Python3爬取电影信息:调用API
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3爬取电影信息:调用API相关的知识,希望对你有一定的参考价值。
实验室这段时间要采集电影的信息,给出了一个很大的数据集,数据集包含了4000多个电影名,需要我写一个爬虫来爬取电影名对应的电影信息。
其实在实际运作中,根本就不需要爬虫,只需要一点简单的Python基础就可以了。
前置需求:
Python3语法基础
HTTP网络基础
===================================
第一步,确定API的提供方。IMDb是最大的电影数据库,与其相对的,有一个OMDb的网站提供了API供使用。这家网站的API非常友好,易于使用。
http://www.omdbapi.com/
第二步,确定网址的格式。
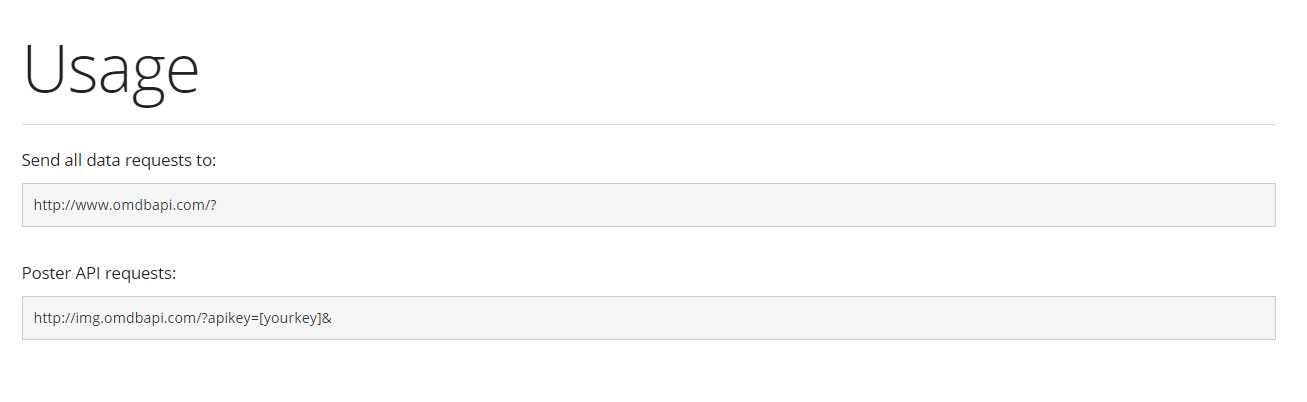
第三步,了解基本的Requests库的使用方法。
http://cn.python-requests.org/zh_CN/latest/
为什么我要使用Requests,不使用urllib.request呢?
因为Python的这个库容易出各种各样的奇葩问题,我已经受够了……
第四步,编写Python代码。
我想做的是,逐行读取文件,然后用该行的电影名去获取电影信息。因为源文件较大,readlines()不能完全读取所有电影名,所以我们逐行读取。
1 import requests 2 3 for line in open("movies.txt"): 4 s=line.split(‘%20\\n‘) 5 urll=‘http://www.omdbapi.com/?t=‘+s[0] 7 result=requests.get(urll) 8 if result: 9 json=result.text 10 print(json) 11 p=open(‘result0.json‘,‘a‘) 12 p.write(json) 13 p.write(‘\\n‘) 14 p.close()
我预先把电影名文件全部格式化了一遍,将所有的空格替换成了"%20",便于使用API(否则会报错)。这个功能可以用Visual Studio Code完成。
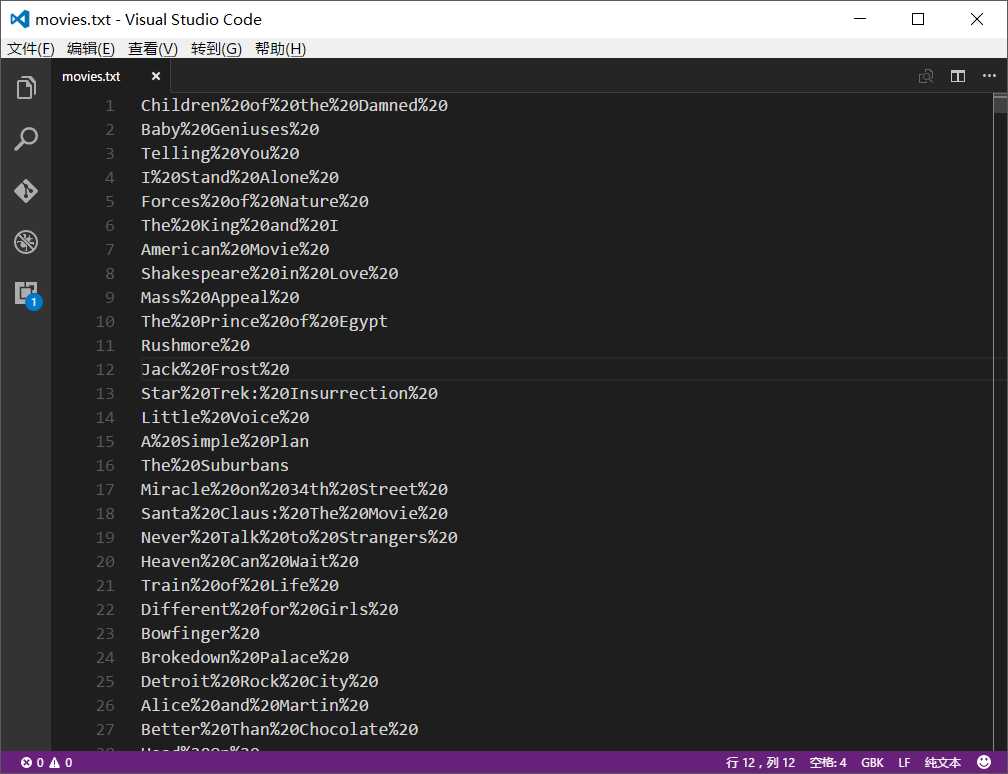
注意,编码的时候选择GBK编码,不然会出现下面错误:
1 UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xff in position 0: illegal multibyte sequence
第五步,做优化和异常处理。
主要做三件事,第一件事,控制API速度,防止被服务器屏蔽;
第二件事,获取API key(甚至使用多个key)
第三件事:异常处理。
1 import requests 3 4 key=[‘’] 5 6 for line in open("movies.txt"): 7 try: 8 #…… 9 except TimeoutError: 10 continue 11 except UnicodeEncodeError: 12 continue 13 except ConnectionError: 14 continue
下面贴出完整代码:
1 # -*- coding: utf-8 -*- 2 3 import requests 4 import time 5 6 key=[‘xxxxx‘,‘yyyyy‘,zzzzz‘,‘aaaaa‘,‘bbbbb‘] 7 i=0 8 9 for line in open("movies.txt"): 10 try: 11 i=(i+1)%5 12 s=line.split(‘%20\\n‘) 13 urll=‘http://www.omdbapi.com/?t=‘+s[0]+‘&apikey=‘+key[i] 14 result=requests.get(urll) 15 if result: 16 json=result.text 17 print(json) 18 p=open(‘result0.json‘,‘a‘) 19 p.write(json) 20 p.write(‘\\n‘) 21 p.close() 22 time.sleep(1) 23 except TimeoutError: 24 continue 25 except UnicodeEncodeError: 26 continue 27 except ConnectionError: 28 continue
接下来喝杯茶,看看自己的程序跑得怎么样吧!
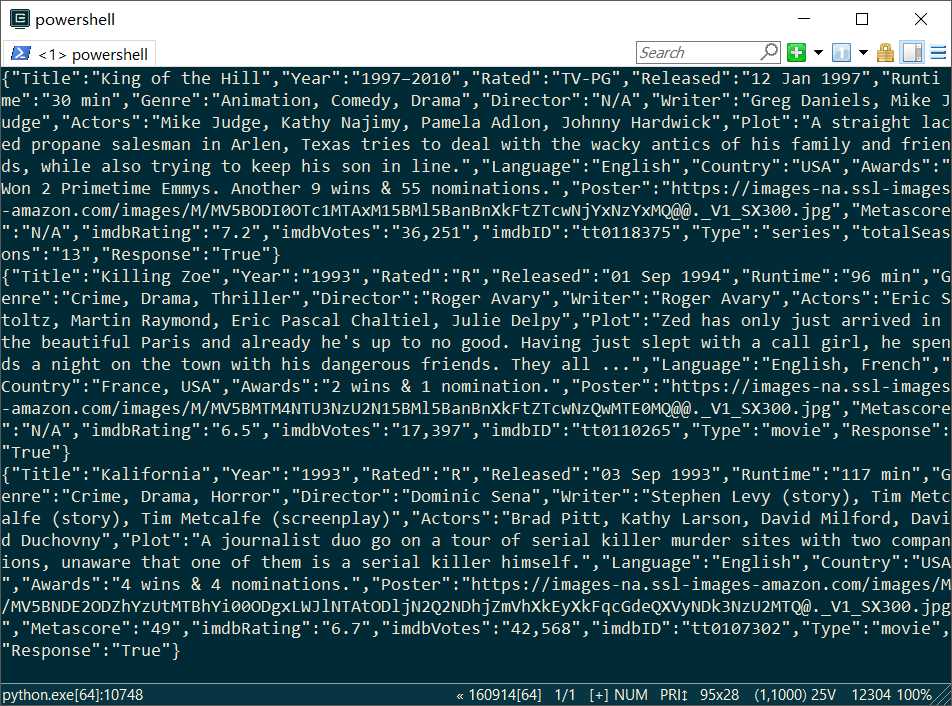
以上是关于Python3爬取电影信息:调用API的主要内容,如果未能解决你的问题,请参考以下文章