李沐多模态串讲视频总结 ALBEF VLMo BLIP CoCa BEITv3 模型简要介绍
Posted bringlu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李沐多模态串讲视频总结 ALBEF VLMo BLIP CoCa BEITv3 模型简要介绍相关的知识,希望对你有一定的参考价值。
开场
-
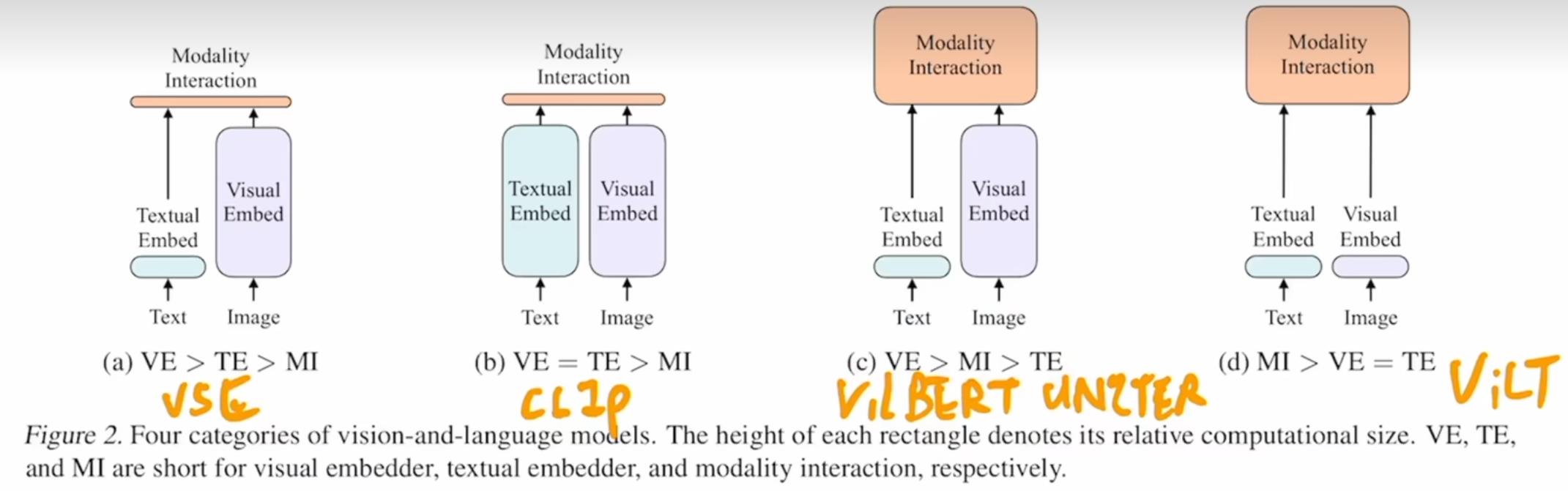
多模态串讲的上篇是比较传统的多模态任务
-
多模态最后的模态交互很重要
-
传统的缺点是都用了预训练的目标检测器,训练和部署都很困难。
-
ViLT 把预训练的目标检测器换成了一层的 Patch Embedding。
- 因此容易比不过 c 类的方法
-
ViLT 训练很慢
-
认为未来是 c 类的模型结构
-
Loss:
- b 类(CLIP)仅用对比学习的 loss(Image Text Contrastive),比较简单。
- c 类由于有目标检测,因此提了 Word Patch Alignment
- ViLT 中发现 WPA Loss 非常慢
- MLM 的 Loss
- Image Text Matching 效果也很好
- 认为目标函数应该是 ITC + ITM + MLM 的合体
回顾 CLIP
- 双塔模型
- 让已有的(图像,文本)对在空间上更近,不是一个对的空间上更远。
- 最后仅做了点乘。
- 缺陷:
- VQA 等任务不太好
ALBEF
论文:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
亮点:
- 图像部分 12 层 transformer encoder
- 文本部分前 6 层文本编码器,后 6 层做多模态融合的编码器。
- 没有目标检测模型
- 使用了 Image Text Contrastive loss
- 自训练,用伪标签标上网上爬下来的有噪数据。 伪标签(pseudo-target)由一个 momentum model 提供。
- 原因在于搜索引擎爬下来的(图像,文本)对,非常高噪。文本被称作 Alt text,并没有很好地描述图像,而是提供了搜索引擎需要便于检索的关键词。
- 互信息最大化的方式:文章里所提到的目标函数是为了同一个图像文本对提供不同的视角。变相的数据增强。
- 速度很快:4e6 的数据 8 卡机训练 3、4 天可以跑出来(这也很久了)
作者来自 SalesForce,有一系列多模态工作,很厉害。
文章提到:由于大多数方法使用 transformer 的多模态编码器来同时编码视觉和文本特征,由于目标检测器是提前训练好的,因此视觉和文本特征并不是对齐的。由于没经过端到端的训练,因此可能这两个特征有很远的距离。
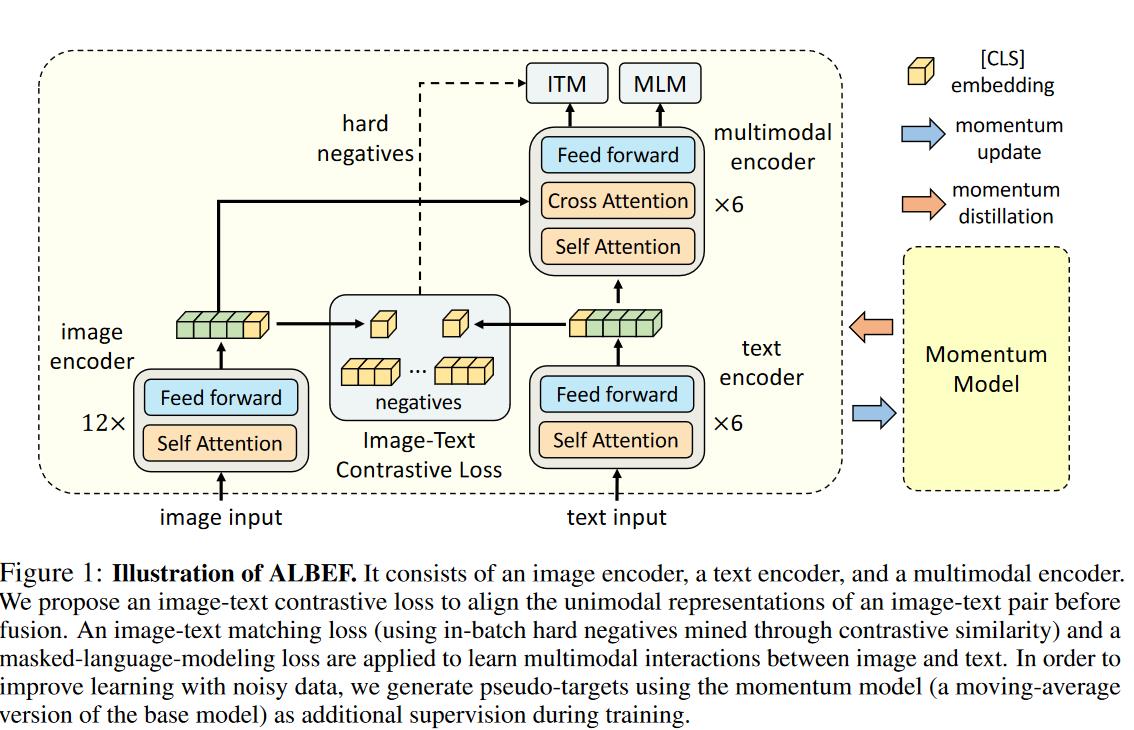
模型
image Embedding 部分
- 使用了标准的 ViT 模型
- 预训练参数用了 DEiT。
文本部分
- 只用前 6 层做文本编码
Loss 函数
- ITC loss

- 文本和图片的 [CLS] token 经过 encoder 后,被当作文本的全局特征,然后丢尽 ITC loss 里作比较。
- 所以这里有个问题:图片是怎么加上 [CLS] token 的?
- ViT 中将图片分成若干个 patch,然后把 patch 作为 token,然后直接加上 [CLS] token 后,再进行 embedding 等操作。
- 所以这里有个问题:图片是怎么加上 [CLS] token 的?
- 这里是将文本转化成的图片与 ground-truth 做交叉熵,反之亦然。
- 但是这样就没办法得到中间状态了?
- ITM Loss
- 给定图片和文本,然后经过 ALBEF 的模型后,得到特征,再过一个FC层,以此做二分类,判断是否为一对。
- 但是判断正样本有点难,但是判断负样本很容易,因此准确度会上升得很快。
- 为解决上面的问题,这里通过某种方式选择最接近正样本的负样本。
- hard negatives :ITM 利用 ITC 把同一 batch 中图片和所有文本都算一遍余弦相似度。 利用最相似的做负样本。
- Masked Language Modeling
- mask 掉一些文本,然后将 mask 过后的句子和图片一起通过 ALBEF 模型,最后把之前完整的句子预测出来。
- 输入与前两个 Loss 不同是 \\((I, T_mask)\\),说明模型用了两次
forward()函数。
然后三者简单加和即可。
Momentum Distillation(动量蒸馏)
- 原因
- noisy web data
- ITC:可能文本已经描述得很好了,但是由于 data noisy,导致了其为负样本。
- MLM:有时候可能比填 ground-truth 更好的文本。
- noisy web data
- self-training
- 具体模型构建:在已有模型之上做 exponential-moving-average
- 目的:跟 one-hot 尽可能接近之外,让它跟动量模型出来的 pseudo-targets 尽可能 match。
- 对原 Loss 的改进,都对两者加入了动量蒸馏后的向量:
- ITC:见式 6.
- MLM:式 7.
实验
预训练
四个数据集:
- Conceptual Captions
- SBU Captions
- COCO:图片对多文本
- Visual Genome:图片对多文本
第五个数据集更 noisy,但是数量也更大, 对性能也有提升。
下游任务
- Image-Text Retrieval
- Visual Entailment
- VQA
- Visual Reasoning
- Visual Grounding
消融实验
- 去掉 ITC 掉的多 。
- hard negative 其二。
- Momentum Distillation 提升反而没有那么大,但是是很有趣的研究方向。
VLMo
题目:VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
微软的组发的
亮点:
- 模型结构上的改进 Mixture-of-Modality-Experts
- 训练方式改进:分阶段模型预训练
作者认为前人缺点
- CLIP、ALIGN:
- 双塔结构(比较大的文本模型和图片模型),最后只做了一个余弦相似度,余弦过于简单。
- 单塔结构(即有一个比较大的模态融合模型)
- 分类任务上 superior performance
- 检索任务数据集大的时候,推理时间会非常慢
因此作者融合前两者。简单地说,自注意力中所有的模态都是共享的,但是在 FC 层中,每个模态会对应自己不同的 Expert。训练时,哪个模态的数据来了就训练对应模态的 Expert。
训练 Loss 函数同样是 ITC、ITM、MLM。
多模态数据集可能不够,因此采用了单模态的其他数据,分阶段训练。
- 把 vision expert 在 vision 数据集上训练
- 把 language expert 在语言数据集上训练
- 再在多模态数据集上训练
模型
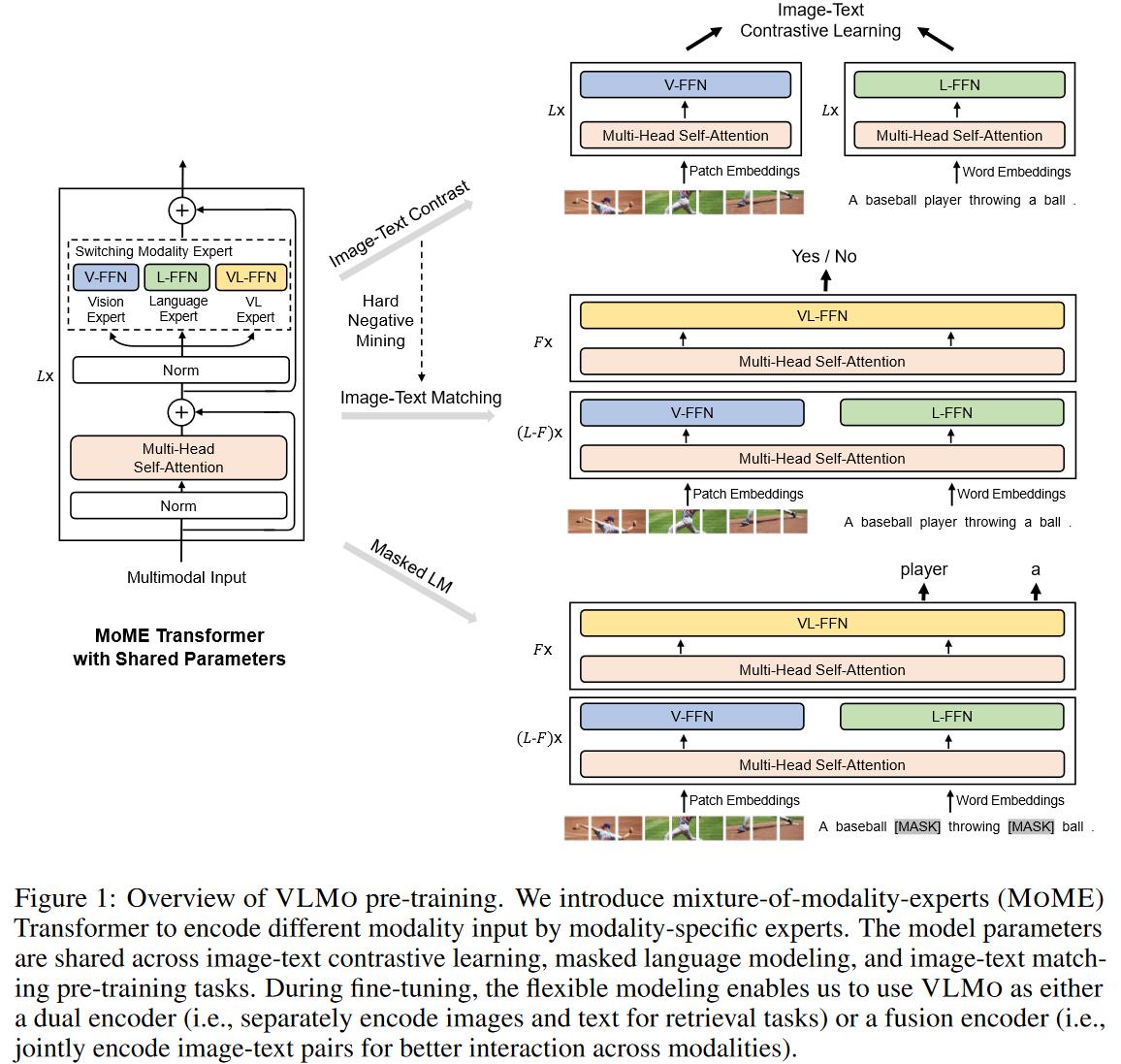
模型亮点
- MoME Transformer
- 前面的多头注意力层共享参数
- Switching Modality Expert:每个模态一个 FFN 层,不共享参数
- 灵活
- 在不同的下游任务上可以采用不同的结构以及相同的参数
Loss
- ITC
- ITM
- MLM
实验
训练过程
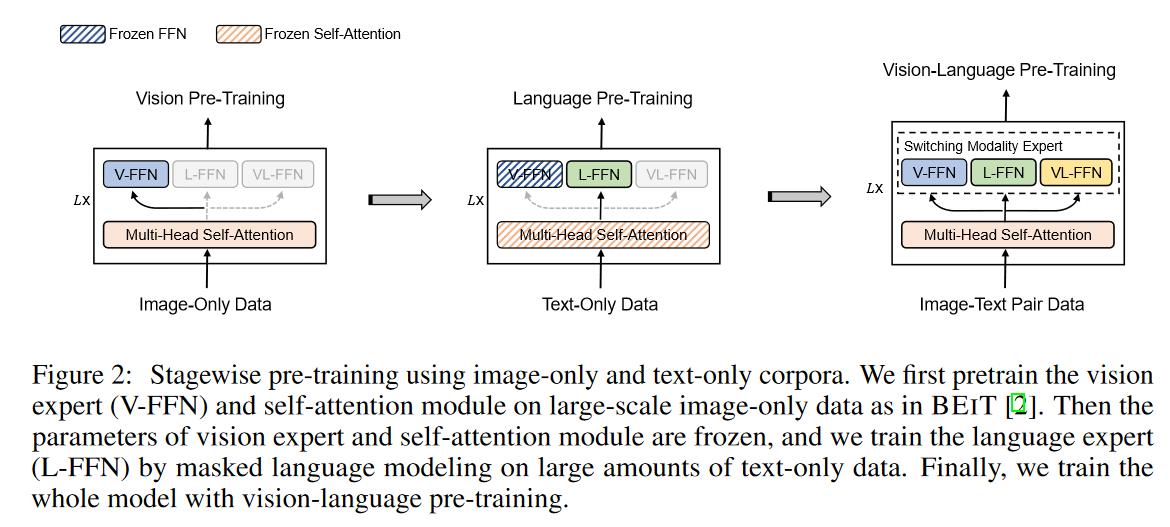
- 自注意力在视觉上训练了,然后会在文本部分冻住。
- 反过来反而没那么有效。
- 最后一步全部解冻
结果
数据集:
VQA、NLVR2
简要结果
比 ALBEF 全线更强
一些未来的工作已被验证
- 更大模型 —— BeiTv3
- vision-language generation ——VL-BeiT
- 单模态可以帮助多模态,多模态也可以帮助单模态——BeiTv3
- 更多模态,如视频等——MetaLM
BLIP
论文:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding Generation
基于 Transformer Encoder Decoder 的工作
作者来自 Salesforce
亮点:
- Bootstrap:从数据集角度出发的
- 先用嘈杂数据训练模型,再用比较干净的数据训练模型
- Unified:
- 统一了图像-语言的理解与生成任务
引言
- 模型:以前的模型一般是 encoder 或者 encoder-decoder
- 但是 only-encoder 模型没法应用到生成任务中
- encoder-docoder 模型,由于没有统一框架,也不能做 VL retrieval 的任务
- 数据:
- 以前的模型都是在大规模的 noisy 数据训练
- 因此本文要更好地 clean 数据
- Captioner:利用 Captioner 生成图片相应文本
- Filter:利用 Filter 筛掉不匹配的 VL 对
- 因此结合了 ALBEF 和 VLMo,做出BLIP
方法
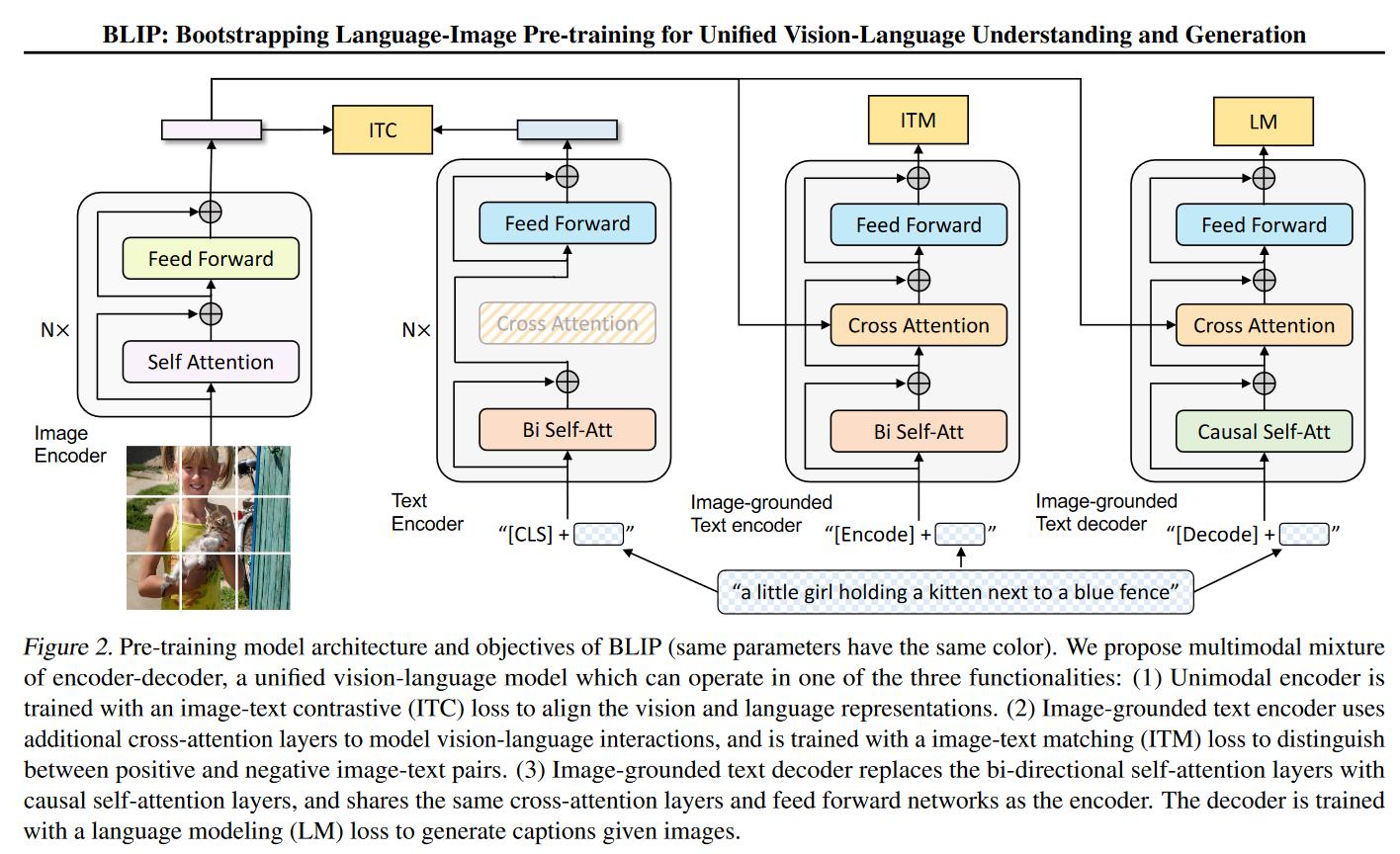
模型
- 图片部分
- 标准 ViT
- 剩下部分有三个模型,分别算三个不同的目标函数
- 第一个模型:Text Encoder 做分类任务
- 得到文本特征与图片特征做 ITC
- 第二个模型:Image-grounded Text encoder
- 多模态编码器
- 借助图像信息
- ITM Loss
- 第三个模型 Image-grounded Text decoder
- 用于做生成任务
- 不能看到完整的句子
- 类似GPT,从前面推测后面的句子
- 第一层是 Causal Self-att,因果关系的自注意力
- LM Loss
- 第一个模型:Text Encoder 做分类任务
- 共享参数
- 同样颜色代表同样的参数
- 训练很费时间,原因要做四个
forward()
Captioner 和 Filter
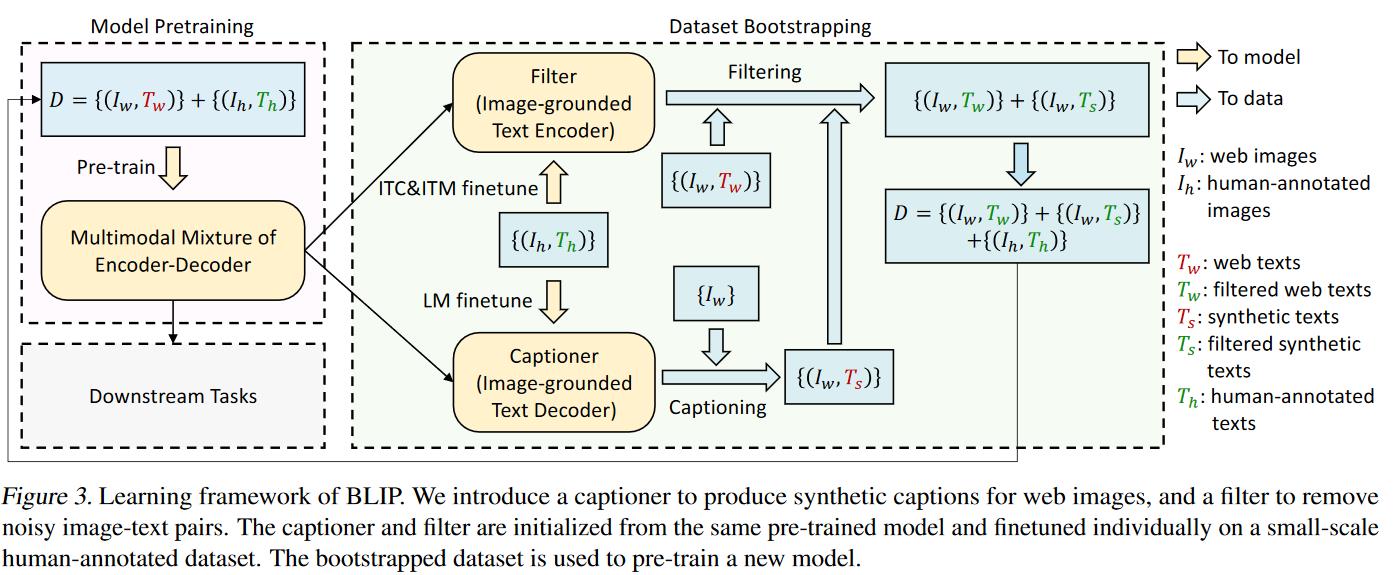
可以认为爬下来的数据有很大概率不匹配(如 CC12M),但是手工标注的数据很可能匹配(如COCO)
- Filter
- 利用 ITC&ITM 的模型在 COCO 上 finetune。然后利用该模型筛选
- Captioner
- BLIP 性能很强,于是生成的文本有时候比原始文本都好。
- 利用 LM 后的模型做微调。
- 有了这两个模型后,有了相当大的提升
结果
- 常识性结论:
- 数据集更高,有所提升
- 模型变大,有所提升
- Captioner & FIlter:
- 用了哪个都会有提升。
- 用了 Captioner 提升更加显著
- 而且完全可以利用这两个去训练其他模型
使用例
- 有位同学想要利用 Stable Diffusion 做一个生成宝可梦风格的模型,得到了宝可梦的图片但是没有描述。
- 利用 BLIP 生成描述。
- LAION COCO 数据集
- 用一个 BLIP 和 2 个 CLIP 模型不停做 Caption & filter 的过程
- 用 BLIP 生成 40 个描述
- 再利用一个 CLIP 排序,选最好的 5 个描述
- 再用另一个 CLIP(最大的模型) 得到最好的一个。
- 最后得到了 600 Million 数据集
- 用一个 BLIP 和 2 个 CLIP 模型不停做 Caption & filter 的过程
CoCa
论文标题:CoCa: Contrastive Captioners are Image-Text Foundation Models
作者来自 google
亮点:
- 两个 loss
- contrastive loss
- caption loss
- 模型更大
- 多模态&单模态都取得了非常强劲的效果
方法
模型

- CoCa 是 ALBEF 的后续工作,一些过程继承了 ALBEF 的过程,详细过程如下:
- 左边是 Image Encoder,右边是 Text Decoder
- 图像的 [CLS] token 和文本的 [CLS] token 做一个 contrastive loss,然后剩下的图像 token 做一下 Attention pooling,然后再传到 多模态的 Text Decoder 里做 Cross-Attention ,这样就把 V&L 的特征融合到一起了。
- 最后用了 Captioning Loss
- 与 ALBEF 的区别
- 图像的 attention pooling 是可学的,能针对不同任务学到更好特征。
- 文本这一端,不论是单文本还是多模态用的都是 Decoder。
- 采用 Captioning Loss 与 Decoder 结构目的是加快运算速度。
- 模型参数 2.1B
- 数据集:
- GFT 3B 转化成了多模态数据集
- 还有一个之前训练 Align 的数据集
结果
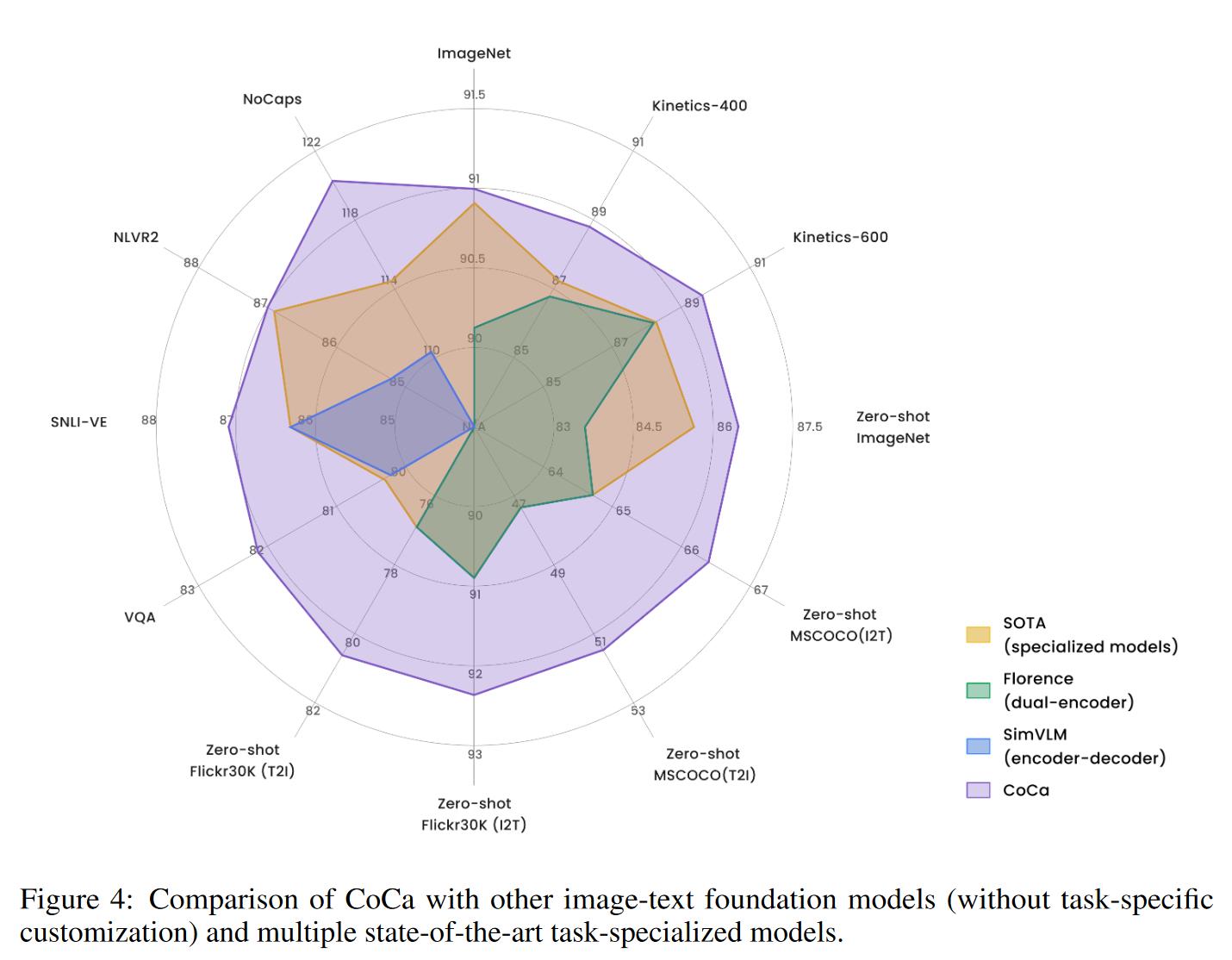
(我所见过最离谱的图)
BEITv3
论文题目:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
作者来自微软
亮点:
- 模型要统一
- 训练目标函数要统一
- 数据集大小要统一
- 独特的命名
- images -> Imglish
- texts -> English
- image-text pairs -> parallel sentence
- 目标函数 Masked Modeling loss
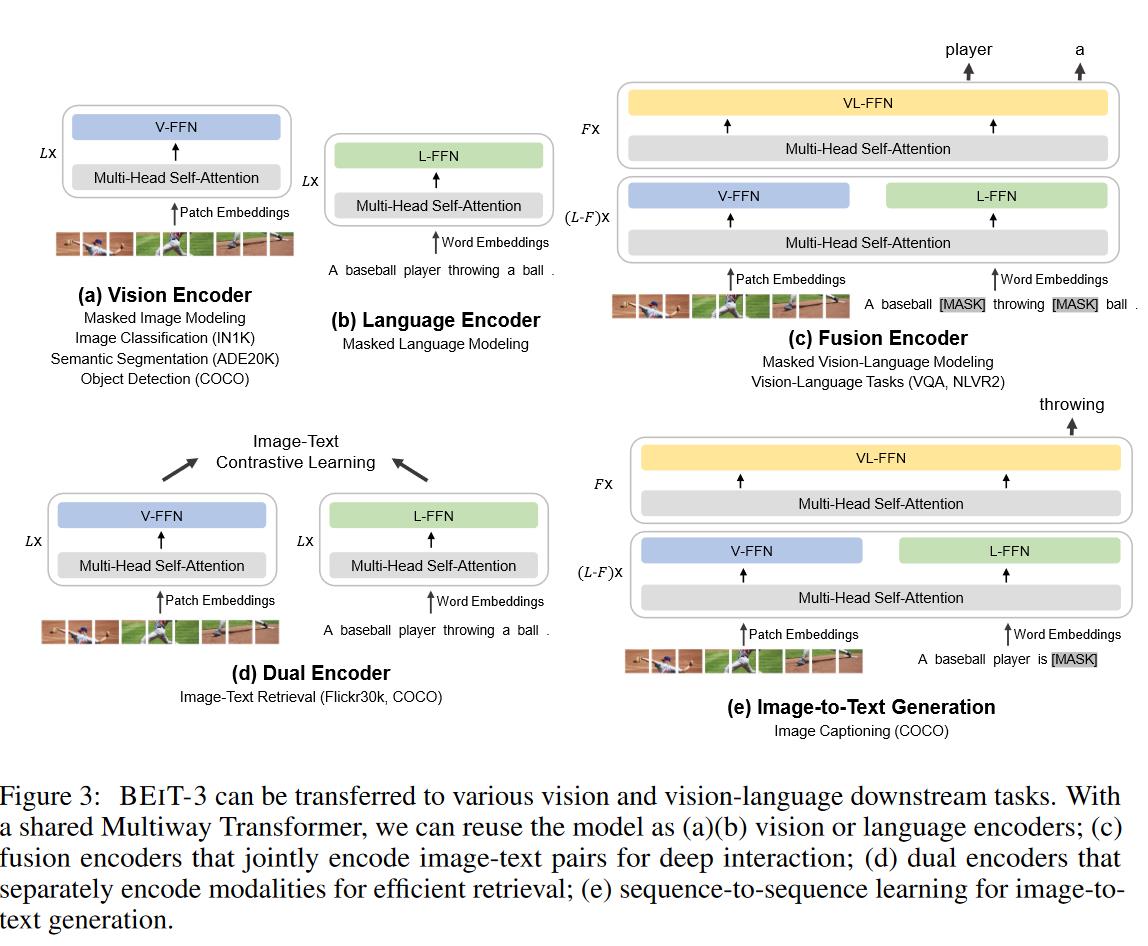
- 模型为之前 VLMo 提出的 MoME,然后这篇论文重新起了名字 Multi-way Transformers
- 由于模型结构灵活,因此推理时可以拆成许多部分做许多下游任务。
- 预训练数据集都是公开数据集
- 引言写的很好(如果要研究多模态要去看一下)
这篇论文证明了:
- 不是目标函数越多越好,要看目标函数是否有互补的特性
- 数据也不一定越多越好,质量也很关键
模型
预训练
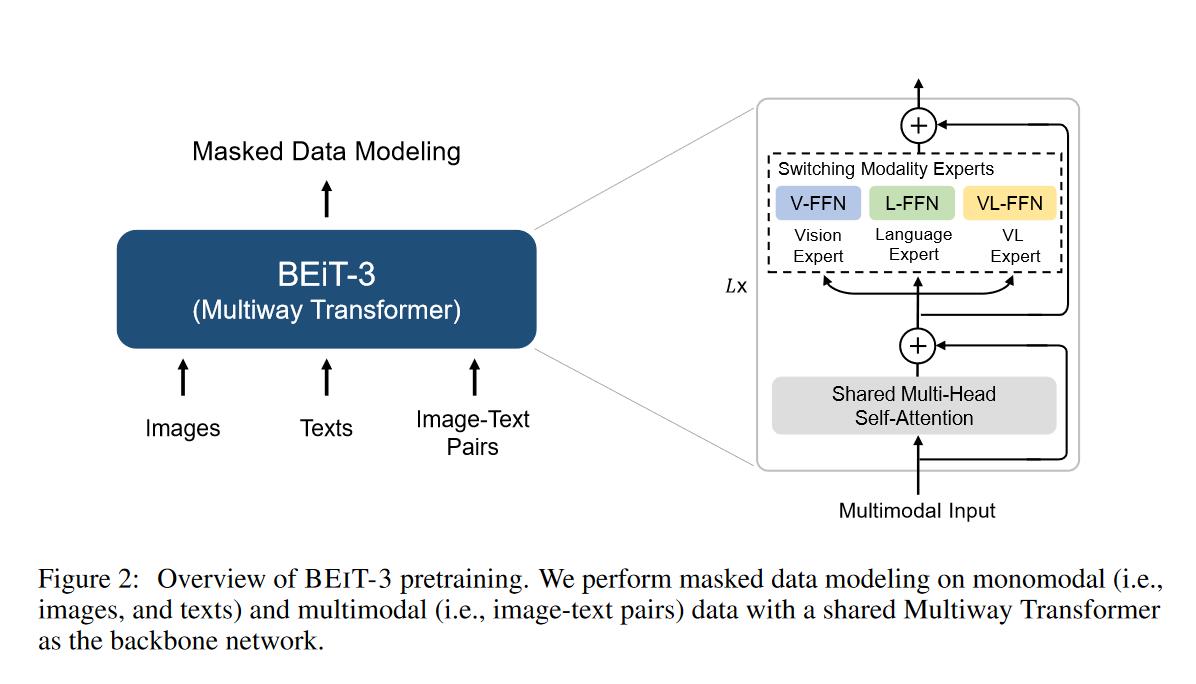
-
VLMo
微调
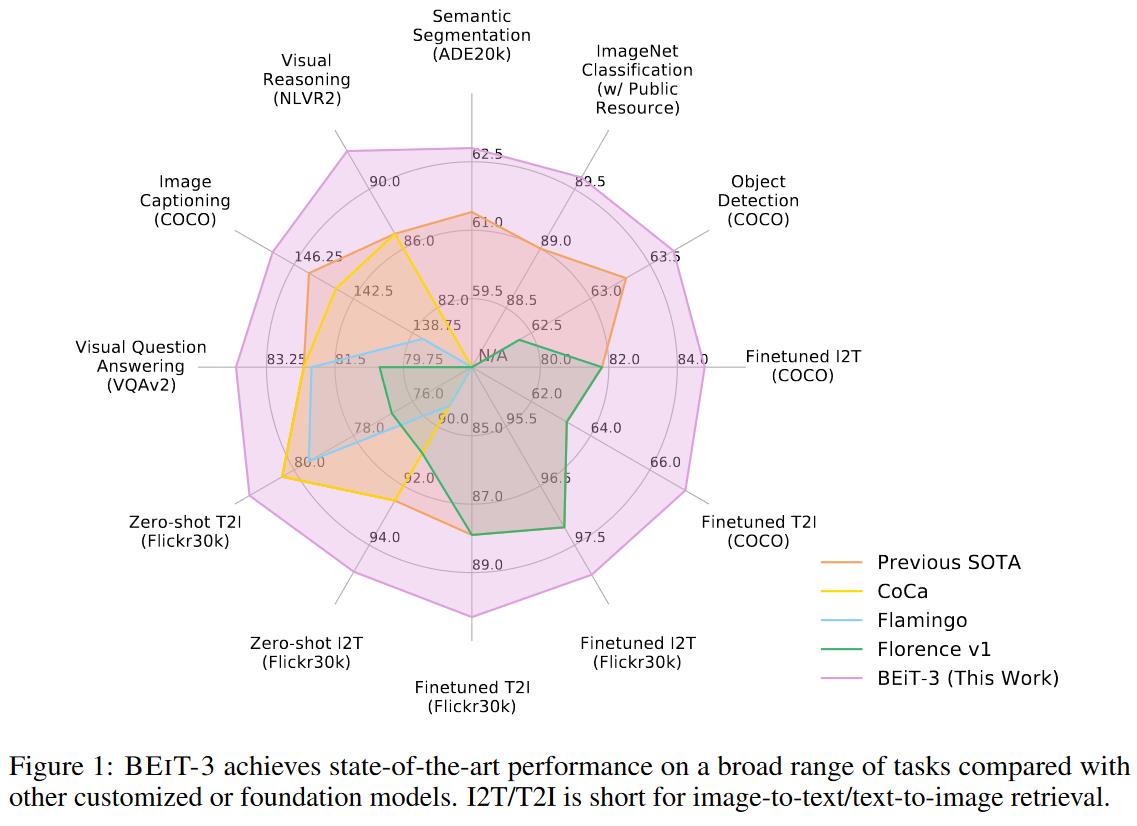
结果
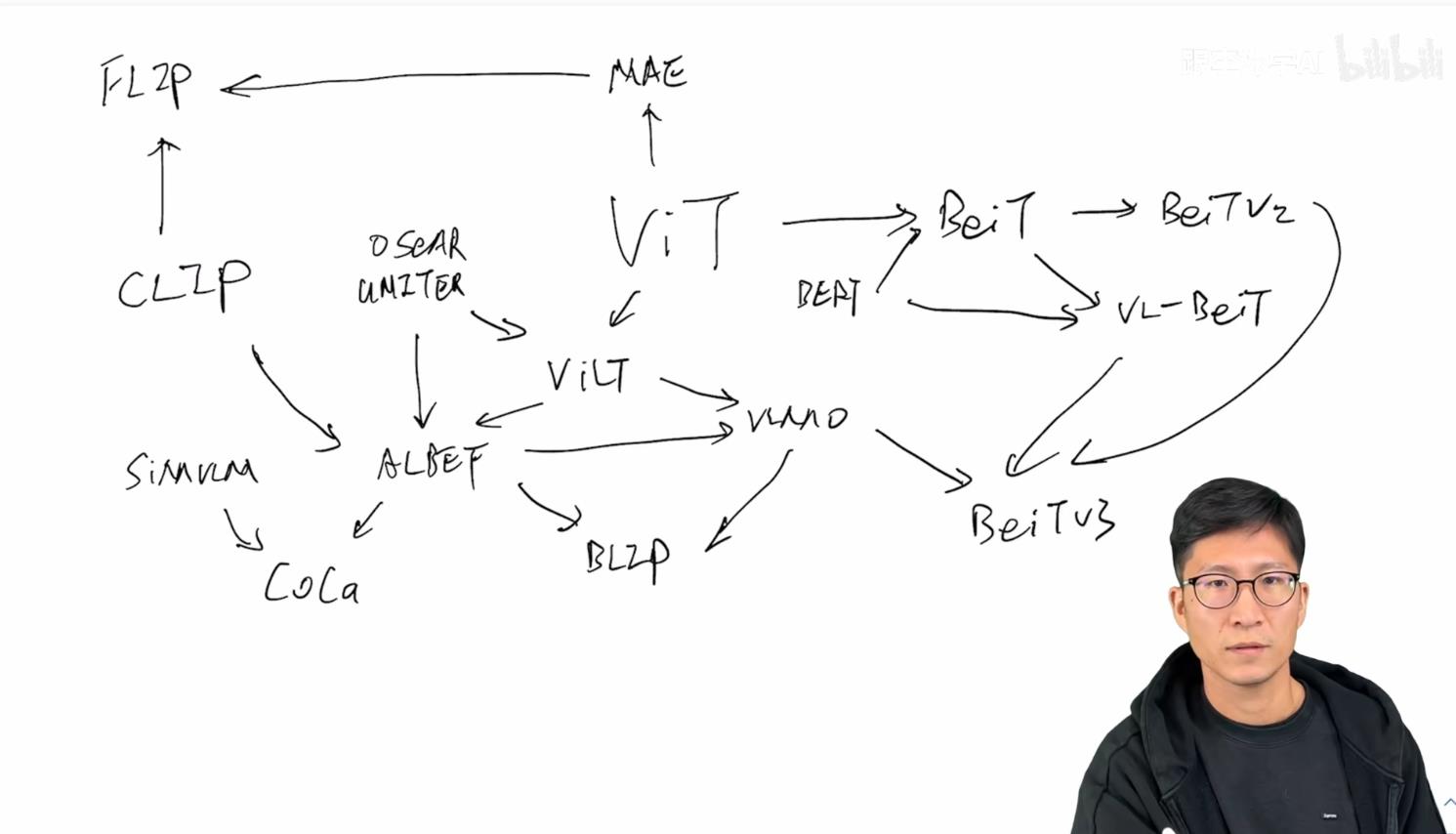
总结
以上是关于李沐多模态串讲视频总结 ALBEF VLMo BLIP CoCa BEITv3 模型简要介绍的主要内容,如果未能解决你的问题,请参考以下文章