Python图像特征的音乐序列生成如何标记照片的特征
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python图像特征的音乐序列生成如何标记照片的特征相关的知识,希望对你有一定的参考价值。
目前我能想到的办法是这样的:
1,提取照片中的实体特征,借用某个pre-trained model进行tag标记。
2,将特征组合起来,形成一个bag-of-word model,然后将这个向量作为输入。进入CNN。
3,手动对照片贴标签,主要是对情感进行分类(如:安静、快乐,这样可以直观调节旋律)
4,将图片本身的这个特征向量,与情感标签一起作为旋律的生成参数。
首先要做的是提取照片中的实体特征。这是一个非常庞大的工程,需要很多的预训练。但是幸运地是,我手上的Azure付费订阅,可以支撑微软的Cognitive Service平台。
https://azure.microsoft.com/zh-cn/services/cognitive-services
不得不承认今年微软的Cognitive Service在功能上又有了一些强化,增加了QnA Maker、说话人识别等一系列很实用的API,为我之后的很多idea提供了方便,而且更重要的是,微软恰巧也强化了原来的计算机视觉API,现在的计算机视觉API相比之前的已经进化了很多。以前如果我放一个面包的照片,它最多返回一个“Food”标签。而现在,它不仅返回了Result分类结果,还返回了一大堆tag,请看下面两张图片:

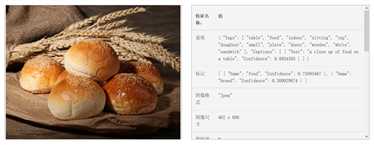
尽管最近微软缩减了各个俱乐部的经费,我还是要在这里大喊三声:
微软大法好!
微软大法好!
微软大法好!
好了,那么这个tag就处理完毕。接下来我们要处理的是bag-of-word model。这个思想很简单,想象一个向量空间,我们把所有的词汇都映射成一个向量,那么这个向量的特征和这个词的特征是挂钩的,相似的词语会很近,而相反的词语会几乎线性相关。目前将词转换为向量的成熟方案是word2vec,英文上最出名、实用的应该是C&W 2008模型,中文方面没有业界知名的模型,但是我推荐这个:
http://spaces.ac.cn/archives/4304/

我个人觉得非常地好用。
那么我以C&W 2008模型举例,取词向量dimension = 50,那么我们将所有的向量相加(反正没有相互联系),得到一个综合向量,再作为卷积网络的输出即可。
卷积神经网络的结构我之后再继续讲述,最后讲一下怎么对图片手动贴标签。在我的设想中,这个标签应该是直观的情感标签,是一个人类看到这张图片所有的直觉反应。
所以我设想,将标签设为:生、老、病、死、爱别离、怨憎会、求不得、五阴炽盛
平静、快乐、悲伤、惊奇、厌恶、愤怒……
之后通过神经网络进行multi-labeled classification。
以上是关于Python图像特征的音乐序列生成如何标记照片的特征的主要内容,如果未能解决你的问题,请参考以下文章
Python图像特征的音乐序列生成如何生成旋律(大纲),以及整个项目的全部流程
Python图像特征的音乐序列生成深度卷积网络,以及网络核心