python之路-Day3
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之路-Day3相关的知识,希望对你有一定的参考价值。
字典
dic{key:value}
元组
与列表相似,唯一就是不能修改
dic = {‘name‘:‘alex‘,‘age‘:18}
查询
print(dic[‘name‘]) #会报错
get方法查询,查询之后,如果不包含,不会报错,返回none
print(dic.get(‘name‘))
增加
dic[‘gender‘] = ‘lwq‘
print(dic)
字典中的元素是无序的,字典是通过key找值得。
改
dic[‘name‘] = ‘dt‘
字典不能改key,只能改value
删除
del dic[‘name‘]
key的定义规则:
1.必须是不可变的。如何判断数据类型是否可变:首先先定义,看id,然后再重新定义,看id,如果id变,表示可变,id不变(数字,字符串,元组),表示不可变(改变列表中的元素,字典),
name = ‘lwq‘ name = ‘hsc‘
2.只要是能hash,就能当key,hash有数就表明可以定义为key
3.字典中的key是唯一的。
value定义:都可以
字典定义:
dic3 = dict()
dic4 = dict({‘name‘:‘alex‘,‘age‘:18})
dic5 = dict(name=‘alex‘,age=18)
dic6 = dict(((‘name‘,‘ale‘),(‘age‘,18)))
dic1 = dic.copy()
dic2 = dict.fromkeys(‘hello‘,1) #快速生成字典,可以放列表,字符串。与申明的字典无关系。 当value是{}时
dic2 = dict.fromkeys(‘hell‘,{}) 如果再向其中增加时,{}就会被一个元素占用,
dic = dict.fromkeys(‘hello‘,1) print(dic) dic1 = dict.fromkeys(‘haha‘) print(dic1) dic2 = dict.fromkeys(‘name‘,{}) print(dic2) dic2[‘a‘] = ‘b ‘ print(dic2) dic2[‘e‘] = {‘c‘:1} print(dic2)
dic.get(‘name‘) # dic[‘name‘]
print(dic.items()) #项目,变成列表,列表中是元组
dic.keys() #取字典中所有的key
dic.pop(‘name‘) #删除,必须存在才能删除
dic.popitem() #随机删除,不需要些参数
dic.setdefault(‘gender‘,‘male‘) #增加
#或者 dic.setdefault(‘gender‘,[])
dic1 = {‘haah‘:‘111‘,‘name‘:‘lwq‘}
dic.update(dic1) # 也可以作为修改用,与新字典做更新
dic.values() #取字典的value
for i in dic
print(i) 打印的是字典所有的key
浅拷贝:
只拷贝第一层
深拷贝:
import 导入模块
import copy
dic3 = copy.deepcopy() 深拷贝
dic10 = {‘name‘:‘hsc‘,‘age‘:{‘lwq‘:19,‘wt‘:20}}
print(dic[‘age‘][‘lwq‘])
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
集合:解决关系运算和去重
定义:由不同的元素组成,如果有重复,就会去除掉,集合是无须得。
s1 = {‘a‘,1,2,3,4,5,4,4,4,}
print(s1)
集合的关系运算
python_set = {‘lwq‘,‘hsc‘,‘wt‘}
linux_set = {‘ls‘,‘lwq‘,‘hsc‘,‘lmz‘}
求两个集合交集
print(python_set&linux_set) -------print(python_set.intersection(linux_set))
并集,包含全部元素
print(python_set|linux_set) -------print(python_set.union(linux_set))
差集
print(python_set-linux_set) #去掉与linux_set相同的元素,打印python_set
print(python_set.difference(linux_set))
对称差集
print(python_set^linux_set) ------print(python_set.symmetric_difference(linux_set))
子集
print(python_set.issubset(linux_set))
父集
print(python_set.issuperset(linux_set))
#增加
s1.update(‘e‘)
s1.update(s5)
s1.update(‘hello‘) #把hello拆开加进去
s1.add(‘hello‘) #整体加进去
s1.pop() #随机删
s1.remove(‘w‘) #删除不存在的元素,报错
s1.discard(‘w‘) # 删除不存在的元素,不报错
s1.copy() #浅拷贝
s1.clear()
s1.difference_update(s5) #求差集并更新
s1.isdisjoint()
字符编码
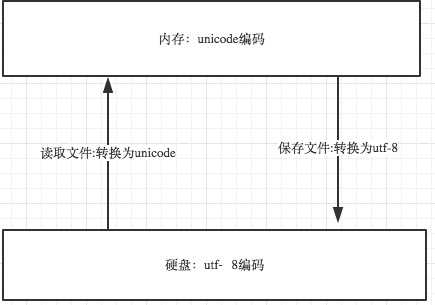
首先我们在终端定义一个内存变量:name=‘林海峰‘,那这个内存变量被存放到内存(必然是二进制),所以需要一个编码,就是unicode(内存中使用字符编码固定就是unicode)
但是如果我们写到文件中name=‘林海峰‘保存到硬盘(必然是二进制),也需要一个编码,这就跟各个国家有关了,假设我们用gbk,那么文件就被以gbk形式保存到硬盘上了。
程序要运行:硬盘二进制(gbk)---> 内存二进制(unicode)
就是说,所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
gbk->unicode需要decode(),unicode->gbk需要encode()就是这个意思
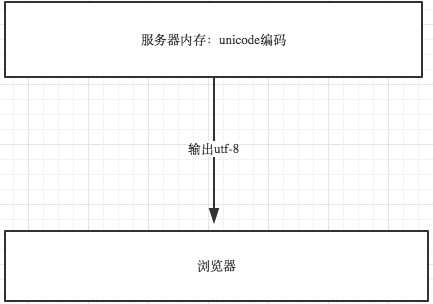
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
python程序比较特殊,要想运行需要python解释器去调用,也就相当于python解释器去读内存的程序的unicode代码
因而python解释器也有个解释器默认编码可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
注意了,这个编码,是python解释器这个软件的编码.
总结
其实无论是word也好pycharm也好,python解释器也好,我们都可当她们是处理文件的软件
注意:
- python2.7解释器默认编码为ascii
- python3.5解释器默认编码为utf-8
- 不管是python解释器也好还是其他与文本相关的软件也好,它们只能指定存取文件到硬盘的字符编码,而内存中固定使用uniccode
- test.py文件的头#-*-coding:utf-8-*-就是在修改python解释器的编码
流程:
- 从硬盘读区test.py的二进制bytes类型数据加载到内存,此刻python解释器就是一个类word软件啊,python解释器用自己的编码,将文件的二进制解码成unicode放到内存中
- python解释器从内存中读取unicode代码解释执行,执行时的代码中函数指定的编码与python解释器再无半点关系
高电压:1
低电压:0
字符 ------------------翻译的过程-------〉〉 数字
ascii --------8位2进制代表一个字符
gbk --------16位二进制代表一个汉字
unicode 万国码
utf-8 可变长 中文用三个字节,英文用一个字节
定义的变量到内存的时候,必须用nicode编码
硬盘 ---------〉〉 字符
字符 ---unicode-----〉〉内存 固定
encode 编码 decode 解码
1.内存固定使用unicode编码,硬盘的编码(可以修改的软件)
2.使用什么编码存入硬盘,就用什么编码去读。
3.程序运行分两个阶段:1.从硬盘读到内存 2.python解释器运行已经读到内存的程序
4.针对一个.py文件,python 与pycharm\\netepad++区别是多了第二个步骤
5.文件的头部标明解释器要以那种编码方式解释。
文件处理
f = open(‘my‘,‘w‘) #w创建写模式,如果存在,就覆盖 a追加写模式 r只读模式
f.write(‘我爱北京‘+‘\\n‘)
f.close() #保存
#del只能删除内存对象,不能删除硬盘上的东西
#混合模式
#读写:w+ 写读 清空内容,再去操作
# a+ 追加、读 追加到最后
# r+ 读写 将内容加到到第一行,并将第一行内容覆盖
f.close() #判断文件是否关闭
print(f.encoding) #打印文件编码
print(f.fileno()) #文件在操作系统中的索引值
f.flush() #强制刷新文件(保存)
f.isatty() #判断是否是一个终端
f.name #打印文件名
f.readable() #不可读的,做判断用
f.seek(10) #寻找 将光标移动到第十个字符,打印以后的内容
f.seekable() #是否可寻找
f.tell() #告诉当前光标的位置
f.truncate() #截断 从光标的位置将内容打断,后面的内容不显示(处理二进制文件),可指定大小,从头开始。
date = [‘alex\\n‘,‘lwq\\n‘]
f.writelines(date) #将列表按行插入文件
修改文件:
1.全部写入内存
2占用硬盘资源,修改好后删除原来的版本.
先判断,如果不是要修改的内容就直接写入到新文件
如果是要修改的内容,修改后写入新文件
需要同时打开两个文件,从一个文件读,然后再写入另一个文件
修改文件内容:
f = open(‘myname‘,‘r‘,encoding=‘utf-8‘) f_new = open(‘myname_new‘,‘w‘,encoding=‘utf-8‘) for line in f: if ‘常听收音机‘ in line: line = line.replace( ‘常听收音机‘, ‘常看电视剧‘) f_new.write(line) f.close() f_new.close()
处理大文件:可以读一行,删一行,这样内存就只保留一行。
for line in f:
print(line)
如果用这种方法写的话,下次再读取文件是,光标仍在第一行行首。
f.read(5) 表示只读五个
文件读取只能读一变,如果想读第二遍必须将光标移到上面。
打印进度条:基于flush
import sys,time
for i in range(20):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.1)
eval(date) #将字符串转换成字典
sys.argv
import sys
你include了iostream才能系统给你的std::cout;你import了sys,才能使用系统给你的sys.argv。
然后再说说argv这个变量。
「argv」是「argument variable」参数变量的简写形式,一般在命令行调用的时候由系统传递给程序。
这个变量其实是一个List列表,argv[0] 一般是被调用的脚本文件名或全路径,和操作系统有关,argv[1]和以后就是传入的数据了。
然后我们再看调用脚本的命令行:
python using_sys.py we are argumentspython就不用说了,「using_sys.py」脚本名,后面的用空格分割开的「we」「are」「argument」就是参数了。
PS.一般参数由空格分隔,如果参数内部有空格要使用英文双引号引起来比如这样:
python using_sys.py hi "I‘m 7sDream"
以上是关于python之路-Day3的主要内容,如果未能解决你的问题,请参考以下文章