[Python] 网络爬虫实战:网站链接的初级爬取
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python] 网络爬虫实战:网站链接的初级爬取相关的知识,希望对你有一定的参考价值。
闲来无事,想要学习一下Python,十月初的时候搭好了ubuntu的环境,用的是Ubuntu 16.04 32位+sublime Text3,轻量级的编程环境,感觉用起来还是比较舒服的。也陆陆续续地学习了一下python的语法和相关的知识点,并没有感觉到python有什么特别的地方,数据结构中的列表,元组和字典,还没有感到其特点在哪里比较明显,只是一个数据结构而已。恰好学院老师让搜集就业相关信息,所以就想尝试去先写一个爬虫,爬一下相关网站的相关链接。先提起兴趣,再去学习枯燥的知识点。
一开始以为会是很大的工程量,周五下午回到宿舍就开始查相关资料,看了一下链接,先Mark一下:汪海的实验室,很多笔记,感觉应该专业人士,而且很巧也是山大毕业的。看到了一个比较简单的教程,利用审查元素和一个python的requests模块发送请求,然后利用pyquery模块来解析数据。当然,具体的jquery语法是什么样的我还是不清楚的=,=。教程中大体的思路就是在审查元素中,先定位自己想要爬取信息的位置,找到div的id,再找到具体的标签,然后就获取到了标题。当然获取的是一个列表数据,不仅仅可以找出标题,也可以提取出来链接。具体代码和效果如下图所示:
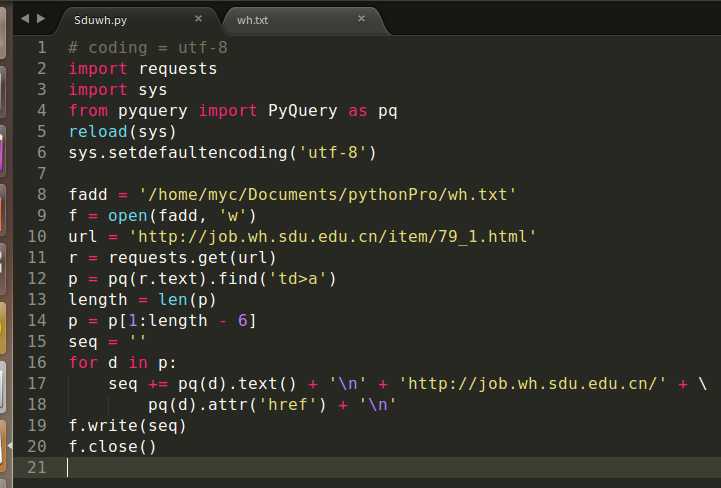

当然,和教程还是有一点不一样的,教程中是先定位了模块的id,但是我们学校的就业信息网列表那里并没有模块的id,所以尝试直接取获取链接文本所在模块的信息。获取得到的内容除了我想要的东西意外还有奇奇怪怪的东西,后来查了一下模块的id是唯一的,但是模块下的子名字是可以重复的,因为获取的是列表,并且信息的格式基本上是固定的,所以直接获取列表的一个子表就可以了,当然=,=不懂html的我是不了解具体原因的。。
这样就是静态的抓取了一个网页里面的部分文章标题及链接,但是想实现的是提醒更新的功能。很自然地一个想法就是拿爬下来的内容和之前的内容进行比较,没有更新的就直接忽略,有更新的话就把更新内容保存下来,最后只提醒更新内容就好了。正好python处理字符串还是比较人性化的,文件操作里面有f.readline(),同时可以直接进行字符串的比较,所以就拿爬下来的第一行数据和之前文件里的第一行数据进行比较,如果相同的话忽略本次爬取,不同的话循环比较,直到遇到相同的数据,把之前的数据存到本地,实现更新内容的动态提醒。最终实现了对三个网页,山东大学(威海)就业信息网的两个模块和哈尔滨工业大学(威海)的一个模块的数据提取。代码如下:


1 # coding = utf-8 2 # @ author : blueprintf 3 # @ E-mail : [email protected] 4 # @ version : 10/28 5 import requests 6 import sys 7 from pyquery import PyQuery as pq 8 reload(sys) 9 sys.setdefaultencoding(‘utf-8‘) 10 11 # output file init 12 fadd = ‘/home/myc/Documents/pythonPro/update.txt‘ 13 f = open(fadd, ‘w+‘) 14 f.truncate() 15 f.close() 16 17 # sduwh campus recruitment 18 url = ‘http://job.wh.sdu.edu.cn/item/79_1.html‘ 19 r = requests.get(url) 20 p = pq(r.text).find(‘td>a‘) 21 length = len(p) 22 p = p[1:length - 6] 23 check = pq(p[0]).text() + ‘\\n‘ 24 fadd = ‘/home/myc/Documents/pythonPro/wh.txt‘ 25 f = open(fadd, ‘r+‘) 26 exist = f.readline() 27 f.close() 28 if exist != check: 29 print ‘sduwh campus recruitment update‘ 30 seq = ‘‘ 31 for d in p: 32 tmp = pq(d).text() + ‘\\n‘ 33 if tmp == exist: 34 break 35 seq += pq(d).text() + ‘\\n‘ + ‘http://job.wh.sdu.edu.cn/‘ + 36 pq(d).attr(‘href‘) + ‘\\n‘ 37 38 fadd = ‘/home/myc/Documents/pythonPro/wh.txt‘ 39 f = open(fadd, ‘w‘) 40 f.write(seq) 41 f.close() 42 fadd = ‘/home/myc/Documents/pythonPro/update.txt‘ 43 f = open(fadd, ‘a‘) 44 f.write(seq) 45 f.close() 46 47 # sduwh employ information 48 url = ‘http://job.wh.sdu.edu.cn/item/80_1.html‘ 49 r = requests.get(url) 50 p = pq(r.text).find(‘td>a‘) 51 length = len(p) 52 p = p[0:length - 6] 53 check = pq(p[0]).text() + ‘\\n‘ 54 fadd = ‘/home/myc/Documents/pythonPro/whzp.txt‘ 55 f = open(fadd, ‘r+‘) 56 exist = f.readline() 57 f.close() 58 if exist != check: 59 print ‘sduwh employ information update‘ 60 seq = ‘‘ 61 for d in p: 62 tmp = pq(d).text() + ‘\\n‘ 63 if tmp == exist: 64 break 65 seq += pq(d).text() + ‘\\n‘ + ‘http://job.wh.sdu.edu.cn/‘ + 66 pq(d).attr(‘href‘) + ‘\\n‘ 67 fadd = ‘/home/myc/Documents/pythonPro/whzp.txt‘ 68 f = open(fadd, ‘w‘) 69 f.write(seq) 70 f.close() 71 fadd = ‘/home/myc/Documents/pythonPro/update.txt‘ 72 f = open(fadd, ‘a‘) 73 f.write(seq) 74 f.close() 75 76 # hitwh employ information 77 url = ‘http://job.hitwh.edu.cn/showmore.php?actiontype=5‘ 78 r = requests.get(url) 79 r.encoding = ‘gbk‘ 80 p = pq(r.text).find(‘#p2_c td>a‘) 81 length = len(p) 82 p = p[3:length] 83 check = pq(p[0]).text() + ‘\\n‘ 84 fadd = ‘/home/myc/Documents/pythonPro/hitwh.txt‘ 85 f = open(fadd, ‘r+‘) 86 exist = f.readline() 87 f.close() 88 if exist != check: 89 print ‘hitwh employ information update‘ 90 seq = ‘‘ 91 for d in p: 92 tmp = pq(d).text() + ‘\\n‘ 93 if tmp == exist: 94 break 95 seq += pq(d).text() + ‘\\n‘ + ‘http://job.hitwh.edu.cn/‘ + 96 pq(d).attr(‘href‘) + ‘\\n‘ 97 fadd = ‘/home/myc/Documents/pythonPro/hitwh.txt‘ 98 f = open(fadd, ‘w‘) 99 f.write(seq) 100 f.close() 101 fadd = ‘/home/myc/Documents/pythonPro/update.txt‘ 102 f = open(fadd, ‘a‘) 103 f.write(seq) 104 f.close()
因为对python语言不太熟悉,所以可能很多语法的写法并不像python工程师的写法,之后会系统地学习然后改过。
到这里还算比较顺利的,代码量不大,直接调库就实现了我想要的功能,一共用了三四个小时的样子,但是这样明显不能够满足我的需求,毕竟python是一个脚本文件,如果我想把它发给别人,那对方也必须要配置好python环境才可以运行。很自然的一个想法就是想把脚本文件转化成可执行文件(噩梦从此开始)。
从网上查了一下,还真有实现这个功能的软件,也是一个脚本文件的样子,最常用的有两个:py2exe和pyinstaller,都是针对python2的。一开始尝试在ubuntu下进行文件转换,但是没有成功,猜想是因为在ubuntu下没有exe这样的文件格式(有成功在ubuntu下转换的欢迎交流)。然后在windows下因为我的电脑之前装的是python3.5,尝试卸载重新装2.7.x的时候环境可能出了点问题,不能实现pip功能,cmd下载速度也奇慢无比,遂借了舍友的电脑从安装python开始做起(若干个小时过去了)。。。。
然后下载了py2exe和pyinstaller,分别进行了尝试。py2exe需要先自己写一个setup.py,写了个简单的但是报错缺少模块儿,尝试加失败,放弃。pyinstaller比较傻瓜,告诉他需要转成什么样的文件他就会帮你转,所以选择了这个。因为代码中用到了pyquery和requests两个包,所以就先下载这两个包,下载过程中pip报错,libxml2 not installed,下载了libxml2-python-2.7.7.win32-py2.7.exe,安装以后在Lib里面找到了libxml2,但是还是报错。。百度了好久也没有解决这个问题,有的说要先安装lxml,但是在安装高版本lxml的时候也会报这个错误。。所以就先安装了一个低版本的lxml,把pyquery包先装上了。
然后尝试使用pyinstaller进行编译,编译很顺利,但是编译完之后直接闪退。查了很久,也查了pyinstaller相关的介绍说明,看见Build文件夹下面有一个warn*.txt文件,里面missing了各种模块,于是开始一个一个安装模块,但是并没有什么卵用,绝望=,=。快睡觉的时候才想起来自己的老本行,能不能debug一下,发现虽然还是会闪退,但是可以确定是在import pyquery的时候闪退的。这时候感觉lxml是肯定必须要升级的了,后来从网上找了一个lxml的安装文件,安装过程中没有报错,安装了以后竟然真的可以运行了,感动。
但这个感动还是早了点,运行以后发现每次更新都会把所有数据全部输出一遍,而不是更新的那部分。后来才明白,windows下面和ubuntu下面的编码机制是不一样的。。OMG,给跪了,在ubuntu中,换行符是‘\\n‘,而在windows下,换行符是‘\\r\\n‘,在编解码方面也有一定的差别,可以参考链接。一开始还想要print一下看看差别,后来一直在报解码错误,真的是蜜汁错误,用的utf-8编码,结果报GBK的错误。后来发现有repr函数可以直接显示编码的内容,干脆就直接比较编码了,发现windows的utf-8编码在开始的时候会有一个u‘\\feff‘,猜可能是utf的编码标识符,所以用gbk去读的时候会错位读不出换行符?改完以后终于可以运行了,感动天感动滴。。
还有一个点需要注意一下,在用pyinstaller进行转换的时候,可能会有关联文件,比如说调用了某个数据文件之类的,这个时候可以在生成的spec文件data那里就行修改,加上数据文件的路径。当然程序生成的文件是不需要加在里面的。
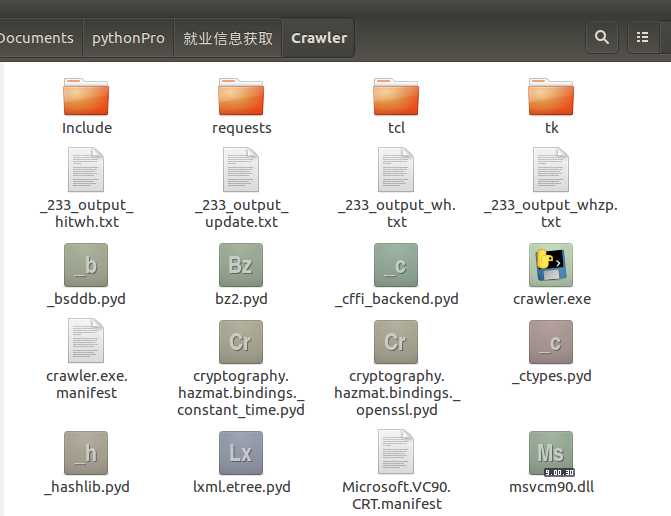
最后。。两天时间做出来的程序的结果,这个必须要贴图了,还是比较满意的,之后可以加入其他的网页链接,继续丰富这个小程序。感觉爬虫做起来还是比较好玩的,但是工程性要强很多。
-------------------------------------------------我是分界线--------------------------------------------------
感想:
1,以前觉得python是个很高级的语言,会的人应该非常厉害,但是自己去做的时候才发现所谓高级语言是因为集成的好,只要会调用就可以实现想要的功能,难点反而是在于能不能把想法转化成简洁,高效的程序。
2,爬虫这种东西,真的是很可怕,可以大大提高人的工作效率,但也是个双刃剑,后来体会了一下爬虫爬去baidu搜索的相关信息,真的是和人肉搜索一样的感觉,所以在网上的信息尽量不要用真名和易于检索的资料。当然,那些大公司手里面的数据真的会很恐怖。
3,工程性的东西真的真的真的好繁琐!
以上是关于[Python] 网络爬虫实战:网站链接的初级爬取的主要内容,如果未能解决你的问题,请参考以下文章
Python 网络爬虫实战:爬取南方周末新闻文章(带关键词筛选)