Spark RDD数据过滤
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark RDD数据过滤相关的知识,希望对你有一定的参考价值。
参考技术A 过滤RDD中的数据通过查看 RDD的官方AIP ,可以使用两种方法,filter和collect结果正确,newRDD的数据符合过滤掉条件
同样可以达到filter的效果。
Spark RDD与MapReduce
什么是Map、什么是Reduce
MapReduce是一个分布式编程计算模型,用于大规模数据集的分布式系统计算。
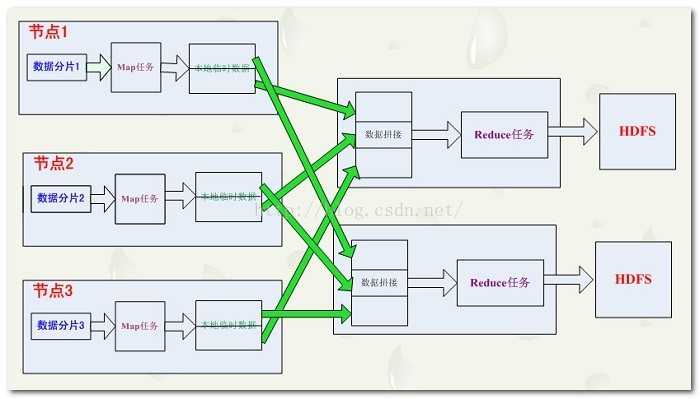
我个人理解,Map(映射、过滤)就是对一个分布式文件系统(HDFS)中的每一行(每一块文件)执行相同的函数进行处理;
Reduce(规约、化简)就是对Map处理好的数据进行两两运算,因此reduce函数必须要有两个参数。
Map/Reduce的执行原理其实可以参考python的map/reduce函数:
Spark中的MapReduce
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD也支持常见的MapReduce操作。
RDD操作:
-
-
转换操作:
每一次转换操作都会产生不同的RDD,供给下一个“转换”使用。转换得到的RDD是惰性求值的,并不会发生真正的计算,只是记录了转换的轨迹,只有遇到行动操作时,才会发生真正的计算。
-
filter(func):筛选出满足函数func的元素,并返回一个新的数据集
-
map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集
-
flatMap(func):与map()相似,但每个输入元素都可以映射到0或多个输出结果
-
groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
-
reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合。
reduceByKey 函数应用于(Key,Value)格式的数据集。
reduceByKey 函数的作用是把 key 相同的合并。
reduceByKey 函数同样返回一个(Key,Value)格式的数据集。
-
-
行动操作:
行动操作是真正触发计算的地方。从文件中加载数据,完成一次又一次转换操作
-
count() 返回数据集中的元素个数
-
collect() 以数组的形式返回数据集中的所有元素
-
first() 返回数据集中的第一个元素
-
take(n) 以数组的形式返回数据集中的前n个元素
-
reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
-
foreach(func) 将数据集中的每个元素传递到函数func中运行。
-
-
Spark相关API文档
http://spark.apache.org/docs/latest/rdd-programming-guide.html
https://www.jianshu.com/p/4f074889bbd9
https://lixh1986.iteye.com/blog/2345420
以上是关于Spark RDD数据过滤的主要内容,如果未能解决你的问题,请参考以下文章