad(inputMap, ((0,poolSize-row_remainder),(0,poolSize-col_remainder)), ‘edge‘) # max pooling for r_idx in range(0,out_row): for c_idx in range(0,out_col): startX = c_idx * poolStride startY = r_idx * poolStride poolField = temp_map[startY:startY + poolSize, startX:startX + poolSize] poolOut = np.max(poolField) outputMap[r_idx,c_idx] = poolOut # retrun outputMap return outputMap
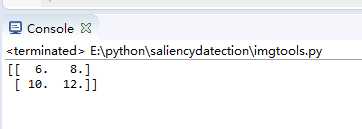
# 测试实例
test = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
test_result = pooling(test, 2, 2, ‘max‘)
print(test_result)
测试结果:
总结: 先理解一项技术的输入、输出以及其完成的功能;然后在生活中寻找类似的例子;最后,将该项技术分解为可以实现的步骤。
以上是关于pooling的原理与Python实现的主要内容,如果未能解决你的问题,请参考以下文章
空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch)