python爬虫:两种方法模拟登录博客园
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫:两种方法模拟登录博客园相关的知识,希望对你有一定的参考价值。
第一方法用第三方库(requests):参考http://www.mamicode.com/info-detail-1839685.html
源代码分析
博客园的登录页面非常简单,查看网页源代码,可以发现两个输入框的id分别为input1、input2,复选框的id为remember_me,登录按钮的id为signin。
还有一段JavaScript代码,下面来简单分析一下。
先来看$(function(){});函数:
1 $(function () {
2 $(‘#signin‘).bind(‘click‘, function () {
3 signin_go();
4 }).val(‘登 录‘);
5 });
$(function(){});是$(document).ready(function(){})的简写。当页面加载完成之后,$(function(){})里的代码就会被执行。
$(‘#signin‘)表示选取id为signin的元素,即登录按钮。
bind()方法为被选元素添加一个或多个事件处理程序,并规定事件发生时运行的函数。
val()方法返回或设置被选元素的值。
当点击登录按钮时,将执行signnin_go()函数。
JSEncrypt是一个用于RSA加密的库。在signnin_go()函数中,通过JSEncrypt对用户名和密码进行了加密,setPublicKey()函数里面就是加密的公钥。
$(‘#remember_me‘).prop(‘checked‘)返回复选框的状态,勾选时返回true,否则返回false。
两段加密后的密文和复选框的状态被保存在一个名为ajax_data的对象里。代码如下:
1 var encrypt = new JSEncrypt();
2 encrypt.setPublicKey(‘MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCp0wHYbg/NOPO3nzMD3dndwS0MccuMeXCHgVlGOoYyFwLdS24Im2e7YyhB0wrUsyYf0/nhzCzBK8ZC9eCWqd0aHbdgOQT6CuFQBMjbyGYvlVYU2ZP7kG9Ft6YV6oc9ambuO7nPZh+bvXH0zDKfi02prknrScAKC0XhadTHT3Al0QIDAQAB‘);
3 var encrypted_input1 = encrypt.encrypt($(‘#input1‘).val());
4 var encrypted_input2 = encrypt.encrypt($(‘#input2‘).val());
5 var ajax_data = {
6 input1: encrypted_input1,
7 input2: encrypted_input2,
8 remember: $(‘#remember_me‘).prop(‘checked‘)
9 };
然后就是最主要的$.ajax({})函数了,ajax()方法通过HTTP请求加载远程数据,在不刷新页面的情况下与服务器交换数据,返回其创建的 XMLHttpRequest 对象。详情请参考jQuery ajax - ajax() 方法
1 $.ajax({
2 url: ajax_url,
3 type: ‘post‘,
4 data: JSON.stringify(ajax_data),
5 contentType: ‘application/json; charset=utf-8‘,
6 dataType: ‘json‘,
7 headers: {‘VerificationToken‘: ‘。。。省略,此处是一大串字符。。。‘},
8 success: function (data) {
9 if (data.success) {
10 $(‘#tip_btn‘).html(‘登录成功,正在重定向...‘);
11 location.href = return_url;
12 } else {}
13 },
14 error: function (xhr) {}
15 });
上面的代码中做了一些省略。需要特别注意的是headers属性,刷新之后,VerificationToken的值将会改变,所以在模拟登录时,必须先获取这一段字符串。登录成功后,页面将进行跳转。
抓包分析
这是登录时的POST请求,其中有3个参数要特别注意:
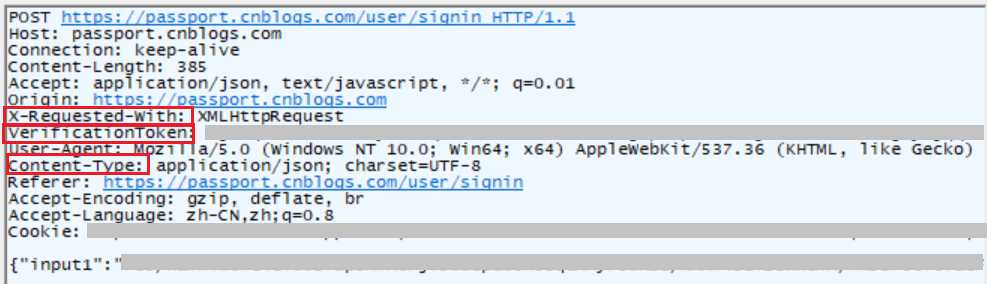
VerificationToken就是上文中提到的一段变化的字符串。
Ajax异步请求比传统的同步请求多了一个头参数,即X-Requested-With。
Content-Type用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些Asp网页点击的结果却是下载到的一个文件或一张图片的原因。在这里返回的是json格式的数据。当输入错误的用户名和密码时,将得到下面的json数据:
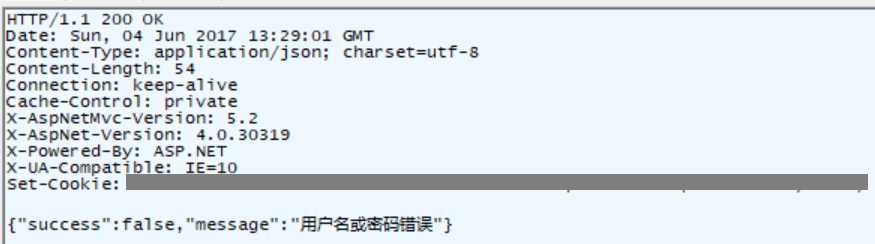
正确的用户名和密码将得到{"success":true}
1 import requests 2 import json 3 login_url="https://passport.cnblogs.com/user/signin" 4 return_url="https://home.cnblogs.com/u/xxx/"#我的主页 5 session=requests.session() 6 #获取VerificationToken 7 login_page=session.get(login_url) 8 p=login_page.text.find(‘VerificationToken‘)+len(‘VerificationToken‘)+4 9 token=login_page.text[p:login_page.text.find("‘",p)] 10 print(token) 11 headers={ 12 ‘Content-Type‘: ‘application/json;charset=UTF-8‘, 13 ‘X-Requested-With‘: ‘XMLHttpRequest‘, 14 ‘VerificationToken‘:token 15 } 16 session.headers.update(headers) 17 #可以通过抓包获取加密后的用户名和密码,我将在附录部分介绍如何在Python中加密 18 data={ 19 ‘input1‘: "加密的用户名", 20 ‘input2‘: "加密的密码", 21 ‘remember‘:True 22 } 23 24 #模拟登录 25 response=session.post(login_url,data=json.dumps(data)) 26 print(response.text) 27 #{"success":true} 28 #登录成功 29 30 #跳转到主页 31 home_page=session.get(return_url) 32 #获取主页标题 33 p=home_page.text.find(‘<title>‘)+len(‘<title>‘) 34 title=home_page.text[p:home_page.text.find(‘</title>‘,p)] 35 print(title) 36 #xxx的主页 - 博客园 37 #如果登录失败,跳转到主页时返回的结果没有title标签,home_page.text将为‘需要登陆‘
第二种方法:用自带的库(urllib.request)
1 #-*- coding:utf-8 -*- 2 __author__ = ‘Administrator‘ 3 4 #coding:utf-8 5 import re 6 from bs4 import BeautifulSoup 7 import urllib.request 8 import urllib.parse 9 import http.cookiejar 10 import requests 11 12 13 def get_opener(): 14 cj=http.cookiejar.CookieJar() 15 pro=urllib.request.HTTPCookieProcessor(cj) 16 opener=urllib.request.build_opener(pro) 17 return opener 18 19 if __name__=="__main__": 20 opener=get_opener() 21 login_url="https://passport.cnblogs.com/user/signin" 22 return_url="https://home.cnblogs.com/u/xxx/"#我的主页 23 24 #获取VerificationToken 25 login_page=opener.open(login_url).read().decode(‘utf-8‘) 26 soup=BeautifulSoup(login_page,"html.parser") 27 script=soup.find_all(‘script‘) 28 scripttext=script[2].string.strip() 29 p=re.findall(‘\\‘VerificationToken\\‘: \\‘.*?\\‘‘,scripttext)[0] 30 start=len(‘VerificationToken‘)+5 31 token=p[start:-1] 32 33 headers={ 34 ‘Content-Type‘: ‘application/json;charset=UTF-8‘, 35 ‘X-Requested-With‘: ‘XMLHttpRequest‘, 36 ‘VerificationToken‘:token 37 } 38 39 #可以通过抓包获取加密后的用户名和密码 40 data={ 41 ‘input1‘: "加密的用户名", 42 ‘input2‘: "加密的密码", 43 ‘remember‘:True 44 } 45 heads=[] 46 for key,value in headers.items(): 47 heads.append((key,value)) 48 login_data=urllib.parse.urlencode(data).encode(‘utf-8‘) 49 opener.addheaders=heads 50 Req=urllib.request.Request(login_url,data=login_data) 51 response= opener.open(Req) 52 print(response.read().decode(‘utf-8‘)) 53 #{"success":true} 54 #登录成功 55 56 #跳转到主页 57 home_page=opener.open(return_url) 58 #获取主页标题 59 soup=BeautifulSoup(home_page.read().decode(‘utf-8‘),"html.parser") 60 p=soup.find(‘title‘) 61 print(p.text) 62 #xxx的主页 - 博客园 63 #如果登录失败,跳转到主页时返回的结果没有title标签,则‘需要登陆‘
以上是关于python爬虫:两种方法模拟登录博客园的主要内容,如果未能解决你的问题,请参考以下文章
在Python中用Request库模拟登录:博客园(简单加密,无验证码)