03 CenterOS7.9 安装K8s过程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了03 CenterOS7.9 安装K8s过程相关的知识,希望对你有一定的参考价值。
参考技术A防火墙等禁用
将桥接的IPv4流量传递到iptables的链
NTP时间同步
配置国内k8s镜像地址
k8s镜像仓库需要翻出去,所以配置国内镜像地址
安装K8s(安装和使能kubelet)
配置cgroupdriver=systemd
默认docker的Cgroup是cgroups,kubelet的Cgroups是systemd,两者的Cgroups不一样,两边需要修改成一致的配置
然后依据提示执行:
然后重新初始化
然后检查健康状况:
上面kubectl get cs结果显示系统不健康,解决方案如下:
把下面文件的 - --port=0注释掉,即前面加上#
修改kube-flannel.yml里面为(vi中使用:set number,然后 :106定位到106行):
2、高可用测试
接下来我们分别尝试删除pod和停止Container来测试高可用性:
修改内容为:
用firefox浏览器访问:访问https://192.168.2.130:30001
一共有3个Master:
master:192.168.108.88 k8s-master03
backup:192.168.108.87 k8s-master02
backup:192.168.108.86 k8s-master04
二个worker节点:
k8s-node1:192.168.100.49
k8s-node2:192.168.100.50
各个master把自己公钥发到同一个master上汇总(这里选用k8s-master01),然后分发到各个master上:
接下来把汇总的公钥分发给其他master主机(k8s-master02和k8s-master03):
到各个master上修改文件访问权限:
各个master节点依据自己情况做少量更改,主要是:
1、自己的被选举权重
2、自己的网卡名称
在本例中,主master节点配置(/etc/keepalived/keepalived.conf)为:
第一个备份master节点配置(/etc/keepalived/keepalived.conf):
第二个备份master节点配置为(/etc/keepalived/keepalived.conf):
仿造前面做node和master的配置(master到初始化master的前一步)这里略去,参考前面即可
鉴于我们是在非master高可用基础上做的高可用,即原来的master上曾经执行过kubeadm init,所以这里需要在这个节点上先执行reset操作(只需要在原来的那一个master节点上执行即可)
在MASTER上建一个脚本然后执行:
在所有其他的BACKUP master上建一个脚本然后执行:
Python 详解K-S检验与3σ原则剔除异常值
文章目录
一、引言
异常值分析是检验数据是否有录入错误,是否含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地将异常值放入数据的计算分析过程中,会对结果造成不良影响;重视异常值的出现,分析其产生的原因,经常成为发现问题进而改进决策的契机。
异常值是指样本中的个别值,其数值明显偏离其他的观测值。异常值也称为离群点,异常值分析也称为离群点分析。
而对于数据异常值的处理,3σ 原则是一种基于统计的方法,简单实用。
二、3σ原则
什么叫 3σ 原则呢?
- 3σ 原则,又叫拉依达原则,它是指假设一组检测数据中只含有随机误差,需要对其进行计算得到标准偏差,按一定概率确定一个区间,对于超过这个区间的误差,就不属于随机误差而是粗大误差,需要将含有该误差的数据进行剔除。
- 局限性:仅局限于对正态或近似正态分布的样本数据处理,它是以测量次数充分大为前提(样本>10),当测量次数少的情形用准则剔除粗大误差是不够可靠的。在测量次数较少的情况下,最好不要选用该准则。
3σ 原则:
- 数值分布在(μ-σ,μ+σ)中的概率为 0.6827
- 数值分布在(μ-2σ,μ+2σ)中的概率为 0.9545
- 数值分布在(μ-3σ,μ+3σ)中的概率为 0.9973
其中,μ 为平均值,σ 为标准差。一般可以认为,数据 Y 的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到 0.3%,这些超出该范围的数据可以认为是异常值。
在实验科学中有对应正态分布的 3σ 定律(Three-sigma Law),是一个简单的推论,内容是 “几乎所有” 的值都在平均值正负三个标准差的范围内,也就是在实验上可以将 99.7% 的机率视为 “几乎一定” 。不过上述推论是否有效,会视探讨领域中 “显著” 的定义而定,在不同领域,“显著” 的定义也随着不同,例如在社会科学中,若置信区间是在正负二个标准差(95%)的范围,即可视为显著。但是在粒子物理中,若是发现新的粒子,置信区间要到正负五个标准差(99.99994%)的程度。
即使在不是正态分布的情形下,也有另一个对应的 3σ 定律(three-sigma rule)。即使是在非正态分布的情形下,至少会有 88.8% 的机率会在正负三个标准差的范围内,这是依照切比雪夫不等式的结果。若是单模分布(unimodal distributions)下,正负三个标准差内的机率至少有95%,若符合特定一些条件的分布,机率可能会到 98% 。所以如果数据不服从正态分布,也可以用远离平均值的标准差的自定义倍数来描述。
三、K-S检验
可以使用 K-S 检验一列数据是否服从正态分布
from scipy.stats import kstest
kstest(rvs, cdf, args=(), N=20, alternative='two-sided', mode='auto')
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kstest.html

补充学习:
四、Python实现
Python实现步骤具体步骤如下:
- 首先需要保证数据列大致上服从正态分布(可以使用 box-cox 变换等);
- 计算需要检验的数据列的平均值 μ 和标准差 σ;
- 比较数据列的每个值与平均值的偏差是否超过 3 倍标准差,如果超过 3 倍,则为异常值;
- 剔除异常值,得到规范的数据。
K-S 正态分布检验和 3σ 原则剔除异常值,Python 代码如下:
import numpy as np
import pandas as pd
from scipy.stats import kstest
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
from scipy.special import inv_boxcox
def KsNormDetect(df):
# 计算均值
u = df['value'].mean()
# 计算标准差
std = df['value'].std()
# 计算P值
print(kstest(df['value'], 'norm', (u, std)))
res = kstest(df['value'], 'norm', (u, std))[1]
print('均值为:%.2f,标准差为:%.2f' % (u, std))
# 判断p值是否服从正态分布,p<=0.05 拒绝原假设 不服从正态分布
if res <= 0.05:
print('该列数据不服从正态分布')
print("-" * 66)
return True
else:
print('该列数据服从正态分布')
return False
def OutlierDetection(df, ks_res):
# 计算均值
u = df['value'].mean()
# 计算标准差
std = df['value'].std()
if ks_res:
# 定义3σ法则识别异常值
outliers = df[np.abs(df['value'] - u) > 3 * std]
# 剔除异常值,保留正常的数据
clean_data = df[np.abs(df['value'] - u) < 3 * std]
# 返回异常值和剔除异常值后的数据
return outliers, clean_data
else:
print('请先检测数据是否服从正态分布')
return None
if __name__ == '__main__':
# 构造数据 某一列数据 含有异常值
data = np.random.normal(60, 5, 200)
data[6], data[66], data[196] = 16, 360, 180
print(data)
print("-" * 66)
# 可以转换为pandas的DataFrame 便于调用方法计算均值和标准差
df = pd.DataFrame(data, columns=['value'])
# box-cox变换
lam = boxcox_normmax(df["value"] + 1)
df["value"] = boxcox1p(df['value'], lam)
# K-S检验
ks_res = KsNormDetect(df)
outliers, clean_data = OutlierDetection(df, ks_res)
# 异常值和剔除异常值后的数据
outliers = inv_boxcox(outliers, lam) - 1
clean_data = inv_boxcox(clean_data, lam) - 1
print(outliers)
print("-" * 66)
print(clean_data)
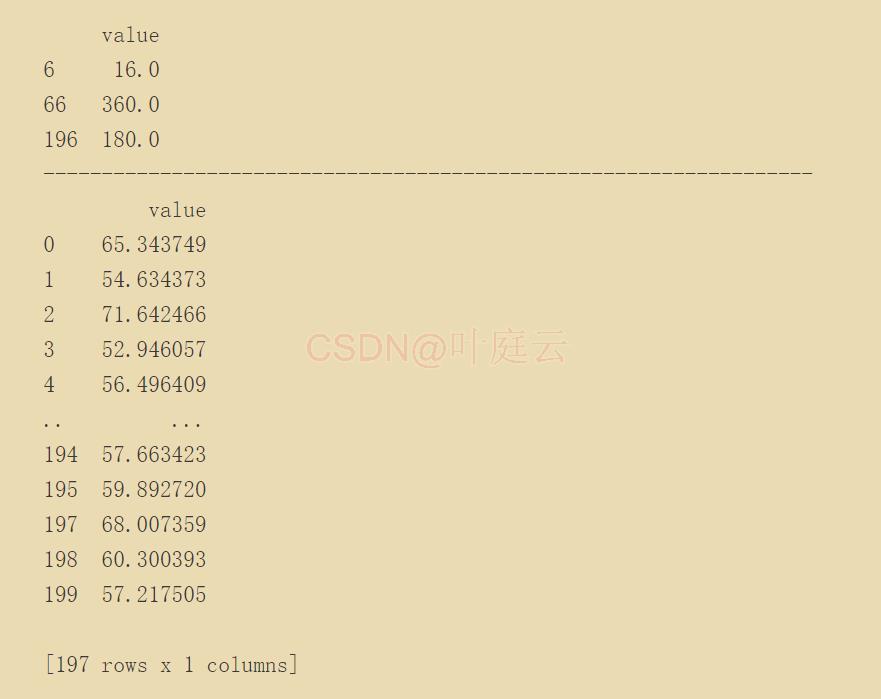
剔除异常值结果如下:
补充学习:
- Python 机器学习 | 正态分布检验以及异常值处理3σ原则
- Python实现基于3σ原则的异常值检测
- 知乎 | 机器学习中的异常值检测
- 公众号文章 | 什么是脏数据?怎样用箱形图分析异常值?终于有人讲明白了
以上是关于03 CenterOS7.9 安装K8s过程的主要内容,如果未能解决你的问题,请参考以下文章