python网络编程--RabbitMQ
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python网络编程--RabbitMQ相关的知识,希望对你有一定的参考价值。
一:RabbitMQ介绍
RabbitMQ是AMPQ(高级消息协议队列)的标准实现。也就是说是一种消息队列。
二:RabbitMQ和线程进程queue区别
线程queue:不能跨进程,只能用于多个线程数据交互。
进程queue:只用于父进程和子进程交互或者同属于一个父进程的多个子进程间交互
如果两个不同的程序或者语言,或者不同服务器消息如何交互了?这里就可以使用RabbitMQ
三:安装RabbitMQ
RabbitMQ是由erlang语言开发的,所以要安装erlang
1)erlang安装
下载:http://erlang.org/download.html 自己根据需要下载源码包或win的二进制包
2)RabbitMQ程序安装
下载:http://www.rabbitmq.com/server.html 自己根据需要下载源码包或win的二进制包
3)python rabbitmq模块安装
pip install pika
注意:
1)windows和linux安装完成后都有rabbitmq服务 下图是windows

2)如果程序运行报如下错:pika.exceptions.ConnectionClosed
说明RabbitMQ没有安装或者RabbitMQ服务没有起动。
四:RabbitMQ实现最简单的队列通信模型
整个RabbitMQ的实现原理模型见下图,其实就是一个带路由任务分发队列的生产者与消费者模型。
如图所示,即生产者生产出相应的信息,发送给路由器,路由器根据信息中的关键Key信息,
将信息分发到不同的消息队列中,再由消费者去不同的消息队列中读取数据的过程。
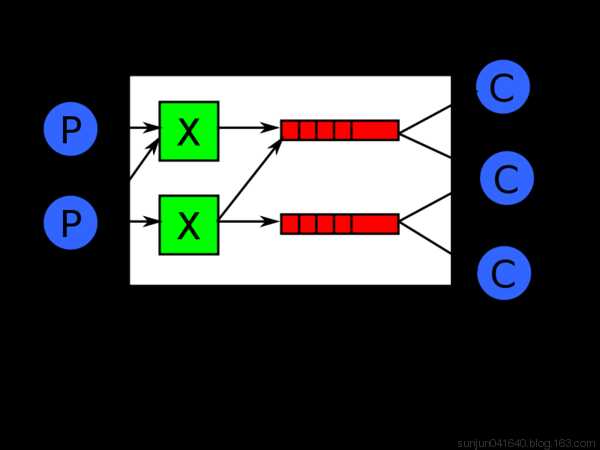
说明:
Broker:简单来说就是消息队列服务器实体。
Exchange;消息交换机,它指定消息按什么规则,路由到那个列表。
Queue:消息队列载体,每个消息都会被投入一个或者多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing key:路由关键字,exchange根据这个关键词进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
prouducer:消息生产者,就是投递消息的程序。
conumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接,可以建立多个channel,每个channel代表一个会话任务。
消息队列使用过程大概如下:
1)客户端连接到消息队列服务器,打开一个channel.
2) 客户端声明一个exchange,并设置相关属性
3)客户端声明一个queue,并设置相关属性
4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
5)客户端投递消息到exchange
五:简单示例

生产消费
发送端producer
import pika # 建立一个实例 connection = pika.BlockingConnection( pika.ConnectionParameters(‘localhost‘,5672) # 默认端口5672,可不写 ) # 声明一个管道,在管道里发消息 channel = connection.channel() # 在管道里声明queue channel.queue_declare(queue=‘hello‘) # RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. channel.basic_publish(exchange=‘‘, routing_key=‘hello‘, # queue名字 body=‘Hello World!‘) # 消息内容 print(" [x] Sent ‘Hello World!‘") connection.close() # 队列关闭
import pika import time # 建立实例 connection = pika.BlockingConnection(pika.ConnectionParameters( ‘localhost‘)) # 声明管道 channel = connection.channel() # 为什么又声明了一个‘hello’队列? # 如果确定已经声明了,可以不声明。但是你不知道那个机器先运行,所以要声明两次。 channel.queue_declare(queue=‘hello‘) def callback(ch, method, properties, body): # 四个参数为标准格式 print(ch, method, properties) # 打印看一下是什么 print(" [x] Received %r" % body) time.sleep(15) ch.basic_ack(delivery_tag = method.delivery_tag)
# 和no_ack=False配置使用,表示告消费端处理完了,消除queue消息。如果没有设置basic_ack如果客户断了或者其他情况,queue消息还是存在会发给其他消费端 channel.basic_consume( # 消费消息 callback, # 如果收到消息,就调用callback函数来处理消息 queue=‘hello‘, # 你要从那个队列里收消息 # no_ack=True # 如果设置no_ack=True表示,不管消费端有没有处理完,都清除queue消息,默认是no_ack=False,表示保留消息 ) print(‘ [*] Waiting for messages. To exit press CTRL+C‘) channel.start_consuming() # 开始消费消息
六:RabbitMQ 消息分发轮询
问题1:上面的只是一个生产者、一个消费者,能不能一个生产者多个消费者呢?
RabbitMQ会默认采用轮询机制;把消息依次分发。把p发的消息依次分发给各个消费者(c),跟负载均衡差不多。
问题2:如果消费端程序没有运行结束,就受到中断或者RabbitMQ服务中断,queue中的消息是还存在?
两种模式:
如果设置no_ack=True表示,不管消费端有没有处理完,都清除queue中消息。
默认是no_ack=False,表示保留消息。当消费端中断消息会发其他消费端。当设置了basic_ack(delivery_tag = method.delivery_tag) 表示
表示告消费端处理完了,消除queue中消息,如果没有设置,表示消息还在队列中。
以上是关于python网络编程--RabbitMQ的主要内容,如果未能解决你的问题,请参考以下文章