Hive企业实战ORC表数据翻倍,颠覆你认知的Cluster by作用?
Posted 涤生大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive企业实战ORC表数据翻倍,颠覆你认知的Cluster by作用?相关的知识,希望对你有一定的参考价值。
咱们玩开源和大数据领域的几乎天天和Exception和Error打交道,尤其是面对海量数据的存储计算,复杂业务场景的时候。
真正能让你学到东西的大数据都需要是符合大数据特点的数据,比如低价值密度,如何从一眼看不出价值的数据中挖掘出商业价值,颠覆你的认知。比如海量数据计算,遇到性能瓶颈时我们如何调优,没有性能瓶颈的调优都是脱裤子放屁。比如数据的复杂多样性,面对复杂业务场景如何管理数据,数仓架构,数据建模,几万张表,几十万张的管理跟你几百张的难度可不是线性倍增的。
1.事故与故事背景
今天公司新来的小趴菜同事提出了一个问题,代码部门整合后脱敏(当然实际代码很长)。如下两个表进行leftjoin,结果表的总条数没变都是596亿行,字段个数也没变,字段也没做过啥处理,但是结果表的总存储变变成了3TB(单副本)
如下代码,两个表进行join,分布式a left join b ,两表信息如下:leftjoin源表a: dws_device_pkg_install_status_180d_df_md表默认存储格式ORC分区20210530 总行数596亿行,资产上看分区存储大小单副本500G.join的b表,XXX_test.dws_device_pkg_install_status_180d_df_md数据量大概几十亿,大概存储单副本95G;INSERT overwrite TABLE dm_xxx_topi.dws_device_pkg_install_status_180d_df_tmp4 partition(DAY='20221122')SELECT a.device,a.pkg,install_datetime,unstall_datetime,all_datetime,df_final_time,final_flag,final_time,coalesce(b.refine_final_flag, a.reserved_flag) as reserved_flag,process_time from( SELECT device, pkg, install_datetime, unstall_datetime, all_datetime, df_final_time, final_flag, final_time, reserved_flag, process_timeFROM dm_xxx_topi.dws_device_pkg_install_status_180d_dfWHERE DAY = '20210530' ) aLEFT JOIN(select device,pkg,refine_final_flagfrom XXX_test.dws_device_pkg_install_status_180d_df_md group by device,pkg,refine_final_flag ) bON a.device = b.device and a.pkg = b.pkg

2.Trouble Shooting 来了
这个问题很奇怪吧,就是简单的a left joinb,如果数据量没有变多,字段也没有变长变多,同一个集群环境,按理来说数据应该不会膨胀。那是为什么呢?
小趴菜说是不是集群问题?这个锅我不能背?既然不背锅,我就必须得找到证据,生产上除了问题有时候真的很难排查哇,全靠经验了
2.1 计算引擎问题?
首先想到最简单的问题?是hive的问题?那我换个spark引擎试试?结果小趴菜说他试了,没问题,spark跑也是数据翻倍。
2.2 是数据问题,集群参数问题?
是不是数据本身相关问题,比如文件数,集群参数,客户端环境等,于是直接跑了个存map的任务;
INSERT overwrite TABLE dm_xxx_topi.dws_device_pkg_install_status_180d_df_tmp4 partition(DAY='20221122')SELECT a.device,a.pkg,install_datetime,unstall_datetime,all_datetime,df_final_time,final_flag,final_time,reserved_flag,process_time from( SELECT device, pkg, install_datetime, unstall_datetime, all_datetime, df_final_time, final_flag, final_time, reserved_flag, process_timeFROM dm_xxx_topi.dws_device_pkg_install_status_180d_dfWHERE DAY = '20210530' ) a
发现存map任务的数据符合结果预期,596亿条,最后的文件大小会随着文件个数等略微变化,但整体都在500G上下,跟之前3TB差别很大。
既然存Map任务没有问题,难道是map结果输出执行了压缩,reduce结果没有压缩吗?排查了了集群配置,客户端配置等,发现并不是这个问题。就是只有shuffle时才有这种问题,那就应该是shuffle对数据二次分发造成的问题,以为存map任务不牵涉数据的重新分发。
2.3 shuffle造成的问题?
既然排查到shuffle造成的问题,就很尴尬了,这个任务代码看不出啥问题。当时我就懵逼了,去扒拉一下ORC的官网,orc的源码,也没找到啥思路或者突破口,放张图,证明我确实看过
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC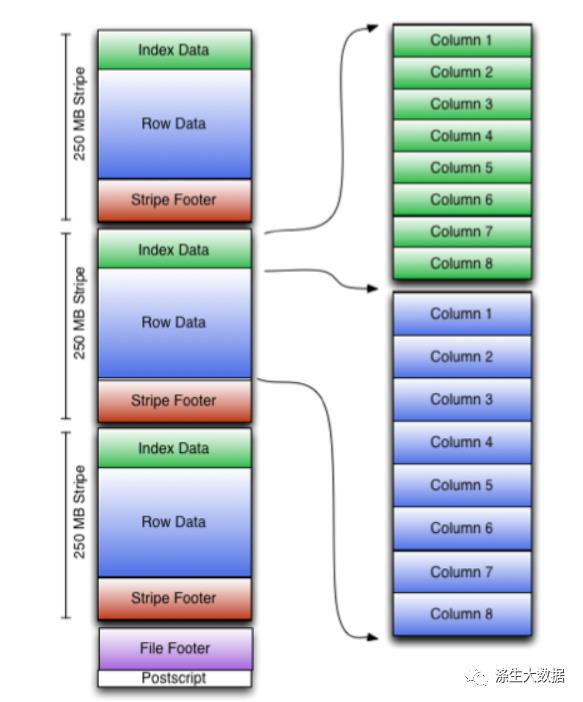
还是回到shuffle的问题,因为实际测试看,只有shuffle造成了数据膨胀,那就是问题处在shuffle上,shuffle的作用干啥?大家回忆一下,shuffle的过程其实就是对map输出的kv键值对,使用key按照hash算法进行分发到不同的reuduce上,shuffle过程基本就是:分区+排序+分发,reduce的过程就是合并排序+计算。
这么一看,有点思路了,应该大概率是排序造成的。因为排序对压缩的影响性能很大?来先学习下压缩的原理知识
压缩原理其实很简单,就是找出那些重复出现的字符串,然后用更短的符号代替,从而达到缩短字符串的目的。
比如,有一篇文章大量使用"中华人民共和国"这个词语,我们用"中国"代替,就缩短了 5 个字符,如果用"华"代替,就缩短了 6 个字符。事实上,只要保证对应关系,可以用任意字符代替那些重复出现的字符串。本质上,所谓"压缩"就是找出文件内容的概率分布,将那些出现概率高的部分代替成 更 短 的 形 式 。所 以 , 内 容 越 是 重 复 的 文 件 , 就 可 以 压 缩 地 越 小 。比 如 ,“ABABABABABABAB"可以压缩成"7AB”。
相应地,如果内容毫无重复,就很难压缩。极端情况就是,遇到那些均匀分布的随机字符串,往往连一个字符都压缩不了。比如,任意排列的 10 个阿拉伯数字(5271839406),就是无法压缩的;再比如,无理数(比如 π)也很难压缩。

为了验证这个想法,我看了下源表: dws_device_pkg_install_status_180d_df的生成业务逻辑,发现这个表是通过很多表加工而来,这个表生成的时候通过device进行shuffle的(这个表生成的十几张原表通过device-join聚合而来,所以其实数据是通过device进行hashshuffle而来的)。这个表的每个分区大概都是500亿-700亿行数据,分区大小单副本500G上下。而现在我们生成的结果是shuffle的条件是device+pkg连个复合键。
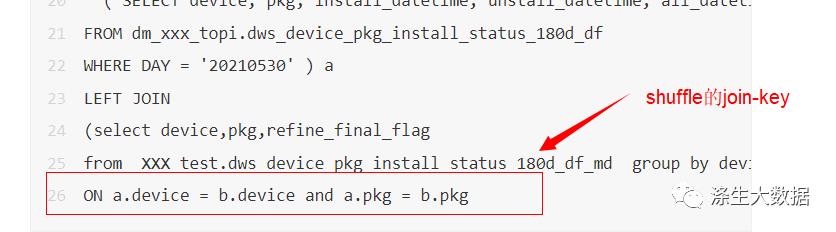
于是乎,为了验证是shuffle造成,是因为shuffle的hash-key不同造成的,于是乎,我给小趴菜上面代码加了个cluster-by-device,让最后的结果集通过device进行shuffle,重新落地。
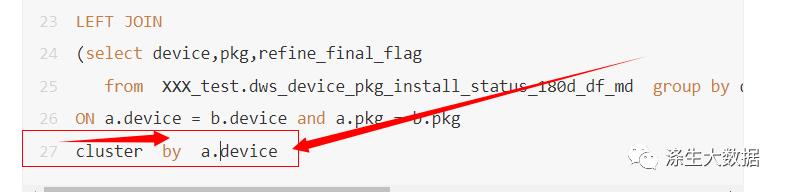
测试了下,结果集立马变成了596亿,文件存储大概500G左右,解决问题。继续测试验证,结果如此。

为什么会出现这种问题呢?
因为这个表里device字段有大量的重复值,如果你用device进行shuffle的话,那么同样device,或者相近的device会被分配到同一个reduce里,这样最后orc列式存储时会有非常高的压缩率,重复值越高,压缩率越高。这个时候你换成device+pkg作为shuffle过程的hash-key,那么数据会打的更散,这个时候压缩率会有影响,造成跟之前相比会有膨胀。
这种问题生产很常见,我们生产上有很多代码最后都加了一个cluster by ,小趴菜当时还有疑问,为啥最后要加个这个呢,看上去没啥功能作用哇,对业务加工也没啥帮助哇。
这就是因为clusterby有时候用的好,对orc表降低存储有巨大的好处,尤其生产上某个字段有大量重复值的时候,比如电商公司,某个商铺以王者一般承担了大量的订单。
最后考大家一个问题,这个如何生产上更好的避免这种数据膨胀的问题?
这种面试的时候你吹起来工作中遇到过哪些问题?不比你背的八股文牛逼,不说了,点赞关注收藏起来哈

以上是关于Hive企业实战ORC表数据翻倍,颠覆你认知的Cluster by作用?的主要内容,如果未能解决你的问题,请参考以下文章