Python--爬虫豆瓣250电影网站
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python--爬虫豆瓣250电影网站相关的知识,希望对你有一定的参考价值。
首先来个小知识点,利用非贪婪匹配出我们的目标字符串:<div>yuan<img></div>
看代码:
s="<div>yuan<img></div><a href=""></div>" ret=re.findall("<div>.*?</div>",s) print(ret) 运行结果: [‘<div>yuan<img></div>‘]
知道这点之后,我们就可以开始爬虫网站了。
爬取网站:https://movie.douban.com/top250
想要爬取的内容:电影名称、排名、评分等。
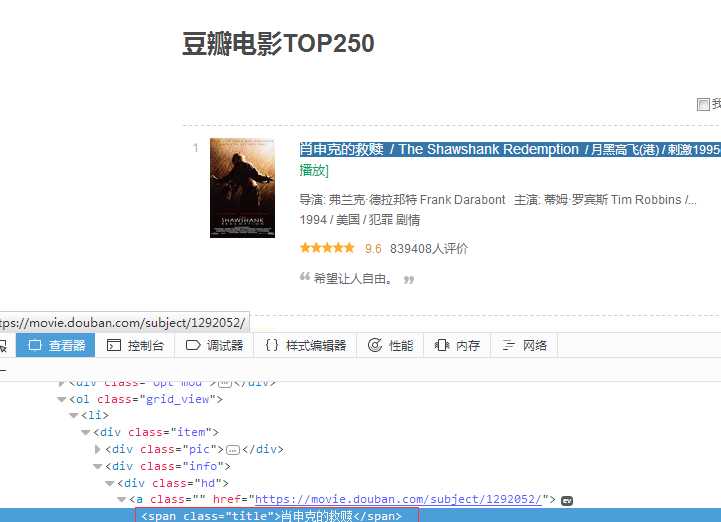
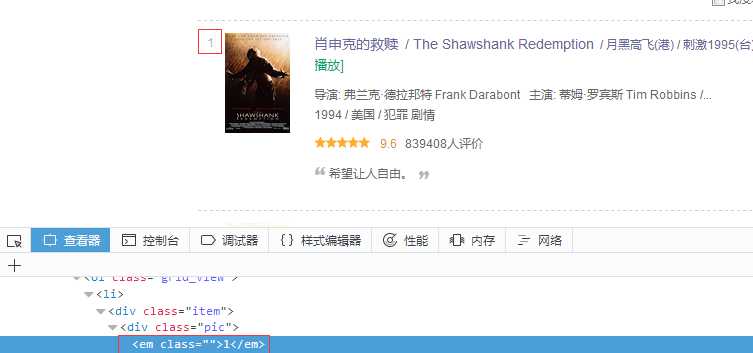
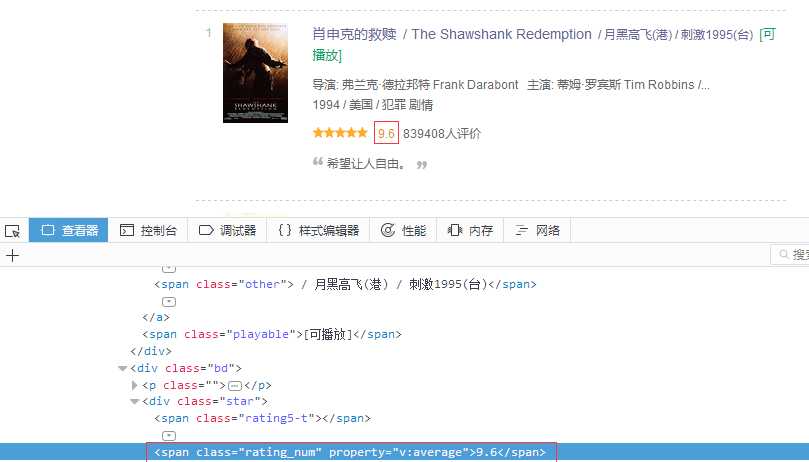
其中<em class="">1</em>代表排名,<span class="title">肖申克的救赎</span>代表电影名,其他信息的含义也很容易能看出来。
实现代码如下:
import requests import re def get_page(): responce_str=requests.get("https://movie.douban.com/top250?start=0&filter=") return responce_str.text def run(): responce=get_page() obj=re.compile(‘<div class="item">.*?<em class="">(.*?)</em>.*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?</div>‘,re.S) ret=obj.findall(responce) print(ret) run() 运行结果: [(‘1‘, ‘肖申克的救赎‘, ‘9.6‘), (‘2‘, ‘霸王别姬‘, ‘9.5‘), (‘3‘, ‘这个杀手不太冷‘, ‘9.4‘), (‘4‘, ‘阿甘正传‘, ‘9.4‘), (‘5‘, ‘美丽人生‘, ‘9.5‘), (‘6‘, ‘千与千寻‘, ‘9.2‘), (‘7‘, ‘辛德勒的名单‘, ‘9.4‘), (‘8‘, ‘泰坦尼克号‘, ‘9.2‘), (‘9‘, ‘盗梦空间‘, ‘9.2‘), (‘10‘, ‘机器人总动员‘, ‘9.3‘), (‘11‘, ‘海上钢琴师‘, ‘9.2‘), (‘12‘, ‘三傻大闹宝莱坞‘, ‘9.1‘), (‘13‘, ‘忠犬八公的故事‘, ‘9.2‘), (‘14‘, ‘放牛班的春天‘, ‘9.2‘), (‘15‘, ‘大话西游之大圣娶亲‘, ‘9.2‘), (‘16‘, ‘教父‘, ‘9.2‘), (‘17‘, ‘龙猫‘, ‘9.1‘), (‘18‘, ‘楚门的世界‘, ‘9.0‘), (‘19‘, ‘乱世佳人‘, ‘9.2‘), (‘20‘, ‘天堂电影院‘, ‘9.1‘), (‘21‘, ‘当幸福来敲门‘, ‘8.9‘), (‘22‘, ‘触不可及‘, ‘9.1‘), (‘23‘, ‘搏击俱乐部‘, ‘9.0‘), (‘24‘, ‘熔炉‘, ‘9.2‘), (‘25‘, ‘无间道‘, ‘9.0‘)]
接下来让我们增加点内容:
responce = re.compile(‘<div.*?class="item">.*?<div.*?class="pic">.*?‘ + ‘<em.*?class="">(.*?)</em>.*?‘ + ‘<div.*?class="info">.*?<span.*?class="title">(.*?)‘ + ‘</span>.*?<span.*?class="title">(.*?)</span>.*?‘ + ‘<span.*?class="other">(.*?)</span>.*?</a>.*?‘ + ‘<div.*?class="bd">.*?<p.*?class="">.*?‘ + ‘导演: (.*?) ‘ + ‘主演: (.*?)<br>‘ + ‘(.*?) / (.*?) / ‘ + ‘(.*?)</p>‘ + ‘.*?<div.*?class="star">.*?<em>(.*?)</em>‘ + ‘.*?<span>(.*?)人评价</span>.*?<p.*?class="quote">.*?‘ + ‘<span.*?class="inq">(.*?)</span>.*?</p>‘, re.S)
爬取内容:电影名称、排名、评分、导演、短评
import requests import re import json def run(): start_page = 0 while start_page <= 225: url = ‘https://movie.douban.com/top250?start=‘ + str(start_page) responce = requests.get(url).text print(responce) obj = re.compile(‘<div class="item">.*?<em class="">(?P<id>.*?)</em>.*?<span class="title">(?P<film>.*?)</span>.*?<p class="">.*?导演:(?P<director>.*?) .*?</p>.*?<span class="rating_num".*?>(?P<rank>.*?)</span>.*?<span class.*?>(?P<review>.*?)</span>.*?</div>‘, re.S) ret=obj.findall(responce) print(ret) l=[{‘id‘:i[0],‘film‘:i[1],‘director‘:i[2],‘rank‘:i[3],‘review‘:i[4]} for i in ret] print(l) for i in l: with open(‘douban.txt‘,‘a+‘,encoding=‘utf-8‘) as f: f.write(json.dumps(i,ensure_ascii=False)) f.write(‘\\n‘) start_page += 25 run()
文档效果截图:

configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
来看一个好多软件的常见文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {‘ServerAliveInterval‘: ‘45‘, ‘Compression‘: ‘yes‘, ‘CompressionLevel‘: ‘9‘, ‘ForwardX11‘:‘yes‘ } config[‘bitbucket.org‘] = {‘User‘:‘hg‘} config[‘topsecret.server.com‘] = {‘Host Port‘:‘50022‘,‘ForwardX11‘:‘no‘} with open(‘example.ini‘, ‘w‘) as configfile: config.write(configfile)
查找文件
import configparser config = configparser.ConfigParser() #---------------------------查找文件内容,基于字典的形式 print(config.sections()) # [] config.read(‘example.ini‘) print(config.sections()) # [‘bitbucket.org‘, ‘topsecret.server.com‘] print(‘bytebong.com‘ in config) # False print(‘bitbucket.org‘ in config) # True print(config[‘bitbucket.org‘]["user"]) # hg print(config[‘DEFAULT‘][‘Compression‘]) #yes print(config[‘topsecret.server.com‘][‘ForwardX11‘]) #no print(config[‘bitbucket.org‘]) #<Section: bitbucket.org> for key in config[‘bitbucket.org‘]: # 注意,有default会默认default的键 print(key) print(config.options(‘bitbucket.org‘)) # 同for循环,找到‘bitbucket.org‘下所有键 print(config.items(‘bitbucket.org‘)) #找到‘bitbucket.org‘下所有键值对 print(config.get(‘bitbucket.org‘,‘compression‘)) # yes get方法取深层嵌套的值
增删改操作
import configparser config = configparser.ConfigParser() config.read(‘example.ini‘) config.add_section(‘yuan‘) config.remove_section(‘bitbucket.org‘) config.remove_option(‘topsecret.server.com‘,"forwardx11") config.set(‘topsecret.server.com‘,‘k1‘,‘11111‘) config.set(‘yuan‘,‘k2‘,‘22222‘) config.write(open(‘new2.ini‘, "w"))
subprocess模块
当我们需要调用系统的命令的时候,最先考虑的os模块。用os.system()和os.popen()来进行操作。但是这两个命令过于简单,不能完成一些复杂的操作,如给运行的命令提供输入或者读取命令的输出,判断该命令的运行状态,管理多个命令的并行等等。这时subprocess中的Popen命令就能有效的完成我们需要的操作。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes.
This module intends to replace several other, older modules and functions, such as: os.system、os.spawn*、os.popen*、popen2.*、commands.*
这个模块只一个类:Popen。
简单命令
import subprocess # 创建一个新的进程,与主进程不同步 if in win: s=subprocess.Popen(‘dir‘,shell=True) s=subprocess.Popen(‘ls‘) s.wait() # s是Popen的一个实例对象 print(‘ending...‘)
命令带参数
linux:
import subprocess subprocess.Popen(‘ls -l‘,shell=True) #subprocess.Popen([‘ls‘,‘-l‘])
控制子进程
当我们想要更个性化我们的需求的时候,就要转向Popen类,该类生成的对象用来代表子进程。刚才我们使用到了一个wait方法
此外,你还可以在父进程中对子进程进行其它操作:
s.poll() # 检查子进程状态
s.kill() # 终止子进程
s.send_signal() # 向子进程发送信号
s.terminate() # 终止子进程
s.pid:子进程号
子进程的文本流控制
可以在Popen()建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE将多个子进程的输入和输出连接在一起,构成管道(pipe):
import subprocess # s1 = subprocess.Popen(["ls","-l"], stdout=subprocess.PIPE) # print(s1.stdout.read()) #s2.communicate() s1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE) s2 = subprocess.Popen(["grep","0:0"],stdin=s1.stdout, stdout=subprocess.PIPE) out = s2.communicate() print(out)
ubprocess.PIPE实际上为文本流提供一个缓存区。s1的stdout将文本输出到缓存区,随后s2的stdin从该PIPE中将文本读取走。s2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
注意:communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成
快捷API
‘‘‘ subprocess.call() 父进程等待子进程完成 返回退出信息(returncode,相当于Linux exit code) subprocess.check_call() 父进程等待子进程完成 返回0,检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含 有returncode属性,可用try…except…来检查 subprocess.check_output() 父进程等待子进程完成 返回子进程向标准输出的输出结果 检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含 有returncode属性和output属性,output属性为标准输出的输出结果,可用try…except…来检查。 ‘‘‘
以上是关于Python--爬虫豆瓣250电影网站的主要内容,如果未能解决你的问题,请参考以下文章