Python基础day03:字符转编码操作
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础day03:字符转编码操作相关的知识,希望对你有一定的参考价值。
一、概述
说到python的编码,一句话总结,说多了都是泪啊,这个在以后的python的开发中绝对是一件令人头疼的事情。所以有必要要讲讲清楚
二、编码介绍
1、须知:
- 在python 2中默认编码是 ASCII,而在python 3中默认编码是 unicode
- unicode 分为utf-32 (占4个字节),utf-16(占两个字节),utf-8(占1-4个字节),所以utf-16 是最常用的unicode版本,但是在文件里存的还是utf-8,因为utf8省空间
- 在python 3,encode编码的同时会把stringl变成bytes类型,decode解码的同时会把bytes类型变成string类型
- 在unicode编码中 1个中文字符=2个字节,1个英文字符 = 1个字节,切记:ASCII是不能存中文字符的
- utf-8是可变长字符编码,它是unicode的优化,所有的英文字符依然按ASCII形式存储,所有的中文字符统一是3个字节
- unicode包含了所有国家的字符编码,不同字符编码之间的转换都需要经过unicode的过程
- python本身的默认编码是utf-8
2、py2中的编码和转码的过程,如图:
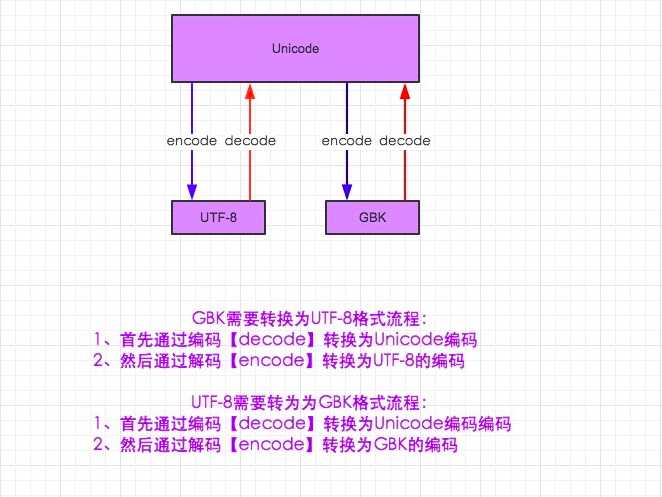
注:因为unicode是中间编码,任何字符编码之前的转换都必须解码成unicode,在编码成需要转的字符编码
3、py2字符编码的转换,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#! /usr/bin/env python# -*- coding:utf-8 -*-# __auther__ == zhangqigaos = "其高最帅"#utf-8解码成unicode编码s_to_unicode = s.decode("utf-8")print("--------s_to_unicode-----")print(s_to_unicode)#然后unicode再编码成gbks_to_gbk = s_to_unicode.encode("gbk")print("-----s_to_gbk------")print(s_to_gbk)#gbk解码成unicode再编码成utf-8gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")print("------gbk_to_utf8-----")print(gbk_to_utf8)#输出--------s_to_unicode-----其高最帅-----s_to_gbk------??????------gbk_to_utf8-----其高最帅 |
注:以上这种情况适合字符是非unicode编码请款下,但是如果字符编码已经是Unicode的了咋办呢?广告回来,更加精彩。。。。。
4、字符编码已经是unicode情况下,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#! /usr/bin/env python# -*- coding:utf-8 -*-# __auther__ == zhangqigao#u代码字符编码是unicodes = u‘你好‘#已经是unicode,所以这边直接是编码成gbks_to_gbk = s.encode("gbk")print("----s_to_gbk----")print(s_to_gbk)#这边再解码成unicode然后再编码成utf-8gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")print("-----gbk_to_utf8---")print(gbk_to_utf8)#输出----s_to_gbk----???-----gbk_to_utf8---你好 |
注:在python2中,在文件的开头指定字符编码,是要告诉解释器我现在的字符编码使用的是utf-8,那我在打印的中文时候,那么在utf-8中包含中文字符,那么可以打印出来。那么如果你不制定字符编码,默认使用系统编码,如果你的系统编码是ASCII,那么就会报错,因为ASCII不能存中文字符。
5、py3的字符编码转换
在须知中已经说到python 3的编码,默认是unicode,所以字符编码之间的转换不需要decode过程,直接encode即可,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#! /usr/bin/env python# __auther__ == zhangqigao#无需声明字符编码,当然你声明也不会报错s = ‘你好‘# 字符串s已经是unicode编码,无需decode,直接encodes_to_gbk = s.encode("gbk")print("----s_to_gbk----")print(s_to_gbk)#这边还是一样,gbk需要先解码成unicode,再编码成utf-8gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")print("-----gbk_to_utf8---")print(gbk_to_utf8)#解码成unicode字符编码utf8_decode = gbk_to_utf8.decode("utf-8")print("-------utf8_decode----")print(utf8_decode)#输出----s_to_gbk----b‘\\xc4\\xe3\\xba\\xc3‘-----gbk_to_utf8---b‘\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd‘-------utf8_decode----你好 |
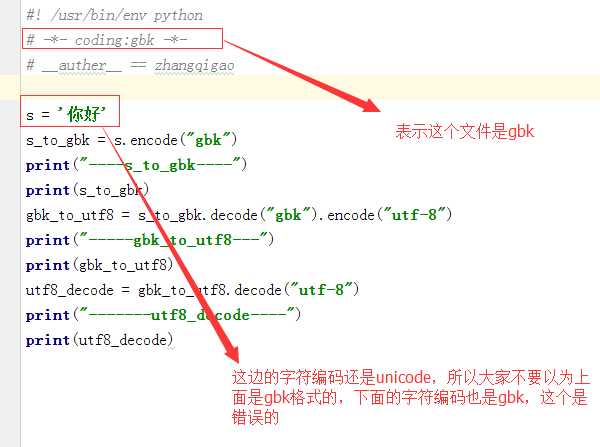
注:在python 3,encode编码的同时会把stringl变成bytes类型,decode解码的同时会把bytes类型变成string类型,所以你就不难看出encode后的把它变成了一个bytes类型的数据。还有需要特别注意的是:不管是否在python 3的文件开头申明字符编码,只能表示,这个python文件是这个字符编码,文件中的字符串还是unicode,如下图:
总结:
- uniocode能识别所有字符编码的字符串
- 在python 2中,字符编码之间的转化需要通过unicode才能转换,所以打印时,可以是使用unicode,也可以使用对应的字符编码(文件开头指定编码),打印字符或者字符串,因为py2中没有对字符和字节做明显区分,所以才混导致这样的结果。
- 在python 3中,只有通过Unicode去识别字符的,如果转成编码成对应编码格式了,就直接变成对应编码的bytes类型的字节码,也就是二进制,需要识别,必须解码成Unicode才能识别
- py3中如果说在文件开头已经指定了文件编码,为啥文件中用到的还是uniocde呐?因为py3中的对应编码是二进制,是bytes类型,是不能识别的,能识别的只有Unicode。因为py3中对字符和字节做了明显的区分,所以出现3和4阐述的情况。
- 说到这里,如果还是不明白的话,我引用一下别人的文章,阐述一下,python 2和python 3对字符和字节的区分:猛击这里
以上是关于Python基础day03:字符转编码操作的主要内容,如果未能解决你的问题,请参考以下文章
Python自动化开发课堂笔记Day03 - Python基础(字符编码使用,文件处理,函数)