Python基础(12)_python模块之sys模块logging模块序列化json模块pickle模块shelve模块
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础(12)_python模块之sys模块logging模块序列化json模块pickle模块shelve模块相关的知识,希望对你有一定的参考价值。
5、sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
5.1 使用sys.argv进行登录判断,跳过 i/o阻塞
#使用sys.argv进行登录判断,跳过 i/o阻塞
import sys
ret=sys.argv
name=ret[ret.index(‘-u‘)+1]
passwd=ret[ret.index(‘-p‘)+1]
if name==‘egon‘ and passwd==‘666‘:
print(‘login successful‘)
>>:
D:\\Pycharm Workspace\\Day13>python 课上练习1.py -p 666 -u egon
login successful
5.2 sys.path 介绍与使用
基本概念:
sys.path指定用于模块搜索路径的字符串列表。默认情况下python导入文件或者模块的话,他会先在sys.path里找模块的路径。如果没有的话,程序就会报错。
它根据环境变量PYTHONPATH进行初始化,再加上安装时的默认值。
>>> import sys >>> sys.path [‘‘, ‘D:\\\\Develop\\\\python\\\\Python36\\\\python36.zip‘, ‘D:\\\\Develop\\\\python\\\\Python36\\\\DLLs‘, ‘D:\\\\Develop\\\\python\\\\Python36\\\\lib‘, ‘D:\\\\Develop\\\\python\\\\Python36‘, ‘D:\\\\Develop\\\\python\\\\Python36\\\\lib\\\\site-packages‘]
1、此列表的第一项path[0],在程序启动时初始化,是包含调用Python解释器的脚本的目录,后面为python环境所在目录
2、ath[0]是空字符串,表示Python首先搜索当前目录中的模块,即优先寻找脚本同一级目录下模块。若同一级目录下有同名的第三方模块空模块,则在调用模块是会出错。
3、自己写程序的话。最好把自己的模块路径给加到当前模块扫描的路径里,eg: sys.path.append(‘你的模块的名称‘),或者sys.path.insert(0,‘模块的名称‘),这样程序就不会因为找不到模块而报错,此添加但在退出python环境后自己添加的路径就会自动消失!
永久添加路径到sys.path中,方式有三,如下:
1)将写好的py文件放到 /usr/lib/python3.6/site-packages 目录下
2) 在 /usr/lib/python3.6/site-packages 下面新建一个.pth 文件(以pth作为后缀名)
将模块的路径写进去,一行一个路径,如: vim pythonmodule.pth
/home/liu/shell/config
/home/liu/shell/base
3) 使用PYTHONPATH环境变量
export PYTHONPATH=$PYTHONPATH:/home/liu/shell/config
6、logging模块
6.1 函数式简单配置
logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging
‘‘‘
一:如果不指定filename,则默认打印到终端
二:指定日志级别:
指定方式:
1:level=10
2:level=logging.ERROR
日志级别种类:
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
三:指定日志级别为ERROR,则只有ERROR及其以上级别的日志会被打印
‘‘‘
logging.basicConfig(filename=‘access.log‘,
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
level=10)
logging.debug(‘debug‘)
logging.info(‘info‘)
logging.warning(‘warning‘)
logging.error(‘error‘)
logging.critical(‘critical‘)
logging.log(10,‘log‘) #如果level=40,则只有logging.critical和loggin.error的日志会被打印
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
6.2 logger对象配置
import logging logger = logging.getLogger() # 创建一个handler,用于写入日志文件 fh = logging.FileHandler(‘test.log‘) # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug(‘logger debug message‘) logger.info(‘logger info message‘) logger.warning(‘logger warning message‘) logger.error(‘logger error message‘) logger.critical(‘logger critical message‘)
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别。
7、序列化模块
什么是序列化
把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
为什么要序列化:
1:持久保存状态
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
7.1 json模块
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象一个子集,JSON和Python内置的数据类型对应如下:
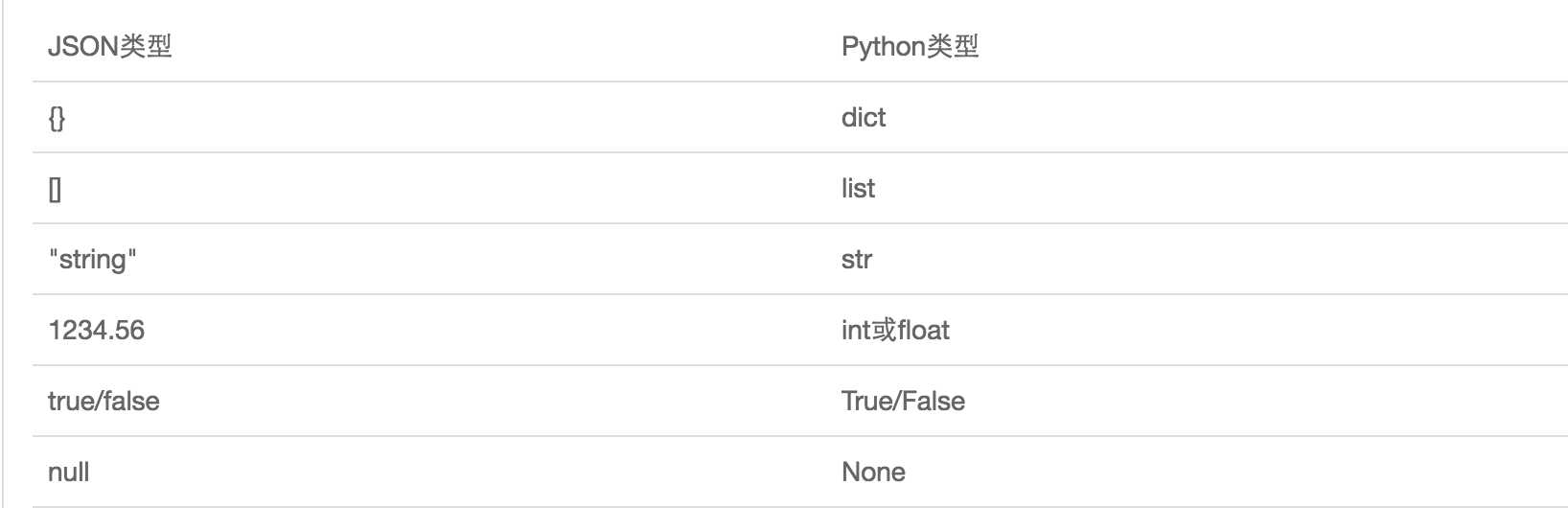

python在文本中的使用:
#----------------------------序列化
import json
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
print(type(dic))#<class ‘dict‘>
data=json.dumps(dic)
print("type",type(data))#<class ‘str‘>
print("data",data)
f=open(‘序列化对象‘,‘w‘)
f.write(data) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open(‘序列化对象‘)
new_data=json.loads(f.read())# 等价于data=json.load(f)
print(type(new_data))
json模块主要要点:json只认“”双引号
import json
#dct="{‘1‘:111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{‘one‘: 1}
dct=‘{"1":"111"}‘
print(json.loads(dct))
#conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
7.2 pickle模块
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。

import pickle
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
print(type(dic))#<class ‘dict‘>
j=pickle.dumps(dic)
print(type(j))#<class ‘bytes‘>
f=open(‘序列化对象_pickle‘,‘wb‘)#注意是w是写入str,wb是写入bytes,j是‘bytes‘
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open(‘序列化对象_pickle‘,‘rb‘)
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data[‘age‘])
7.3 shelve模块
shelve模块与pickle模块一样,只适用于python,但比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r‘sheve.txt‘)
# f[‘stu1_info‘]={‘name‘:‘egon‘,‘age‘:18,‘hobby‘:[‘piao‘,‘smoking‘,‘drinking‘]}
# f[‘stu2_info‘]={‘name‘:‘gangdan‘,‘age‘:53}
# f[‘school_info‘]={‘website‘:‘http://www.pypy.org‘,‘city‘:‘beijing‘}
print(f[‘stu1_info‘][‘hobby‘])
f.close()
以上是关于Python基础(12)_python模块之sys模块logging模块序列化json模块pickle模块shelve模块的主要内容,如果未能解决你的问题,请参考以下文章