python网络爬虫之beautfiulSoup
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python网络爬虫之beautfiulSoup相关的知识,希望对你有一定的参考价值。
BeautifulSoup将html文档转换成一个属性结构,每个节点都是python对象。这样我们就能针对每个结点进行操作。参考如下代码
def parse_url():
try:
req=urllib2.Request(‘http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml‘)
fd=urllib2.urlopen(req)
html=BeautifulSoup(fd)
except urllib2.URLError,e:
print e
BeautifulSoup中传入的就是urlopen中反馈的html网页。但是出现提示
E:\\python2.7.11\\python.exe E:/py_prj/test.py
E:\\python2.7.11\\lib\\site-packages\\bs4\\__init__.py:181: UserWarning: No parser was explicitly specified, so I‘m using the best available HTML parser for this system ("lxml"). This usually isn‘t a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 43 of the file E:/py_prj/test.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))
这个提示的意思是没有给BeautifulSoup中传递一个解析网页的方式。有2中方式可以使用:html.parser以及lxml。这里我们先用html.parser,lxml后面再讲。代码改成如下就OK了
html=BeautifulSoup(fd,"html.parser")
在解析网页前,我们先来看几个概念,标签,属性。
比如下面的网页结构。<a href=”1.shtml”>第一节</a> 其中a就是标签,里面的href就是属性。第一节就是标签的内容
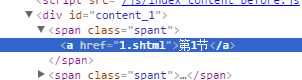
BeautifulSoup中查找属性的方法如下:
print html.meta.encode(‘gbk‘)
print html.meta.attrs
结合如下的代码,查找tag为meta的元素。并打印meta的所有属性:

得到的结果如下:
E:\\python2.7.11\\python.exe E:/py_prj/test.py
<meta content="text/html; charset=gbk" http-equiv="Content-Type"/>
{u‘content‘: u‘text/html; charset=gb2312‘, u‘http-equiv‘: u‘Content-Type‘}
如果想得到某项属性,可以按照如下的方式:
print html.meta.attrs[‘content‘] 输出结果是text/html
如果我们想得到标签的内容也就是文本怎么办呢,比如下面的这个方式

print html.title.string.encode(‘gbk‘) .string的功能就是得到标签所对应的文本
但是上面的方法只能找出第一个满足的标签,如果网页中有多个相同名字的标签该如何区分呢,比如下面的这种场景:有多个span以及a的标签
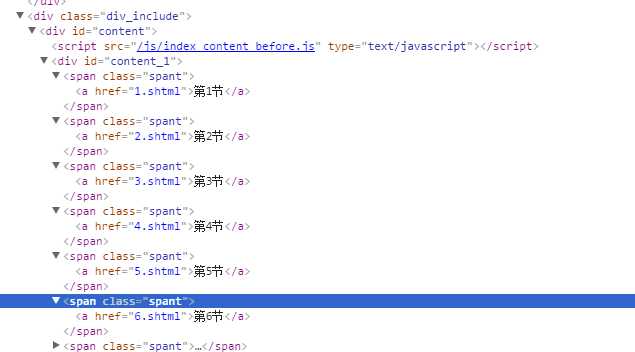
那么就需要另外的方式来获取。如下代码用find_all的方式来获取所有标签为a的结构并打印出来
for a in html.find_all(‘a‘):
print a.encode(‘gbk‘)
得到的结果如下,由于太多,只列出了其中一部分。

如果想得到这些节点的内容可以用get_text()的方法。如下:
for a in html.find_all(‘a‘):
print a.get_text()
如果想得到这些节点的全部属性,则可以用下面的方法:
for a in html.find_all(‘a‘):
print a.attrs
如果想得到某个属性的值,前面的a.attrs返回的是一个字典。比如下面的要获取class属性的值,用如下的方法
for a in html.find_all(‘a‘):
print a.attrs[‘class‘]
find_all方法还可以给查找加限定值:比如想获取如下所示的<a href=”1.shtml”>的标签
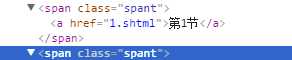
这里第一个参数代表标签名字,第二参数代表属性名
for a in html.find_all(‘a‘,href="1.shtml"):
print a.encode(‘gbk‘)
还可以设定多个参数查找,比如查找form这个标签
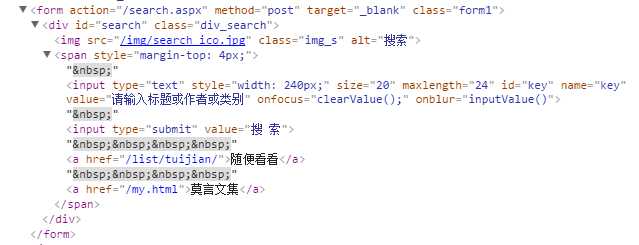
for a in html.find_all(‘form‘,method="post",target="_blank"):
print a.encode(‘gbk‘)
当然在查找里面也可以运用正则表达式,比如re.complie(“a.*”)之类的方法
另外还可以限制查找的数目:下面的表达式就是获取前5条查找结果
for a in html.find_all(‘a‘,limit=5):
print a.attrs[‘class‘]
find家族里面还有find_parents/find_parent查找父节点。Find_next_siblings()/find_next_sibling()查找下一个兄弟以及
find_previous_siblings()/find_previous_sibling()查找前面的兄弟节点。
以上是关于python网络爬虫之beautfiulSoup的主要内容,如果未能解决你的问题,请参考以下文章