python基础-------模块与包
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础-------模块与包相关的知识,希望对你有一定的参考价值。
re模块正则表达式
正则表达式常用符号:
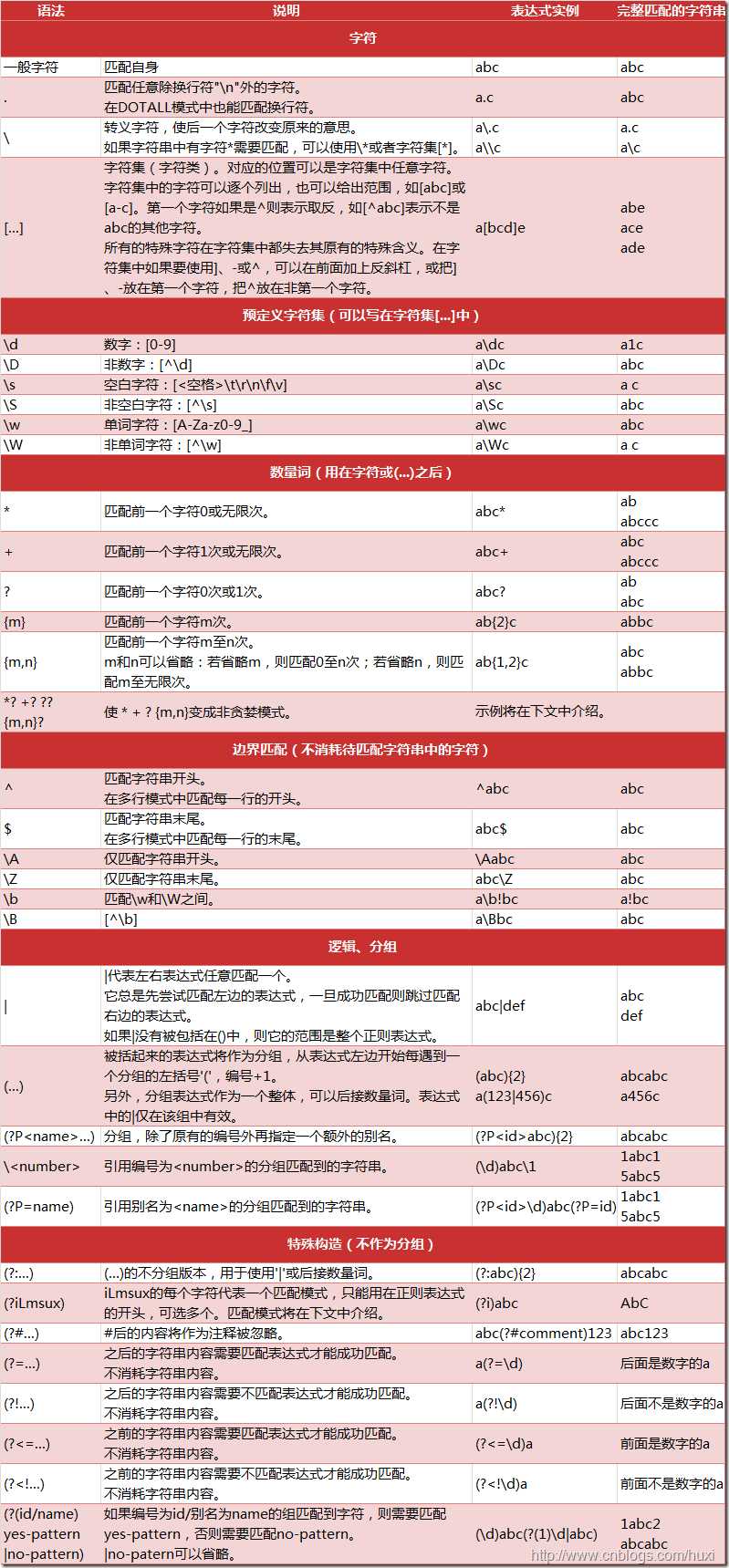
[ re模块使用方法]:
-
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符‘$‘。
示例参见2.1小节。
-
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
12345678910111213141516# encoding: UTF-8importre# 将正则表达式编译成Pattern对象pattern=re.compile(r‘world‘)# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match=pattern.search(‘hello world!‘)ifmatch:# 使用Match获得分组信息printmatch.group()### 输出 #### world -
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。1234567importrep=re.compile(r‘\\d+‘)printp.split(‘one1two2three3four4‘)### output #### [‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘] -
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。1234567importrep=re.compile(r‘\\d+‘)printp.findall(‘one1two2three3four4‘)### output #### [‘1‘, ‘2‘, ‘3‘, ‘4‘] -
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。12345678importrep=re.compile(r‘\\d+‘)forminp.finditer(‘one1two2three3four4‘):printm.group(),### output #### 1 2 3 4 -
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。当repl是一个字符串时,可以使用\\id或\\g<id>、\\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
123456789101112131415importrep=re.compile(r‘(\\w+) (\\w+)‘)s=‘i say, hello world!‘printp.sub(r‘\\2 \\1‘, s)deffunc(m):returnm.group(1).title()+‘ ‘+m.group(2).title()printp.sub(func, s)### output #### say i, world hello!# I Say, Hello World! -
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。123456789101112131415importrep=re.compile(r‘(\\w+) (\\w+)‘)s=‘i say, hello world!‘printp.subn(r‘\\2 \\1‘, s)deffunc(m):returnm.group(1).title()+‘ ‘+m.group(2).title()printp.subn(func, s)### output #### (‘say i, world hello!‘, 2)# (‘I Say, Hello World!‘, 2)
[ | re模块使用方法]:
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符‘$‘。
示例参见2.1小节。 - search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。12345678910111213141516# encoding: UTF-8importre# 将正则表达式编译成Pattern对象pattern=re.compile(r‘world‘)# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match=pattern.search(‘hello world!‘)ifmatch:# 使用Match获得分组信息printmatch.group()### 输出 #### world - split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。1234567importrep=re.compile(r‘\\d+‘)printp.split(‘one1two2three3four4‘)### output #### [‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘] - findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。1234567importrep=re.compile(r‘\\d+‘)printp.findall(‘one1two2three3four4‘)### output #### [‘1‘, ‘2‘, ‘3‘, ‘4‘] - finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。12345678importrep=re.compile(r‘\\d+‘)forminp.finditer(‘one1two2three3four4‘):printm.group(),### output #### 1 2 3 4 - sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\\id或\\g<id>、\\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。123456789101112131415importrep=re.compile(r‘(\\w+) (\\w+)‘)s=‘i say, hello world!‘printp.sub(r‘\\2 \\1‘, s)deffunc(m):returnm.group(1).title()+‘ ‘+m.group(2).title()printp.sub(func, s)### output #### say i, world hello!# I Say, Hello World! - subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。123456789101112131415importrep=re.compile(r‘(\\w+) (\\w+)‘)s=‘i say, hello world!‘printp.subn(r‘\\2 \\1‘, s)deffunc(m):returnm.group(1).title()+‘ ‘+m.group(2).title()printp.subn(func, s)### output #### (‘say i, world hello!‘, 2)# (‘I Say, Hello World!‘, 2)
以上是关于python基础-------模块与包的主要内容,如果未能解决你的问题,请参考以下文章