Python 程序如何高效地调试?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 程序如何高效地调试?相关的知识,希望对你有一定的参考价值。
作者:Rui L
链接:https://www.zhihu.com/question/21572891/answer/26046582
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/21572891/answer/26046582
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
这个要怒答一发。
应该用过 IPython 吧?想象一下,抛出异常时自动把你带到 IPython Shell 是不是很开心?而且和普通的IPython不同,这个时候可以调用 p (print), up(up stack), down(down stack) 之类的命令。还能创建临时变量,执行任意函数。
事实上这是可以实现的, 而且很简单,不过你要先安装 IPython。然后把以下代码保存为 `crash_on_ipy.py`
然后在你的项目代码某个地方 import crash_on_ipy 就可以了。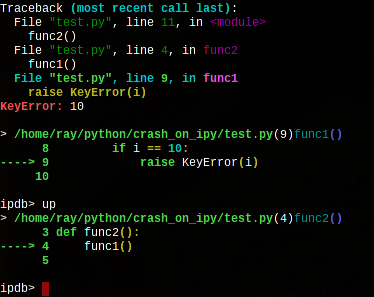
这个方法不需要 IDE.
应该用过 IPython 吧?想象一下,抛出异常时自动把你带到 IPython Shell 是不是很开心?而且和普通的IPython不同,这个时候可以调用 p (print), up(up stack), down(down stack) 之类的命令。还能创建临时变量,执行任意函数。
事实上这是可以实现的, 而且很简单,不过你要先安装 IPython。然后把以下代码保存为 `crash_on_ipy.py`
import sys
class ExceptionHook:
instance = None
def __call__(self, *args, **kwargs):
if self.instance is None:
from IPython.core import ultratb
self.instance = ultratb.FormattedTB(mode=‘Plain‘,
color_scheme=‘Linux‘, call_pdb=1)
return self.instance(*args, **kwargs)
sys.excepthook = ExceptionHook()
这个方法不需要 IDE.
想要类gdb的功能,可以使用pdb,例如:
import pdb
pdb.set_trace()
将上面2行加入到需要加断点的代码处,运行时,执行在此处即可中断,单步、继续、查看变量值等功能都有,不妨help下。
import pdb
pdb.set_trace()
将上面2行加入到需要加断点的代码处,运行时,执行在此处即可中断,单步、继续、查看变量值等功能都有,不妨help下。
作者:董伟明
链接:https://www.zhihu.com/question/21572891/answer/123220574
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/21572891/answer/123220574
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
看LZ的意思是想了解出现BUG怎么调试的问题。BUG有2种:
第一种,直接造成了错误,程序抛了个异常。楼上已经讲了IPython,是的。首先我先写一个有问题的例子:
执行肯定是报错的:
有点经验的人一眼看去就知道 是因为分母是0造成的。可是脚本执行结束了,要是调试还得不断的在对应位置加print。绝招就是:
程序运行在错误的地方,嘎.. 停住了,保存了错误上下文,进入pdb环境,直接调试去吧,不要太开心。
说到这里,ipdb(pdb)可以设置断点、单步调试、进入函数调试、查看当前代码、查看栈片段、动态改变变量的值等。它有很多快捷键:
其中up,down,n,j,l,where,s, args等我都非常常用,我非常建议你每个快捷键都了解一下。当然很懒的话,你们也有福利,看 Python 代码调试技巧 。
第二种:隐藏BUG,也就是并没有报错,但是输出不符合预期,这种的比较烦,因为如果你经验少写的时候又不咋专心的话,基本上就得挨个地方去确认,有人说,「import pdb pdb.set_trace() 」,嗯很标准的方案,但是我一般不用。原因是什么呢,比如调试Web应用,如果set_trace()的话,需要点多个next才能到你想调试的地方,手指头都点木了。。所以我一般使用如下三个方法:
1. 抛异常。直接让你想要调试的位置让它先跑个异常,比如Flask的DEBUG的模式下,werkzeug里面的DebuggedApplication就会把Web页面渲染成一个可调试和可执行的环境,直接到上面调试:
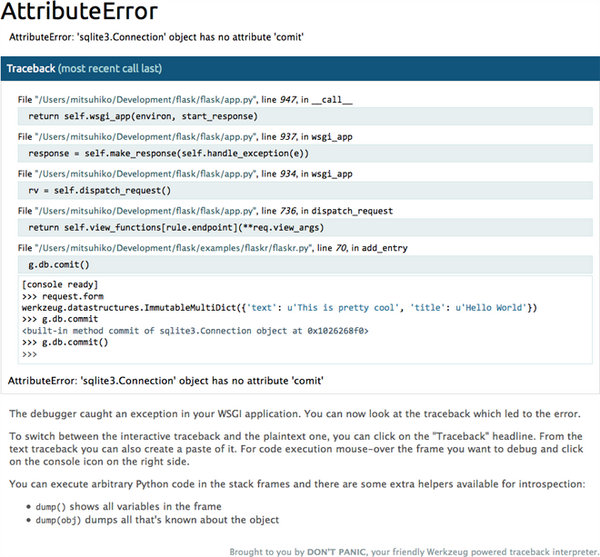 2. 在对应位置使用print和logging。这是最基础的玩法。我一般只会在已经心理有数,只是需要看看日志输出来确认的时候加临时的。平时的应用日志也会有常规的记录,并且会记录堆栈(当然,使用sentry之类的方式搜集日志是最好的),比如重要的上线过程中,出了问题但是开发环境又不好模拟出来的时候,「tail -f」日志文件们,这样出现问题一看就看到了。 说到这里再推荐一个很有意思的项目: GitHub - zestyping/q: Quick and dirty debugging output for tired programmers. ,它是在我看pycon2013演讲中发现的,有兴趣可以看看, PyVideo.org · Lightning Talks。我之前常用它。
2. 在对应位置使用print和logging。这是最基础的玩法。我一般只会在已经心理有数,只是需要看看日志输出来确认的时候加临时的。平时的应用日志也会有常规的记录,并且会记录堆栈(当然,使用sentry之类的方式搜集日志是最好的),比如重要的上线过程中,出了问题但是开发环境又不好模拟出来的时候,「tail -f」日志文件们,这样出现问题一看就看到了。 说到这里再推荐一个很有意思的项目: GitHub - zestyping/q: Quick and dirty debugging output for tired programmers. ,它是在我看pycon2013演讲中发现的,有兴趣可以看看, PyVideo.org · Lightning Talks。我之前常用它。
3. 自己维护一些用于调试的库。我会把工作中常用到的、有用的一些函数、方法搜集起来,放在一个库里。其中有个获取调用栈的函数类似这样:
可以通过看当前上下文的调用栈的输出来帮助你揪出那个隐藏的「虫」
第一种,直接造成了错误,程序抛了个异常。楼上已经讲了IPython,是的。首先我先写一个有问题的例子:
a = 1
b = 0
a / b
执行肯定是报错的:
? python test.py
Traceback (most recent call last):
File "test.py", line 4, in <module>
a / b
ZeroDivisionError: integer division or modulo by zero
有点经验的人一眼看去就知道 是因为分母是0造成的。可是脚本执行结束了,要是调试还得不断的在对应位置加print。绝招就是:
? ipython test.py --pdb
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
/Users/dongweiming/test/test.py in <module>()
2 b = 0
3
----> 4 a / b
ZeroDivisionError: integer division or modulo by zero
*** NameError: name ‘pdb‘ is not defined
> /Users/dongweiming/test/test.py(4)<module>()
1 a = 1
2 b = 0
3
----> 4 a / b
ipdb> p b # p是print的别名
0
ipdb> p a
1
ipdb>
程序运行在错误的地方,嘎.. 停住了,保存了错误上下文,进入pdb环境,直接调试去吧,不要太开心。
说到这里,ipdb(pdb)可以设置断点、单步调试、进入函数调试、查看当前代码、查看栈片段、动态改变变量的值等。它有很多快捷键:
ipdb> help
Documented commands (type help <topic>):
========================================
EOF bt cont enable jump pdef psource run unt
a c continue exit l pdoc q s until
alias cl d h list pfile quit step up
args clear debug help n pinfo r tbreak w
b commands disable ignore next pinfo2 restart u whatis
break condition down j p pp return unalias where
其中up,down,n,j,l,where,s, args等我都非常常用,我非常建议你每个快捷键都了解一下。当然很懒的话,你们也有福利,看 Python 代码调试技巧 。
第二种:隐藏BUG,也就是并没有报错,但是输出不符合预期,这种的比较烦,因为如果你经验少写的时候又不咋专心的话,基本上就得挨个地方去确认,有人说,「import pdb pdb.set_trace() 」,嗯很标准的方案,但是我一般不用。原因是什么呢,比如调试Web应用,如果set_trace()的话,需要点多个next才能到你想调试的地方,手指头都点木了。。所以我一般使用如下三个方法:
1. 抛异常。直接让你想要调试的位置让它先跑个异常,比如Flask的DEBUG的模式下,werkzeug里面的DebuggedApplication就会把Web页面渲染成一个可调试和可执行的环境,直接到上面调试:
2. 在对应位置使用print和logging。这是最基础的玩法。我一般只会在已经心理有数,只是需要看看日志输出来确认的时候加临时的。平时的应用日志也会有常规的记录,并且会记录堆栈(当然,使用sentry之类的方式搜集日志是最好的),比如重要的上线过程中,出了问题但是开发环境又不好模拟出来的时候,「tail -f」日志文件们,这样出现问题一看就看到了。 说到这里再推荐一个很有意思的项目: GitHub - zestyping/q: Quick and dirty debugging output for tired programmers. ,它是在我看pycon2013演讲中发现的,有兴趣可以看看, PyVideo.org · Lightning Talks。我之前常用它。3. 自己维护一些用于调试的库。我会把工作中常用到的、有用的一些函数、方法搜集起来,放在一个库里。其中有个获取调用栈的函数类似这样:
import sys
def get_cur_info():
print sys._getframe().f_code.co_filename # 当前文件名
print sys._getframe(0).f_code.co_name # 当前函数名
print sys._getframe(1).f_code.co_name # 调用该函数的函数的名字,如果没有被调用,则返回module
print sys._getframe().f_lineno # 当前行号
可以通过看当前上下文的调用栈的输出来帮助你揪出那个隐藏的「虫」
以上是关于Python 程序如何高效地调试?的主要内容,如果未能解决你的问题,请参考以下文章