全链路压测(13):高可用和性能优化
Posted 梦想空间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全链路压测(13):高可用和性能优化相关的知识,希望对你有一定的参考价值。
转载:https://www.cnblogs.com/imyalost/p/16295324.html
大家好,这是全链路压测系列的第十三篇文章,也是倒数第二篇文章。
前面用了很多篇幅介绍了包括全链路压测的调研验证、落地实践前的准备工作细节、以及线上压测的一些注意事项。
到了这里基本上技术实践的东西就讲完了,这篇文章,我想和大家聊聊,关于性能优化和高可用,我的一些理解。
开始聊之前,我想回到写这个系列文章的开头,先聊聊全链路压测出现的原因和本质。
理解全链路压测
什么是全链路压测
基于实际的生产业务场景和系统环境,模拟海量的用户请求和数据,对整个业务链路进行各种场景的测试验证,持续发现并进行瓶颈调优,保障系统稳定性的一个技术工程。
全链路压测解决了什么问题
业务场景越发复杂化、海量数据冲击下,发现并解决业务系统的可用性、扩展性以及容错性问题。
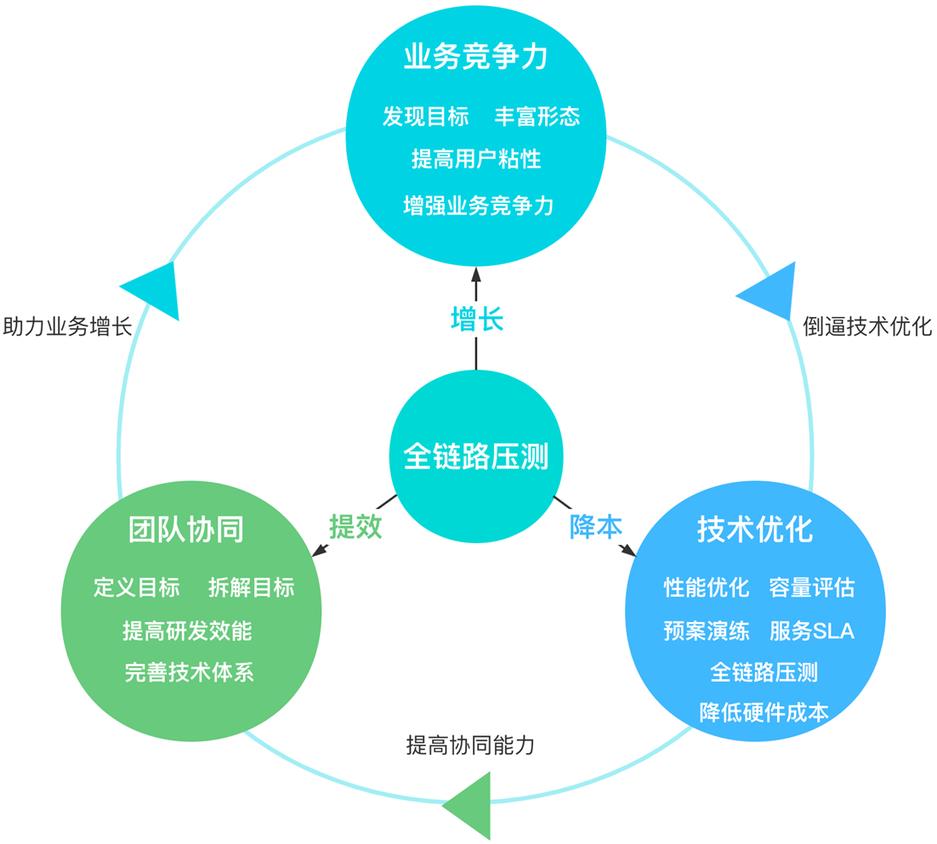
全链路压测创造了什么价值
- 业务角度:提升用户体验、增强业务竞争力、创造更多的业务价值;
- 技术角度:完善技术体系、提高服务可用性、更好的服务业务而体现自我价值;
- 管理角度:提高研发效能和团队协同沟通效率、降低技术实践和管理成本支出;
关于全链路压测的理解误区
- 全链路压测是一个技术工程,而非单纯的测试手段;
- 全链路压测只适用于部分企业和业务类型,而非一个银弹;
- 全链路压测的落地并非一蹴而就,需要较好的技术基础设施建设做保障;
- 落地全链路压测最大的挑战不是技术能力,而是企业的组织协调和沟通效率;
- 全链路压测的本质是尽量用较低的成本确保系统稳定可用,以保障系统在峰值流量下支撑业务目标达成;
高可用和性能优化
聊完了上面关于全链路压测的本质和目的、价值以及一些常见的理解误区之后,接下来我们谈谈关于服务高可用和性能优化的一些内容。
系统高可用和性能优化一直是技术领域热门的一个话题,无论是三高(高性能、高可用、高稳定),还是CAP(数据一致性、服务可用性、分区容错性),都强调了服务的性能和可用。
高可用四板斧
如何理解高可用
可用是一个名词,简单来讲就是系统既有的功能能否正常为用户提供服务;可用性是一个形容词,即系统的可用在某种评估标准下能得多少分。
那么如何衡量可用性?目前业内大多从下面几点指标来评估:
线上服务可用时常
服务可用时常即我们常说的SLA(即服务等级协议,全称:service level agreement)。SLA对互联网公司来说就是网站服务可用性的一个保证。
9越多代表全年服务可用时间越长服务更可靠,停机时间越短,反之亦然。服务可用性指标可以通过下面的例子来理解:
全年以365天做计算,看看几个9要停机多久时间才能达到!
1年 = 365天 = 8760小时;
99.9% = 8760 * 0.1% = 8760 * 0.001 = 8.76小时;
99.99%= 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟;
99.999% = 8760 * 0.00001 = 0.0876小时 = 0.0876 * 60 = 5.26分钟;
当然,服务可用时长还要区分核心业务和非核心业务,不同的业务造成的不可用影响程度也是不同的。
故障响应解决耗时
这一点目前业内有个口号是:1-5-15。什么意思呢,就是:
一分钟发现问题,5分钟定位问题,15分钟解决问题,线上业务恢复正常运营。
要做到上述的指标需要很强的技术能力以及不断的演练才能达到,主要是如下几点:
- 发现问题:强大完善灵敏的监控体系;
- 定位问题:对业务和技术实现的熟悉程度以及高效的定位分析工具;
- 解决问题:故障的自愈能力以及对异常情况的稳定性预案甚至故障演练;
故障导致的业务资损
这一点很好理解,即线上故障对业务造成的损失。这一点业内在故障定级评估复盘时,大多采用最近一天/一周同时段的业务营收来做对比,当然,其中还可能包括用户的客诉以及赔偿得成本支出等维度。
如何做到高可用
- 限流:控制访问应用的流量在系统承载范围内
- 在业务请求入口(网关)限流,避免内部互相调用放大流量;
- 限流是个演进状态,从连接池、IP、指定SQL到更细的层级粒度做限流;
- 每个调用层都做限流,每个应用先保证自己可用,对其他依赖调用要做到“零信任”;
- 降级:强依赖通过熔断做紧急处理,弱依赖提前主动降级
- 主动降级:提前进行风险识别,然后针对性的降级,可降低已知的风险;
- 紧急降级:假设出现重大的问题,才需要决策是否启用的方案(风险较大);
- 预案平台:预案平台的目的是留痕,方便后续把限流降级等配置恢复回来;
- 熔断:熔断下游强依赖的服务
- 双十一零点的前半小时, 做一个动态推送,把日志关掉;
- 真正流量来的时候,留一台机器来观察错误和异常的日志;
- 隔离:核心和非核心业务做隔离
身份识别和业务隔离案例如下:
- RPC group分组:假设有100个节点,40个给核心业务(交易),60个给其他业务;
- 业务身份:中台架构可通过业务身份把订单秒杀等应用打上标记,便于隔离区分;
PS:注意!无论是限流还是降级以及熔断和隔离,本质上对业务都是有损的。即在尽可能保障服务可用的情况下提供业务可用,保障业务目标的达成。这是一个需要不断验证和评估投入产出比的过程。
性能优化三板斧
聊完了高可用,接下来聊聊性能优化。
如何理解性能优化
- 性能优化的目标
在保持和降低系统99%RT的前提下,不断提高系统吞吐量,提高流量高峰时期的服务可用性。
- 性能优化的挑战
- 日益增长的用户量(带来访问量的提升,大数据量的存储和处理);
- 越来越多样的业务(业务的不断迭代和发展,会使其复杂性指数提升);
- 越来越复杂的系统(为了支撑业务迭代发展,系统架构会变得很复杂);
- 性能优化的路径
- 降低响应时间;
- 提高系统吞吐量;
- 提高服务可用性;
PS:三者关系在某些场景下互相矛盾冲突,不可兼得!
如何开展性能优化
首先要声明一点:性能优化没有边际,随着优化的范围越大细节越深,要投入的成本和精力就越大。
而且在实际工作中,很多时候是没有太多时间让我们去做细致的分析优化的。特别是在版本迭代业务交付deadline、倒排期情况下,按时交付往往是第一优先级。
我并不是提倡大家不注重系统性能的表现和优化,而是想说明一点:性能优化的成本和及时交付带来的业务价值之间需要做评估和平衡。
而且现在各种技术框架工具以及编码规范和测试验证的最佳实践不断涌现,在更重要的价值面前,要做到性能优化实际上是很简单的事情,就是下面的性能优化三板斧:
扩容:应用计算能力受限于硬件资源,只要应用服务具备弹性扩容的特点,完全可以用扩容来提升性能;
升配:应用计算能力受限于硬件资源,提升硬件资源的配置从某种程度上来说就是在提升应用服务的处理能力;
缓存:缓存的作用就是减少请求的访问链路和过程耗时,降低耗时就是在提升单位时间内应用服务的处理能力;
以上是关于全链路压测(13):高可用和性能优化的主要内容,如果未能解决你的问题,请参考以下文章