Python爬虫利器:BeautifulSoup库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫利器:BeautifulSoup库相关的知识,希望对你有一定的参考价值。
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you.
BeautifulSoup库是解析、遍历、维护 “标签树” 的功能库(遍历,是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问)。https://www.crummy.com/software/BeautifulSoup
BeautifulSoup库我们常称之为bs4,导入该库为:from bs4 import BeautifulSoup。其中,import BeautifulSoup即主要用bs4中的BeautifulSoup类。
bs4库解析器
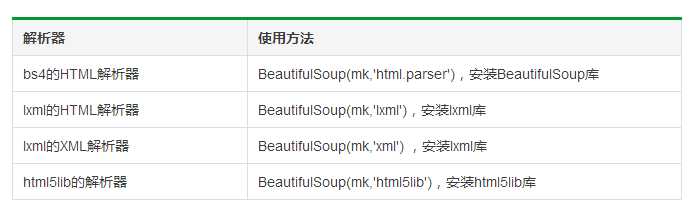
BeautifulSoup类的基本元素
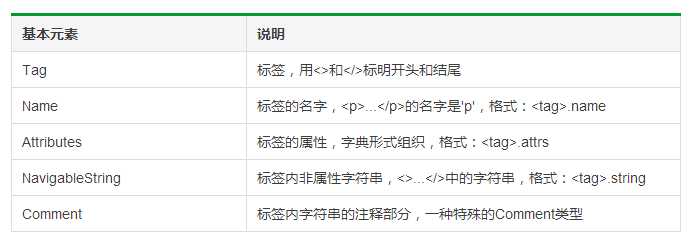
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get(‘http://www.pmcaff.com/site/selection‘) 5 soup = BeautifulSoup(res.text,‘lxml‘) 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name) 10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型 11 12 print(soup.a.attrs) 13 print(soup.a.attrs[‘class‘]) 14 # 一个<tag>可能有一个或多个属性,是字典类型 15 16 print(soup.a.string) 17 # <tag>.string可以取到标签内非属性字符串 18 19 soup1 = BeautifulSoup(‘<p><!--这里是注释--></p>‘,‘lxml‘) 20 print(soup1.p.string) 21 print(type(soup1.p.string)) 22 # comment是一种特殊类型,也可以通过<tag>.string取到
运行结果:
<a class="no-login" href="">登录</a>
a
{‘href‘: ‘‘, ‘class‘: [‘no-login‘]} [‘no-login‘]
登录
这里是注释
<class ‘bs4.element.Comment‘>
bs4库的HTML内容遍历
HTML的基本结构
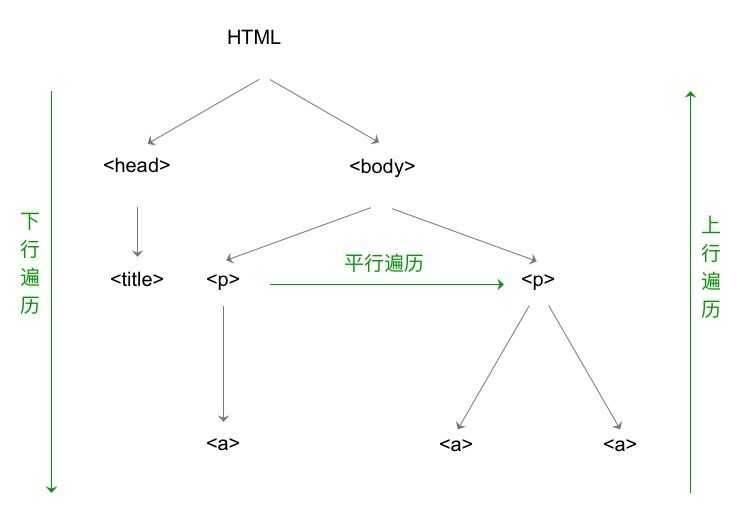
标签树的下行遍历
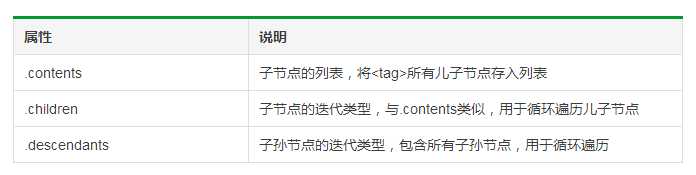
其中,BeautifulSoup类型是标签树的根节点。
1 # 遍历儿子节点 2 for child in soup.body.children: 3 print(child.name) 4 5 # 遍历子孙节点 6 for child in soup.body.descendants: 7 print(child.name)
标签树的上行遍历

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断 2 for parent in soup.a.parents: 3 if parent is None: 4 print(parent) 5 else: 6 print(parent.name)
运行结果:
div
div
body
html
[document]
标签树的平行遍历
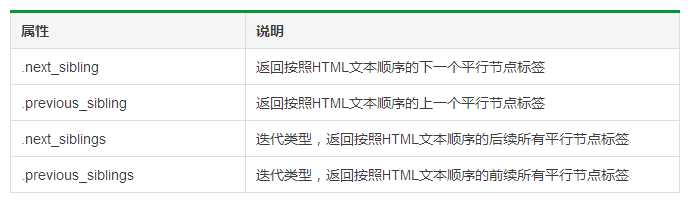
1 # 遍历后续节点 2 for sibling in soup.a.next_sibling: 3 print(sibling) 4 5 # 遍历前续节点 6 for sibling in soup.a.previous_sibling: 7 print(sibling)
bs4库的prettify()方法
prettify()方法可以将代码格式搞的标准一些,用soup.prettify()表示。在PyCharm中,用print(soup.prettify())来输出。
操作环境:Mac,Python 3.6,PyCharm 2016.2
参考资料:中国大学MOOC课程《Python网络爬虫与信息提取》
----- End -----
更多精彩内容关注我公众号:杜王丹
作者:杜王丹,互联网产品经理

以上是关于Python爬虫利器:BeautifulSoup库的主要内容,如果未能解决你的问题,请参考以下文章
第65天:爬虫利器 Beautiful Soup 之遍历文档