Python开发基础-Day1-python入门
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python开发基础-Day1-python入门相关的知识,希望对你有一定的参考价值。
编程语言分类
机器语言
使用二进制代码直接编程,直接与硬件交互,执行速度非常快,灵活,但是开发难度高,开发效率低下,缺乏移植性。
汇编语言
对机器语言指令进行了英文封装,较机器语言容易记忆,直接与硬件交互,执行速度快,执行文件小,但是开发难度相对也很高,开发效率低
高级语言
语法简单,容易理解,开发难度低效率高,开发后测试方便,但是开发的程序需要经过转换才能执行,所以执行效率相对慢,可移植性高。
解释执行:代码执行时候,解释器按照源代码文件中的内容,一条条解释并运行,相对编译执行速度慢,但出错方便调试,开发效率高。
例如Python、PHP、Ruby、JavaScript等
编译执行:程序执行前,编译器会将源代码一次性编译成机器能够识别的指令文件,然后运行编译后的文件,速度相对表解释执行要高,但是出错后修改源代码需要重新编译执行,开发效率相对低
例如C语言、C++、GO、Swift、Object-C等
解释执行和编译执行在执行效率上虽然有差别,但是对于当前计算机的硬件计算速度的提升,加上网络环境的限制,执行速度相对来说并不是关键,开发效率才是关键。
像Java和C#属于混合语言,即既有编译执行也有解释执行。
Python简介
Python介绍
Python是一门解释型编程语言,平台兼容性高,省略一堆屁话,这是笔记!!!!
解释型语言依赖于解释器,python解释器执行代码文件的过程如下:
打开python解释器
python解释器从硬盘调用py文件到内存
python解释器执行读入内存的文件代码,该过程详细为:py文件-字节码文件-解释器-机器码-执行
python文件在执行过程中,不会保存字节码文件,每次执行py文件时候,都会先转化成字节码文件。
python在import(导入)py文件的时候,会生成pyc的字节码文件保存下来。
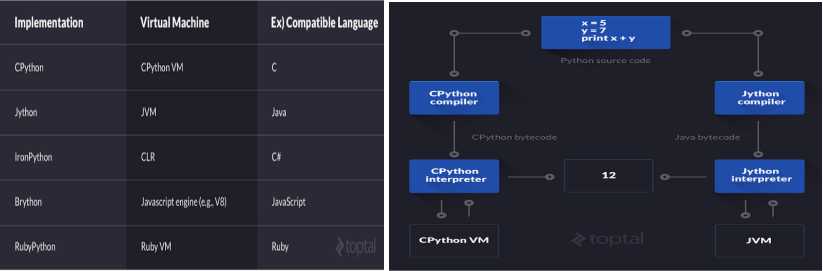
Python分类
Cpython(最常用):使用C语言实现的python,官方版本,Cpython会将源代码文件转换成pyc字节码文件使用到python虚拟机上执行
Jpython:使用Java实现的python,将Python代码动态编译成Java字节码,然后在JVM上运行
IronPython:Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行
PyPy(特殊):Python实现的Python,将Python的字节码字节码再编译成机器码
RubyPython、Brython.....
除了PyPy外,执行流程如下图:
代码文件首先转换层字节码文件,字节码文件流入解释器,解释器转化成机器码后执行输出。
Python解释器版本
版本3,最新的版本为3.6.1
版本2,最新的版本为2.7.13,2020年停止更新
Python入门
安装
Python Linux版本安装
安装过程转 http://www.cnblogs.com/zero527/p/6920965.html
Python Windows版本安装
双击安装,一路下一步,记得勾选自动添加环境变量
第一行代码"hello world"
解释器只用来测试代码,并不能保存代码,想要永久保存,需要将代码写入到文件中。
解释器执行:
C:\\Users\\Mr.chai>python Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> "hello world" #由于解释器自带输出功能,所以输入一个字符串会自动给出输出 ‘hello world‘ >>> print("hello world") #print为输出,输出的内容是括号中的内容 hello world >>>
py文件执行:
创建一个hello.py文件,内容写入print("hello world")
C:\\Users\\Mr.chai>python C:\\hello.py
hello world
python文件头(linux)
在linux执行hello.py文件,也是用python 路径/hello.py,但是在linux可以用./方法执行文件,直接执行./hello.py,会报错,原因是找不到解释器,所以要在hello.py文件中加一个头部信息,标识解释器位置
#!/usr/bin/env python #该行只对linux有效,表示/usr/bin/所有的python解释器,可以指定一个如:/usr/bin/python # -*- coding: utf-8 -*- #指定字符编码
print(‘hello world‘)
内容注释
注释为说明性文字
# 单行注释
‘‘‘ str...str ‘‘‘ 三引号为多行注释
模块功能导入
import sys 导入系统模块,允许该文件运行扩展的系统功能
变量
变量是用来表示程序运行时候改变的状态的,是一个抽象的概念。
变量组成:
[变量名]=[变量实际的值]
变量名:变量命名一般字母或下划线开头,剩下的可以是字母和数字,变量名不能和关键字冲突,如print、and等系统关键字
变量值:可以改变的值,一个变量名可以重复赋值,但是变量实际的值为最后赋值后的值,变量的值存放在内存空间
变量类型:
局部变量:只在某一段代码中生效的变量
全局变量:在整个程序的运行中生效的变量
变量赋值与调用:
#!/usr/bin/env python # -*- coding: utf-8 -*- name="bob" #赋值字符串 age=20 #赋值整数 print(name,age) #输出变量
print("my name is %s,i am %s years old." % (name,age)) # %s表示占位,第一个%s调用后面括号里面的第一个变量,第二个%s调用第二个变量
重复赋值指的是改变变量名的引用,引用的值改变了。
id后面跟变量,查看内存id号
>>> a=1 >>> id(a) 1379185728 >>> b=1 >>> id(b) 1379185728
变量占用的内存空间比较小的,不再开辟内存空间,将直接引用,如果占用的内存空间大,那引用的过程中将开辟新的内存空间,这是python的一种优化机制
>>> a="abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz" >>> id(a) 2884867588944 >>> b="abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz" >>> id(b) 2884867588624
输入输出
python2中的raw_input()个python3中的input()功能一样,会把所有用户的输入转成str类型
>>> name=input("name:") name:bob >>> age=input("age:") age:20 >>> type(name) <class ‘str‘> >>> type(age) <class ‘str‘>
getpass模块,可以隐藏输入
>>> password=getpass.getpass("pass:") pass: >>> print(password) 123456
getpass模块,隐藏密码输入
import getpass
name=input("用户名:")
password=getpass.getpass(‘密码:‘)
print("用户名:%s 密码:%s" % (name,password)
以上是关于Python开发基础-Day1-python入门的主要内容,如果未能解决你的问题,请参考以下文章