吃瓜教程——datawhale10月组队学习
Posted scdctlt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吃瓜教程——datawhale10月组队学习相关的知识,希望对你有一定的参考价值。
datawhale的十月组队学习——吃瓜教程
task01:概览西瓜书+南瓜书第1、2章
第一章 绪论
1、 机器学习的一些符号定义(结合林轩田的机器学习)
X:样本空间
Y:输出空间
A:算法合集
D:数据集
f:理想目标函数
g:近似目标函数

2、根据训练数据是否有标记信息,可以将学习任务分两大类

对于无label的数据集,利用数据间关系分类过程称为“聚类”(clustering)
对于有label的数据集,根据要预测的值是离散的还是连续的,可以把学习任务分为:
- 分类问题(classification)
- 回归问题(regression)
模型在训练集上做的训练,对于未参与训练的新数据,学得模型适用于新样本的能力称为“泛化”(generalization)能力
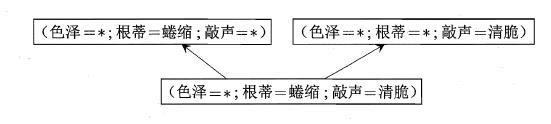
3、可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行
搜索的过程,搜索目标是找到与训练集"匹配" 的假设

可以有许多策略对这个假设空间进行搜索,例如自顶向下、从一般到特殊,或是自底向上、从特殊到一般,搜索过程中可以不断删除与正例不一致的假设、和(或)与反例→致的假设.最终将会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设,这就是我们学得的结果.
第二章 模型评估与选择
学习器在训练集上的误差称为"训练误差" (training error)或"经验误差" (empirical error) ,在新样本上的误差称为"泛化误差" (generalizationerror).
-
对于分类问题:分类错误的样本数占样本总数的比例称为"错误率" (errorrate) ,即如果在m 个样本中有α 个样本分类错误,则错误率E= α/m; 相应的,1 /m 称为"精度" (accuracy) ,即"精度=1-错误率"
-
对于回归问题: 回归任务最常用的性能度量是"均方误差" (mean squared error)
-
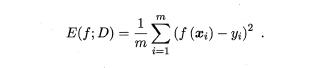
学习器将训练样本学的太好,会导致泛化能力下降,会造成“过拟合”
学习器将训练演变一般性质都尚未学好,称为“欠拟合”

一般将数据集拆分为两个互斥的数据集,训练集和测试集
常见两种方法:
- 留出法:“留出法” (hold-out)直接将数据集D 划分为两个互斥的集合?其中一个集合作为训练集S,另一个作为测试集T,在S上训练出模型, 用T 来评估其测试误差,作为对泛化误差的估计.
- 交叉验证法:“交叉验证法” (cross validation)先将数据集D 划分为k 个大小相似的互斥子集,每个子集Di 都尽可能保持数据分布的一致性,即从D 中通过分层采样得到. 然后,每次用k-1 个子集的并集作为训练集?余F 的那个子集作为测试集;这样就可获得k组训练和测试集,从而可进行k 次训练和测试? 最终返回的是这k 个测试结果的均值

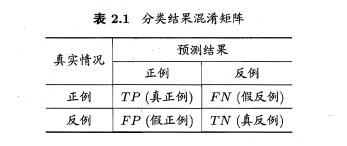
对于分类结果的混淆矩阵:
以上是关于吃瓜教程——datawhale10月组队学习的主要内容,如果未能解决你的问题,请参考以下文章