Python爬虫从入门到放弃之 关于深度优先和广度优先
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫从入门到放弃之 关于深度优先和广度优先相关的知识,希望对你有一定的参考价值。
- 网站的树结构
- 深度优先算法和实现
- 广度优先算法和实现
网站的树结构
通过伯乐在线网站为例子:
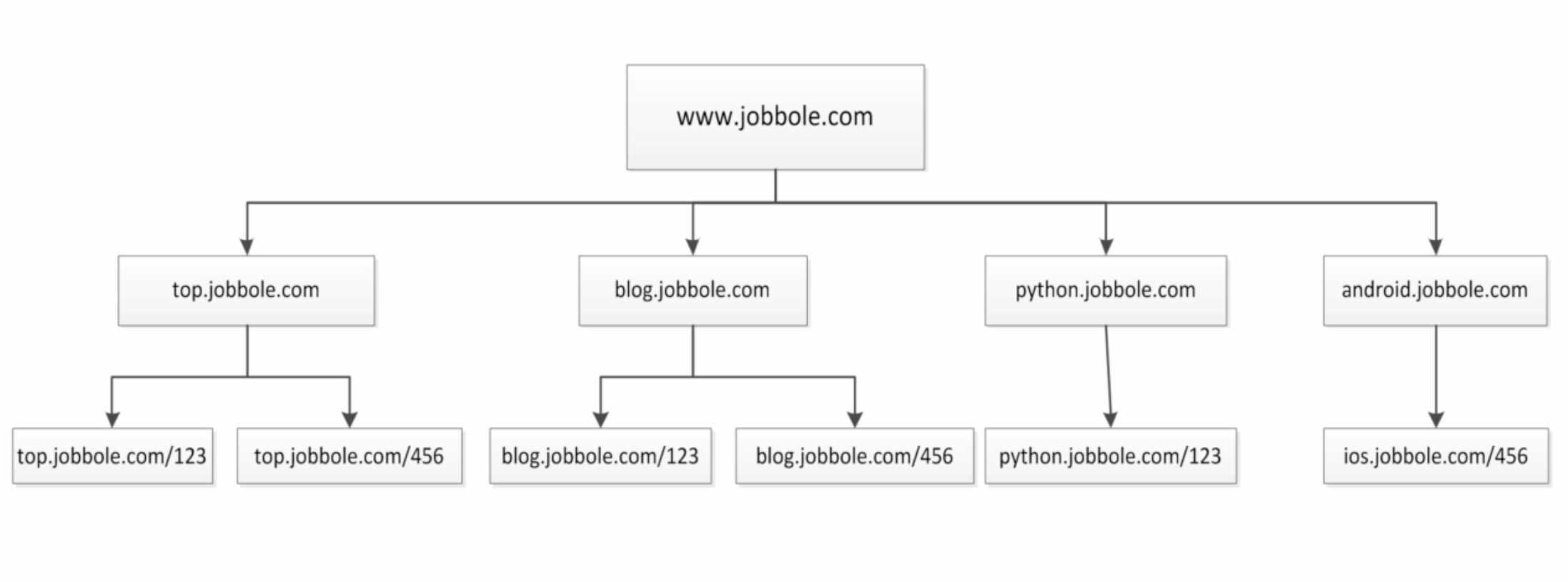
并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据的时候就会涉及到去重的问题,我们需要将爬过的url记录下来,我们将上图进行更改
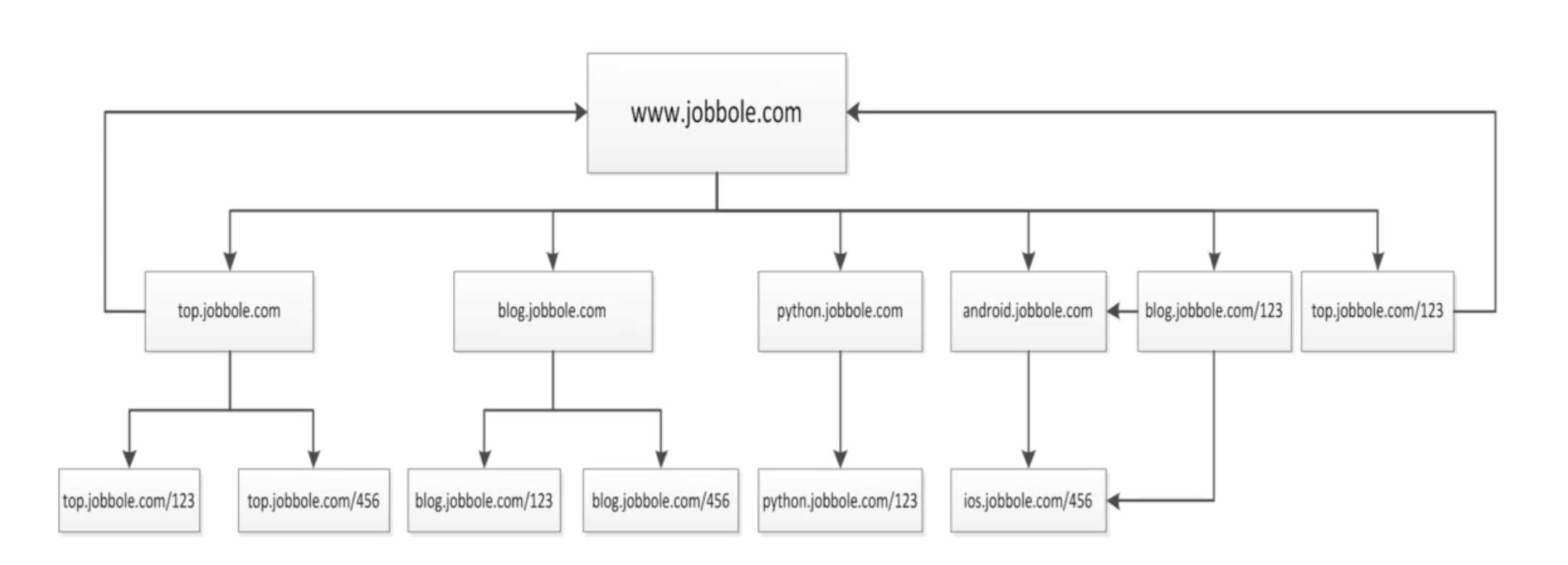
在爬虫系统中,待抓取URL队列是很重要的一部分,待抓取URL队列中的URL以什么样的顺序排队列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是常用的两种策略:深度优先、广度优先
深度优先
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接,通过下图进行理解:
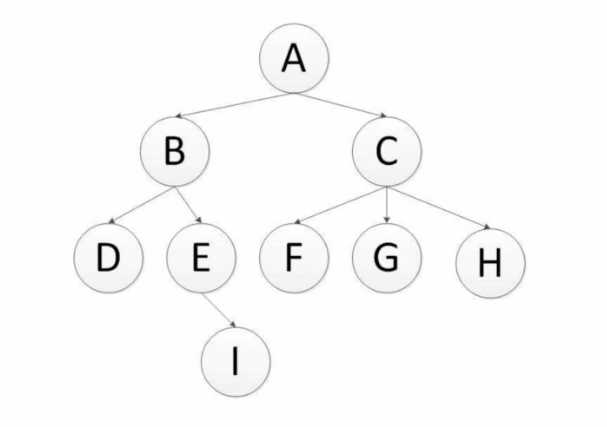
这里是深度优先,所以这里的爬取的顺序式:
A-B-D-E-I-C-F-G-H (递归实现)
深度优先算法的实现(伪代码):

广度优先
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页,通过下图进行理解:
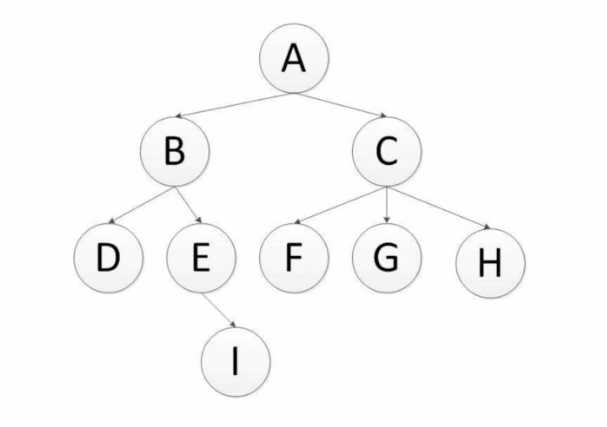
还是以这个图为例子,广度优先的爬取顺序为:
A-B-C-D-E-F-G-H-I (队列实现)
广度优先代码的实现(伪代码):

以上是关于Python爬虫从入门到放弃之 关于深度优先和广度优先的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫从入门到放弃之 Requests库的基本使用