Python异常处理和进程线程-day09
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python异常处理和进程线程-day09相关的知识,希望对你有一定的参考价值。
写在前面
上课第九天,打卡:
最坏的结果,不过是大器晚成;
一、异常处理
- 1.语法错误导致的异常
- 这种错误,根本过不了python解释器的语法检测,必须在程序运行前就修正;
- 2.逻辑上的异常
- 即逻辑错误,例如除零错误;
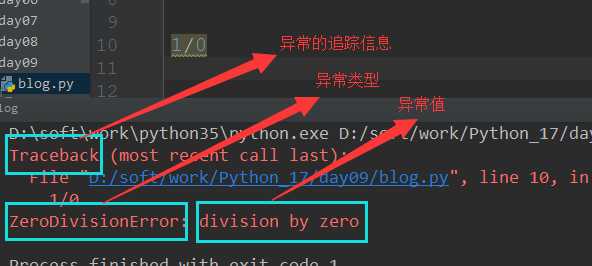
- 异常相关信息:异常的追踪信息 + 异常类型 + 异常值
- 异常种类


1 ArithmeticError 2 AssertionError 3 AttributeError 4 BaseException 5 BufferError 6 BytesWarning 7 DeprecationWarning 8 EnvironmentError 9 EOFError 10 Exception 11 FloatingPointError 12 FutureWarning 13 GeneratorExit 14 ImportError 15 ImportWarning 16 IndentationError 17 IndexError 18 IOError 19 KeyboardInterrupt 20 KeyError 21 LookupError 22 MemoryError 23 NameError 24 NotImplementedError 25 OSError 26 OverflowError 27 PendingDeprecationWarning 28 ReferenceError 29 RuntimeError 30 RuntimeWarning 31 StandardError 32 StopIteration 33 SyntaxError 34 SyntaxWarning 35 SystemError 36 SystemExit 37 TabError 38 TypeError 39 UnboundLocalError 40 UnicodeDecodeError 41 UnicodeEncodeError 42 UnicodeError 43 UnicodeTranslateError 44 UnicodeWarning 45 UserWarning 46 ValueError 47 Warning 48 ZeroDivisionError
- 异常示例:
# IndexError: list index out of range
list1 = [1,2]
list1[7]
# KeyError: ‘k9‘
dict1 = {
‘k1‘:‘v1‘,
‘k2‘:‘v2‘,
}
dict1[‘k9‘]
# ValueError: invalid literal for int() with base 10: ‘standby‘
str = ‘standby‘
int(str)
...
- 3.异常处理
- try...except... (可以写多个except)
- 从上向下匹配,匹配到了就不再匹配下面的except,类似于 iptables
try:
# msg=input(‘>>:‘)
# int(msg) #ValueError
print(x) #NameError
d={‘a‘:1}
d[‘b‘] #KeyError
l=[1,2]
l[10] #IndexError
1+‘asdfsadfasdf‘ #TypeError
except ValueError as e:
print(‘ValueError: %s‘ % e)
except NameError as e:
print(‘NameError: %s‘ % e)
except KeyError as e:
print(e)
print(‘=============>‘)
- 万能异常 Exception
try:
# d={‘a‘:1}
# d[‘b‘] #KeyError
l=[1,2]
l[10] #IndexError
1+‘asdfsadfasdf‘ #TypeError
except Exception as e:
print(‘捕获到异常,异常类型:%s,异常值:%s‘ % (type(e),e))
print(‘=============>‘)
- try...except...else...finally... (finally 里面主要是做一些清理工作)
try:
# 1+‘asdfsadfasdf‘ #TypeError
print(‘aaaaaa‘)
except Exception as e:
print(‘捕获到异常,异常类型:%s,异常值:%s‘ % (type(e), e))
else:
print(‘没有异常时发生会执行‘)
finally:
print(‘有没有异常都会执行‘)
- 4.异常扩展
- 主动抛出异常
try:
raise TypeError(‘类型错误‘)
except Exception as e:
print(e)
- 自定义异常类型
class standbyException(BaseException):
def __init__(self,msg):
self.msg=msg
def __str__(self):
return self.msg
try:
raise standbyException(‘--->> 自定义异常类型‘)
except standbyException as e:
print(e)
- 断言 assert
# 待补充...
二、操作系统
- 0.参考:操作系统简介
- 1.基础概念
- 1.精简的说的话,操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序;
- 2.操作系统管理硬件,提供系统调用(接口,比方说:文件);对资源请求进行有序调度处理;
- 3.操作系统处在用户应用程序和计算机硬件之间,本质也是一个软件
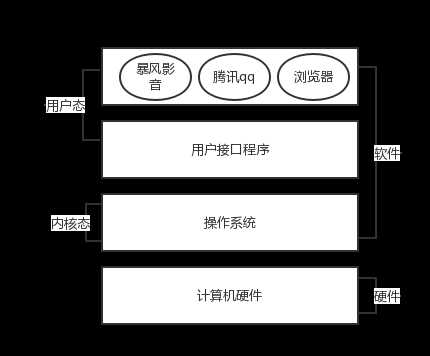
- 4.操作系统由操作系统的内核(运行于内核态,管理硬件资源)以及系统调用(运行于用户态,为应用程序员写的应用程序提供系统调用接口)两部分组成,所以,单纯的说操作系统是运行于内核态的,是不准确的。
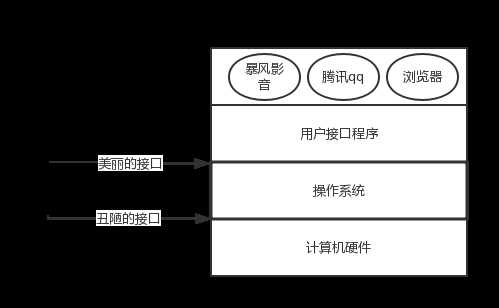
# 1.隔离复杂度,提供简单易用的接口 隐藏了丑陋的硬件调用接口,为应用程序员提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口)。 应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可。 比如,磁盘资源的抽象是文件系统(C盘,D盘,E盘...下的目录及文件), 有了文件的概念,我们直接打开文件,读或者写就可以了, 无需关心记录是否应该使用修正的调频记录方式,以及当前电机的状态等细节
# 2.将应用程序对硬件资源的竞态请求变得有序化 例如:很多应用软件其实是共享一套计算机硬件, 比方说有可能有三个应用程序同时需要申请打印机来输出内容, 那么a程序竞争到了打印机资源就打印, 然后可能是b竞争到打印机资源,也可能是c,这就导致了无序; 打印机可能打印一段a的内容然后又去打印c..., 操作系统的一个功能就是将这种无序变得有序;
- 2.相关概念
- 1.批处理
- 把一堆人的输入攒成一大波输入;把一堆人的输出攒成一大波输出;节省了机时;
- 2.多道程序设计
- 空间上的复用
- 将内存分为几部分,每个部分放入一个程序,这样,同一时间内存中就有了多道程序;
空间上的复用最大的问题是: 程序之间的内存必须分割,这种分割需要在硬件层面实现,由操作系统控制。 如果内存彼此不分割,则一个程序可以访问另外一个程序的内存, 1.首先丧失的是安全性: 比如你的qq程序可以访问操作系统的内存,这意味着你的qq可以拿到操作系统的所有权限。 2.其次丧失的是稳定性: 某个程序崩溃时有可能把别的程序的内存也给回收了, 比方说把操作系统的内存给回收了,则操作系统崩溃。
- 时间上的复用
- 快速的上下文切换
当一个资源在时间上复用时,不同的程序或用户轮流使用它,第一个程序获取该资源使用结束后,在轮到第二个。。。第三个。。。 例如:只有一个cpu,多个程序需要在该cpu上运行,操作系统先把cpu分给第一个程序; 在这个程序运行的足够长的时间(时间长短由操作系统的算法说了算)或者遇到了I/O阻塞,操作系统则把cpu分配给下一个程序; 以此类推,直到第一个程序重新被分配到了cpu然后再次运行,由于cpu的切换速度很快,给用户的感觉就是这些程序是同时运行的,或者说是并发的,或者说是伪并行的。 至于资源如何实现时间复用,或者说谁应该是下一个要运行的程序,以及一个任务需要运行多长时间,这些都是操作系统的工作。 当一个程序在等待I/O时,另一个程序可以使用cpu,如果内存中可以同时存放足够多的作业,则cpu的利用率可以接近100%;
- 3.分时操作系统
把处理机的运行时间分成很短的时间片,按时间片轮流把处理机分配给各联机作业使用; 分时操作系统,在多个程序之间切换,按时间片切换; 第三代计算机广泛采用了必须的保护硬件(程序之间的内存彼此隔离)之后,分时系统才开始流行;
三、进程
- 0.参考:Cpython解释器支持的进程与线程
- 1.进程的概念
- 进程:正在进行的一个过程或者说一个任务。而负责执行任务则是cpu;起源于操作系统,是操作系统最核心的概念;
- 程序仅仅只是一堆代码而已,而进程指的是程序的运行过程;
- 同一个程序执行两次,那也是两个进程,比如打开暴风影音,虽然都是同一个软件,但是一个可以播放西游记,一个可以播放天龙八部;
An executing instance of a program is called a process. Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads. 程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。 程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。 在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。 进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
- 2.并发与并行
- 1.并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发);
- 2.并行:同时运行,只有具备多个cpu才能实现真正意义上的并行;
- 单核下,可以利用多道技术;多个核,每个核也都可以利用多道技术(多道技术是针对单核而言的)
有四个核,六个任务,这样同一时间有四个任务被执行,假设分别被分配给了cpu1,cpu2,cpu3,cpu4; 一旦任务1遇到I/O就被迫中断执行,此时任务5就拿到cpu1的时间片去执行,这就是单核下的多道技术; 而一旦任务1的I/O结束了,操作系统会重新调用它; (需知进程的调度、分配给哪个cpu运行,由操作系统说了算),可能被分配给四个cpu中的任意一个去执行
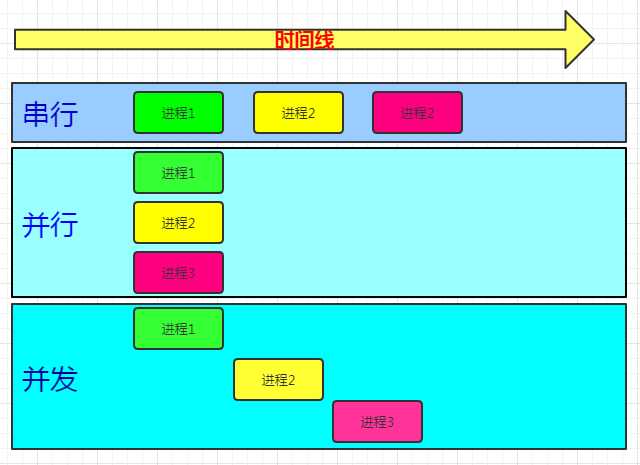
多道技术: 内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个, 使每个进程各自运行几十或几百毫秒; 这样,虽然在某一个瞬间,一个cpu只能执行一个任务, 但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发, 以此来区分多处理器操作系统的真正硬件并行(多个cpu共享同一个物理内存)
- 3.同步和异步
同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息, 那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去; 异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。 当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。 同步:打电话
异步:发短息、MySQL主从复制
- 4.进程的创建
1. 在UNIX中该系统调用是:fork; fork会创建一个与父进程一模一样的副本, 二者有相同的存储映像、同样的环境字符串和同样的打开文件; (在shell解释器进程中,执行一个命令就会创建一个子进程) 2. 在windows中该系统调用是:CreateProcess, CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
关于创建的子进程,UNIX和windows 1.相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离), 任何一个进程的在其地址空间中的修改都不会影响到另外一个进程; 2.不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本, 提示:子进程和父进程是可以有只读的共享内存区的。 但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
- 创建进程示例1:
# Windows上调用Process,可执行代码一定要放到 __main__ 里
from multiprocessing import Process
import time,random
def func(name):
print(‘%s is running...‘ % name)
# time.sleep(random.randint(1,3))
time.sleep(1)
print(‘%s run end.‘ % name)
if __name__ == ‘__main__‘:
# p1 = Process(target=func,args=(‘standby‘,))
p1 = Process(target=func,args=(‘standby‘,),name=‘sub-P1‘)
p1.start()
print(p1.name)
print(‘Parent running‘)
time.sleep(1)
print(‘Parent run end‘)
---
sub-P1
Parent running
standby is running...
Parent run end
standby run end.
- 创建进程示例2:
# 继承Process类
from multiprocessing import Process
import time, random
class Foo(Process):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(‘%s is running...‘ % self.name)
# time.sleep(random.randint(1,3))
time.sleep(1)
print(‘%s run end.‘ % self.name)
if __name__ == ‘__main__‘:
p1 = Foo(‘standby‘)
p1.start()
print(‘Parent running...‘)
time.sleep(1)
print(‘Parent run end.‘)
---
Parent running...
standby is running...
Parent run end.
standby run end.
- Process类
- 1.参数介绍
Process([group [, target [, name [, args [, kwargs]]]]])
由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
group 参数未使用,值始终为None
target 表示调用对象,即子进程要执行的任务
args 表示调用对象的位置参数元组,args=(1,2,‘egon‘,)
kwargs 表示调用对象的字典,kwargs={‘name‘:‘egon‘,‘age‘:18}
name 为子进程的名称
- 2.方法介绍
p.start() 启动进程,并调用该子进程中的p.run() p.run() 进程启动时运行的方法,正是它去调用target指定的函数, 我们自定义类的类中一定要实现该方法 p.terminate() 强制终止进程p,不会进行任何清理操作, 如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。 如果p还保存了一个锁那么也将不会被释放,进而导致死锁 p.is_alive() 如果p仍然运行,返回True p.join([timeout]) hold住的是主进程 主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。 timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程, 而不能join住run开启的进程
- 3.属性介绍
p.daemon 默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止, 并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 p.name:进程的名称 p.pid:进程的pid p.exitcode 进程在运行时为None、如果为–N,表示被信号N结束(了解即可) p.authkey 进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。 这个键的用途是为涉及网络连接的底层进程间通信提供安全性, 这类连接只有在具有相同的身份验证键时才能成功(了解即可)
- 5.进程的状态
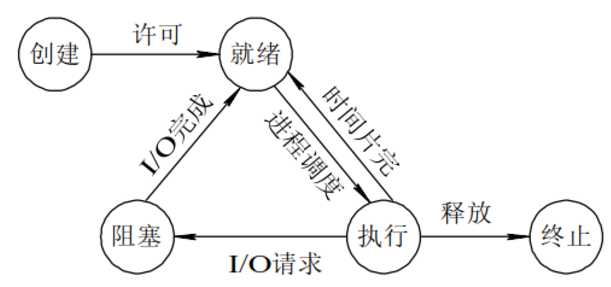
就绪状态:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行;
如果进程运行时间片使用完也会进入就绪状态; 执行状态:进程处于就绪状态被调度后,进程进入执行状态; 阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞; 在满足请求时进入就绪状态等待系统调用;
其实在两种情况下会导致一个进程在逻辑上不能运行: 1. 进程挂起是自身原因,遇到I/O阻塞,便要让出CPU让其他进程去执行,这样保证CPU一直在工作 2. 与进程无关,是操作系统层面,可能会因为一个进程占用时间过多,或者优先级等原因,而调用其他的进程去使用CPU。
四、线程
- 为什么要有线程?
有了进程为什么还要线程? 进程有很多优点,它提供了多道编程, 让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。 很多人就不理解了,既然进程这么优秀,为什么还要线程呢? 其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上: 1.进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。 2.进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起; 即使进程中有些工作不依赖于输入的数据,也将无法执行。
- 线程示例:
进程与进程之间的资源是隔离的;
一个进程里的多个线程共享进程的资源;
例子:编译一个文档,有三个功能,接收用户输入+格式化+定期保存
1.用三个进程实现;但进程间数据是隔离的,这样就需要维护三份资源数据;
2.用1个进程挂三个线程实现,三个线程共享一份资源;
- 线程是什么?
- 进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位;
- 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位;
- 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务;
- 进程之间是竞争关系,线程之间是协作关系;
A thread is an execution context, which is all the information a CPU needs to execute a stream of instructions. Suppose you‘re reading a book, and you want to take a break right now, but you want to be able to come back and resume reading from the exact point where you stopped. One way to achieve that is by jotting down the page number, line number, and word number. So your execution context for reading a book is these 3 numbers. If you have a roommate, and she‘s using the same technique, she can take the book while you‘re not using it, and resume reading from where she stopped. Then you can take it back, and resume it from where you were. Threads work in the same way. A CPU is giving you the illusion that it‘s doing multiple computations at the same time. It does that by spending a bit of time on each computation. It can do that because it has an execution context for each computation. Just like you can share a book with your friend, many tasks can share a CPU. On a more technical level, an execution context (therefore a thread) consists of the values of the CPU‘s registers. Last: threads are different from processes. A thread is a context of execution, while a process is a bunch of resources associated with a computation. A process can have one or many threads. Clarification: the resources associated with a process include memory pages (all the threads in a process have the same view of the memory), file descriptors (e.g., open sockets), and security credentials (e.g., the ID of the user who started the process).
- 线程和进程的区别
# 1 Threads share the address space of the process that created it; Processes have their own address space. # 2 Threads have direct access to the data segment of its process; Processes have their own copy of the data segment of the parent process. # 3 Threads can directly communicate with other threads of its process; Processes must use interprocess communication to communicate with sibling processes. # 4 New threads are easily created; New processes require duplication of the parent process. # 5 Threads can exercise considerable control over threads of the same process; Processes can only exercise control over child processes. # 6 Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; Changes to the parent process does not affect child processes.
- 创建进程的开销要远大于创建线程的开销;
四、多线程和多进程
五、进程池
六、进程间通信
七、生产者消费者模型
八、队列和堆栈
九、进程同步
十、paramiko模块
Paramiko is a Python (2.6+, 3.3+) implementation of the SSHv2 protocol [1], providing both client and server functionality. While it leverages a Python C extension for low level cryptography (Cryptography), Paramiko itself is a pure Python interface around SSH networking concepts.
- paramiko是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接。
1 __all__ = [ 2 ‘Transport‘, 3 ‘SSHClient‘, 4 ‘MissingHostKeyPolicy‘, 5 ‘AutoAddPolicy‘, 6 ‘RejectPolicy‘, 7 ‘WarningPolicy‘, 8 ‘SecurityOptions‘, 9 ‘SubsystemHandler‘, 10 ‘Channel‘, 11 ‘PKey‘, 12 ‘RSAKey‘, 13 ‘DSSKey‘, 14 ‘Message‘, 15 ‘SSHException‘, 16 ‘AuthenticationException‘, 17 ‘PasswordRequiredException‘, 18 ‘BadAuthenticationType‘, 19 ‘ChannelException‘, 20 ‘BadHostKeyException‘, 21 ‘ProxyCommand‘, 22 ‘ProxyCommandFailure‘, 23 ‘SFTP‘, 24 ‘SFTPFile‘, 25 ‘SFTPHandle‘, 26 ‘SFTPClient‘, 27 ‘SFTPServer‘, 28 ‘SFTPError‘, 29 ‘SFTPAttributes‘, 30 ‘SFTPServerInterface‘, 31 ‘ServerInterface‘, 32 ‘BufferedFile‘, 33 ‘Agent‘, 34 ‘AgentKey‘, 35 ‘HostKeys‘, 36 ‘SSHConfig‘, 37 ‘util‘, 38 ‘io_sleep‘, 39 ]
- 实例1:密码验证登录主机,远程执行命令
import paramiko
IP = ‘10.0.0.9‘
PORT = 22
USER = ‘root‘
PASSWORD = ‘123456.‘
ssh_conn = paramiko.SSHClient()
ssh_conn.set_missing_host_key_policy(paramiko.AutoAddPolicy())
try:
ssh_conn.connect(IP,PORT,USER,PASSWORD,timeout=3)
except Exception as e:
print(‘连接失败:%s‘ % e)
while True:
cmd = input(‘Input cmd, q/Q to exit.>>>\\t‘).strip()
if ‘Q‘ == cmd.upper():
print(‘Bye...‘)
break
stdin,stdout,stderr = ssh_conn.exec_command(cmd)
# print(stdin.read())
res = stderr.read().decode(‘utf-8‘)
if not res:
res = stdout.read().decode(‘utf-8‘)
print(res)
ssh_conn.close()
- 实例2:密码验证登录主机,执行ftp上传下载操作
# 下载到本地 import paramiko t = paramiko.Transport((‘10.0.0.9‘,22)) t.connect(username=‘root‘,password=‘123456.‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.get(r‘/data/pass.txt‘,‘1.txt‘) t.close() # 上传到远端服务器 import paramiko t = paramiko.Transport((‘10.0.0.9‘,22)) t.connect(username=‘root‘,password=‘123456.‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.put(r‘D:\\soft\\work\\Python_17\\day09\\paramiko_demo.py‘,‘/data/paramiko_demo.py‘) # sftp.get(r‘/data/pass.txt‘,‘1.txt‘) t.close()
- 实例3:秘钥验证登录远程主机,执行命令
参见:Pool多进程示例
十、Python GIL
参考:http://www.dabeaz.com/python/UnderstandingGIL.pdf
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
- GIL并不是Python的特性,Python完全可以不依赖于GIL;
十一、扩展
- 1.列表生成式
- 2.os.cpu_count()
- 3.
十一、day09课后作业
作业要求:
题目:简单主机批量管理工具
需求:
- 主机分组
- 主机信息配置文件用configparser解析
- 可批量执行命令、发送文件,结果实时返回,执行格式如下
- batch_run -h h1,h2,h3 -g web_clusters,db_servers -cmd "df -h"
- batch_scp -h h1,h2,h3 -g web_clusters,db_servers -action put -local test.py -remote /tmp/
- 主机用户名密码、端口可以不同
- 执行远程命令使用paramiko模块
- 批量命令需使用multiprocessing并发
代码实现:
以上是关于Python异常处理和进程线程-day09的主要内容,如果未能解决你的问题,请参考以下文章