对斗破苍穹进行python文本分析
Posted 宣哲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对斗破苍穹进行python文本分析相关的知识,希望对你有一定的参考价值。
对斗破苍穹进行python文本分析
用python分析该小说的分词,词频,词云,小说人物出场次数排序等等。
1、分词
对文本进行分词,将分词结果输出到文本文件中。
自己创建一个txt文本文件,形成自定义词库,如下
import jieba
import re
import string
# 使用 load_userdict 方法加载自定义词库
jieba.load_userdict("1.txt")
with open(\'doupo.txt\',\'r\',encoding=\'gbk\') as f: #读取文件
text = f.read()
# 使用正则表达式去掉标点符号和空格
text = re.sub(\'[\\s+\\.\\!\\/_,$%^*(+\\"\\\']+|[+——!,。?、~@#¥%……&*():;《)《》“”()»〔〕-]+\', \'\', text)
# 对文本进行分词
words = jieba.cut(text)
# 去掉无意义的空字符串
result = \' \'.join(word for word in words if word.strip())
# 将分词结果保存到txt文档中
with open(\'output.txt\', \'w\', encoding=\'utf-8\') as f:
f.write(result)
结果显示:
2、词频
import jieba
import jieba.posseg as pseg
from wordcloud import WordCloud
from collections import Counter
import matplotlib.pyplot as plt
import re
with open(\'output.txt\',\'r\',encoding=\'utf-8\') as f: #读取文件
text = f.read()
# 对文本进行分词
words = jieba.lcut(text)
# 统计词频
word_count =
for word in words:
if len(word) > 1: # 只统计长度大于1的词
word_count[word] = word_count.get(word, 0) + 1
# 按照词频排序
sorted_word_count = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
# 打印结果
for word, count in sorted_word_count:
print(word, count)
结果显示:
由于分词太多就不一一展示
3、绘制词云
import jieba
import jieba.posseg as pseg
from wordcloud import WordCloud
from collections import Counter
import matplotlib.pyplot as plt
import re
with open(\'doupo.txt\',\'r\',encoding=\'gbk\') as f: #读取文件
text = f.read()
# 对文本进行分词
words = jieba.lcut(text)
# 统计词频
word_count =
for word in words:
if len(word) > 1: # 只统计长度大于1的词
word_count[word] = word_count.get(word, 0) + 1
# 按照词频排序
sorted_word_count = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
#创建词云对象
wc = WordCloud(
font_path=\'云峰静龙行书.ttf\',
background_color= \'white\',
max_words=500,
max_font_size=200,
width=1000,
margin=5,
height=800
).generate_from_frequencies(word_count)
plt.imshow(wc)
plt.axis(\'off\')
plt.show()
结果显示:

4、画饼状图
注:小说前10人物出场次数排序的饼状图
import jieba
import matplotlib.pyplot as plt
from collections import Counter
import re
# 打开人物姓名词库文件
with open(\'person_names.txt\', \'r\', encoding=\'utf-8\') as f:
person_names = f.read().splitlines()
# 添加人物姓名词库到结巴分词器
jieba.load_userdict(\'person_names.txt\')
# 打开文本文件
with open(\'doupo.txt\', \'r\', encoding=\'gbk\') as f:
text = f.read()
# 对文本进行分词
words = jieba.lcut(text)
# 统计人物姓名词频
name_freq =
for word in words:
if word in person_names:
if word in name_freq:
name_freq[word] += 1
else:
name_freq[word] = 1
# 输出人物姓名及其词频
#for name, freq in name_freq.items():
#print(name, freq)
sorted_dict = sorted(name_freq.items(), key=lambda x: x[1], reverse=True)
top_words = sorted_dict[:10] # 取出前 10 个值
labels = [word[0] for word in top_words]
sizes = [word[1] for word in top_words]
# 画图
fig, ax = plt.subplots()
plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 设置字体为黑体
plt.pie(sizes, labels=labels, autopct=\'%1.1f%%\', startangle=150)
plt.rcParams[\'font.size\'] = 16
# 调整图形大小
fig.set_size_inches(8, 8)
# 添加标题
plt.title(\'斗破苍穹人物出场次数饼状图\')
# 显示图表
plt.show()
结果显示:
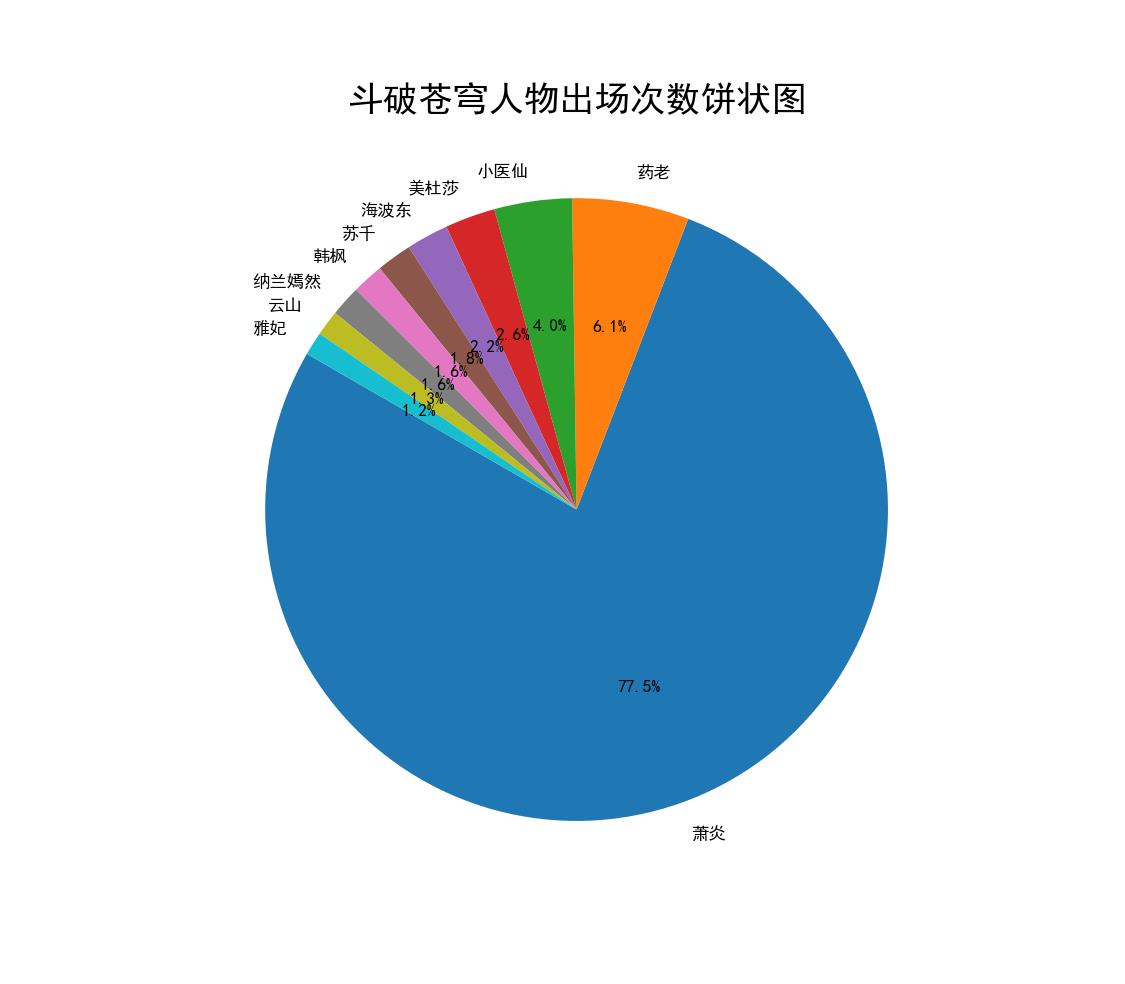
以上是关于对斗破苍穹进行python文本分析的主要内容,如果未能解决你的问题,请参考以下文章