知识图谱:方法、实践与应用笔记-第2章 知识图谱表示与建模
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱:方法、实践与应用笔记-第2章 知识图谱表示与建模相关的知识,希望对你有一定的参考价值。
参考技术A 描述逻辑(description logic)是一簇知识表示的语言,其以结构化、形式化的方法来表示特定应用领域的知识.作为一类用于知识表示的形式化工具,描述逻辑在信息系统、软件工程以及自然语言处理等领域得到了广泛的应用[1].特别是在第三代Web——语义网(semantic Web)中,描述逻辑更是扮演着关键角色,并成为W3C推荐Web本体语言OWL的逻辑基础 。现代知识图谱通常是以三元组为基础进行简单的知识表示,弱化了对强逻辑表示的要求。
基于向量的知识表示在现代知识图谱中越来越收到重视,因为基于向量的知识图谱表示可以使这些数据更易于和深度学习模型集成。
基于向量的知识表示: 知识表示学习的定义知识表示学习是将知识库中的知识表示为低维稠密的实体向量,即Embedding。知识图谱是由实体和关系组成,通常采用三元组的形式表示,【head(头实体),relation(实体的关系),tail(尾实体)】,简写为(h,r,t)。知识表示学习任务就是学习h,r,t的分布式表示(也被叫做知识图谱的嵌入表示(embedding))。
一阶谓词逻辑 :用变量和谓词来表示知识。
霍恩子句 :带有最多一个肯定文字的子句。有且只有一个肯定文字的霍恩子句叫做 明确子句 ,没有任何肯定文字的霍恩子句叫做 目标子句
霍恩逻辑
语义网络 :三元组(节点1,联想弧,节点2)
框架 :基本单元为类(槽,侧面)。基本单元表示一类事物吗?
描述逻辑 :一阶逻辑的一个可判定子集,即每个描述逻辑中的命题都可以在有限时间内完成证明或证否,只有极少数的描述逻辑类型被认为是不可判定的。利用一阶逻辑对语义网络和框架进行形式化后的产物?描述逻辑方法多数被用到涉及知识分类的应用领域,如数字图书馆和面向万维网的信息处理。描述逻辑是当前 语义网 发展中 本体 的理论基础。例如, OWL 因特网 本体 语言就是一种描述逻辑 SHIOQ (D) 的语法形式。
一个描述逻辑系统中的名字可分为概念(concept),属性(role)和个体(individual)。例如,一个用描述逻辑描述的知识库如下:
男人 人 (男人 是 人)
丈夫 男人 婚配于人 (丈夫是 婚配于 至少一个 人 的 男人)
男人(张三) (张三是一个男人)
其中,“男人”、“人”、“丈夫”是概念,“婚配于”是属性,“张三”是个体
描述逻辑和一阶谓词逻辑的区别?
RDF/RDFS :DBpedia,Yago,Freebase
统一资源标识符 (英语: U niform R esource I dentifier,缩写: URI )在 电脑 术语中是一个用于 标识 某一 互联网 资源 名称的 字符串 。
该种标识允许用户对网络中(一般指 万维网 )的资源通过特定的 协议 进行交互操作。URI的最常见的形式是 统一资源定位符 (URL),经常指定为非正式的网址。更罕见的用法是 统一资源名称 (URN),其目的是通过提供一种途径。用于在特定的 名字空间 资源的标识,以补充网址。
OWL/OWL2 : 我认为就是在RDF的基础上再加一些约束。
OWL2QL为查询设计的;OWL2EL提供多项式推理,专为概念属于描述,本体的分类推理而设计,广泛应用于生物医疗领域,如临床医疗术语本体SNOMED CT;OWL2ET的分类复杂度是Ptime,用于推理(后两个区别?)
查询语言SPARQL
语义Markup表示语言 : 在网页中嵌入语义Markup的方法和表示语言。主要包括JSON-LD、RDFa和html5 MicroData。
Freebase:对象-object、事实-Facts、类型-Types和属性-Properties.
Wikidata:页面-Page、实体-Entities、条目-Items、属性-Properties、陈述-Statements、修饰-Qualifiers、引用-Reference等。
ConceptNet5:概念-Concepts、词-Words、短语-Phrases、断言-Assertions、关系-Relations、边-Edges。包含21种预定义的、多语言通用的关系。
词的向量表示方法:独热编码、词袋模型、词向量
词向量的产生方法中经典的额开源工具word2vec中包含两个模型cBoW和Skip-gram。
cBoW和Skip-gram都是用来训练word embeding的。
cBow和Bow的区别:Bow用于一段文本,是一种思想;cBow是把Bow的思想通过滑动窗口用于此向量的实现。
TransE是一个算法,用于graph enbeding.
word enbeding是将文本变成向量;graph emdeding是将实体和关系变成向量。
思考如何从word embeding变成graph embeding?
代表性知识图谱介绍:
1. SNOMED CT
SNOMED CT ( S ystematized No menclature of Med icine -- C linical T erms, 医学系统命名法-临床术语 , 医学术语系统命名法-临床术语 ),是一部经过系统组织编排的,便于 计算机 处理的 医学 术语集 ,涵盖大多数方面的 临床信息 ,如 疾病 、所见、操作、 微生物 、 药物 等。采用该术语集,可以协调一致地在不同的 学科 、 专业 和照护地点之间实现对于临床数据的标引、存储、检索和聚合。同时,它还有助于组织 病历 内容,减少临床照护和科学研究工作中数据采集、编码及使用方式的变异。(From wiki)
SNOMED CT目前包括大约321 900条概念(Concept)、超过80万条临床概念相关的描述(Descriptions),和超过700万条进一步描述概念的关系(Relationships)。
SNOMED CT的主要内容包括概念表、描述表、关系表、历史表、ICD映射表和LONIC映射表。其中核心构成是: 概念表(按层级结构组织的具有临床含义的概念表)、描述表(用于表达概念的人类自然语言表)和关系表(用来说明的两个临床概念之间的关系) 。
软件工程应用与实践——知识图谱树形结构获取
2021SC@SDUSC
一、知识图谱的结构
老年健康知识图谱系统的知识结构是一棵4层的树,每个叶子节点对应一个知识。
以老年综合征为例,具体的图形如下(该图仅包含部分细节)

该系统实现的功能是,获取整棵树的所有节点,并返回到前端,用户点击对应的节点后,查看该知识的详细信息(包含视频,图片,文字,音频)
二、前端代码
2.1 对axios请求的封装
设置baseURL及超时时间
通过设置baseURL,可以简化每次发请求时输入的路径,只需要写后面的路径,前面的路径直接省略,避免请求路径重复的问题。设置超时时间为5秒,若网速过慢发送不成功则会报错
import axios from "axios";
//创建默认实例
const instance = axios.create({
baseURL:"http://localhost:8989",
timeout:5000
})
//暴露instance实例
export default instance
设置请求拦截器,响应拦截器,并添加加载效果
当前端向后端请求数据,数据尚未返回时,由于被请求拦截器拦截,会出现加载效果,当返回数据时,经过响应拦截器,终止加载效果。加载效果的具体动画使用element ui自带的loading组件实现
let loadingInstance = null;
//请求拦截器
instance.interceptors.request.use(config=>{
//展示loading效果
loadingInstance = Loading.service({fullscreen:true,background:'rgba(0,0,0,0.6)',text:'拼命加载中'});
return config;
})
//响应拦截器
instance.interceptors.response.use(response=>{
//隐藏loading效果
loadingInstance.close()
return response;
})
设置导航守卫
当用户未登录时,部分页面无法访问,若用户直接访问链接,则需跳转到登录界面,不能直接进入受到保护的界面,本项目使用vue的beforeEach方法实现导航守卫
子路由中配置页面的权限,使用meta中的requireAuth进行配置,如果为true,则说明需要登录权限才可访问
{
path: '/personInfo',
name: 'PersonInfo',
component: PersonInfo,
meta:{
requireAuth:true,
title:'个人信息'
}
},
设置路由拦截方法
所有请求都会经过这个方法,如果需要权限且用户未登录,则跳转至登录界面,如果有权限,则使用next方法放行该请求
//路由拦截
router.beforeEach((to,from,next)=>{
//设置标题
if (to.meta.title) {
document.title = to.meta.title
}
// 判断该路由是否需要登录权限
if (to.meta.requireAuth) {
// 通过sessionStorage检验当前的token是否存在
if (sessionStorage.getItem("token") == 'login') {
next();
}
else {
next({
path: '/login',
// 将跳转的路由path作为参数,登录成功后跳转到该路由
query: {redirect: to.fullPath}
})
}
}
else {
next();
}
})
2.2 树形控件代码及其分析
前端使用element ui的树形控件,展示知识图谱
树形控件及其方法
使用element ui的el-tree标签,该系统定义了 @node-click="getCheckedNodes"方法,实现点击“叶子”后,向后端发送请求,后端返回具体的数据,并呈现在表格中
<el-tree
class="filter-tree"
:data="treeData"
:props="defaultProps"
default-expand-all
:filter-node-method="filterNode"
@node-click="getCheckedNodes"
ref="tree">
</el-tree>
对应的数据和方法
treeData用于保存后端返回的树形数据
data(){
return{
//树形控件数据
filterText: '',
treeData: [{
label: '一级',
children: [{
label: '二级 1-1',
children: [{
label: '三级 1-1-1'
}, {
label: '三级 1-1-2'
}]
}]
}],
defaultProps: {
children: 'children',
label: 'label'
},
//表格数据
tableData: []
}
},
getCheckedNodes(data,node,element)方法在用户点击具体的叶子时触发,根据node.level获取当前知识所在的层数,由于第三层和第四层都有相应的数据(有部分第三层的节点没有第四层)。同时,第三层的节点有属于自己的数据,与第四层的数据不同,因此需要分别获取。
<script>
methods:{
//获取当前选中的节点并呈现数据
getCheckedNodes(data,node,element){
//如果是第3层节点
if(node.level == 3){
//获取知识名称
let knowledgeName = data.label;
//向后端发送axios请求,获取数据
instance.get("knowledge/third/" + knowledgeName).then(res=>{
this.tableData = res.data;
})
}
//如果是第4层节点
else if(node.level == 4){
//获取知识名称
let knowledgeName = data.label;
//向后端发送axios请求,获取数据
instance.get("knowledge/fourth/" + knowledgeName).then(res=>{
this.tableData = res.data;
})
}
}
}
}
</script>
vue的created方法执行时,data数据已经初始化完成,此时从后端获取树形知识图谱的数据(即整棵树)
created() {
//从后端获取对应的数据
instance.get("treeDate/nodes").then(res=>{
this.treeData = res.data
})
}
三、后端代码
后端代码分为controller层,service层,dao层
controller层负责定义与前端交互的接口,service层负责定义执行具体的事务,dao层负责操作数据库
controller层调用service层,service层调用dao层代码
3.1 树形结构对应的实体类
为了返回对应的树形结构到前端,后端需要定义对应的实体类存储对应的树形结构,在定义实体类的时候,本项目使用lombok注解,避免了大量的set,get方法重复书写。
叶子节点使用List结构存储
package com.sdu.nurse.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.util.List;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Accessors(chain = true)
public class TreeData
{
//节点名
private String label;
//节点对应的子节点
private List<TreeData> children;
}
3.2 填充知识树的过程
在本项目中,知识树共有四层,本项目使用了逐层获取,逐层填充的方式从数据库中获取对应的数据,并填充知识树
dao层接口
本项目使用mybatis-plus,继承BaseMapper,可以对单表查询进行快速操作
package com.sdu.nurse.dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.sdu.nurse.entity.TreeData;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import java.util.List;
@Mapper
public interface TreeDataDao extends BaseMapper<TreeData>
{
//获取所有一级名称
List<TreeData> getAllFirstNodes();
//根据一级名称获取所有二级名称
List<TreeData> getAllSecondNodes(@Param("firstNodeName") String firstNodeName);
//根据二级名称获取所有三级名称
List<TreeData> getAllThirdNodes(@Param("secondNodeName") String secondNodeName);
//根据三级名称获取所有四级名称
List<TreeData> getALlFourthNodes(@Param("thirdNodeName") String thirdNodeName);
}
service层代码
使用@Autowired注解,利用spring工厂自动注入的特性将TreeDataDao注入,不需要程序员手动注入。在service层中通过getAllTreeNodes方法逐层获取叶子节点的数据,最终将List<TreeData>填充完成,返回给controller层
package com.sdu.nurse.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.sdu.nurse.dao.TreeDataDao;
import com.sdu.nurse.entity.TreeData;
import com.sdu.nurse.service.TreeDataService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class TreeDateServiceImpl implements TreeDataService
{
@Autowired
private TreeDataDao treeDataDao;
@Override
public List<TreeData> getAllTreeNodes() {
//获取一级节点
List<TreeData> healthTreeNodes = getFirstNodes();
//获取二级节点
healthTreeNodes.forEach(healthTreeNode->{
healthTreeNode.setChildren(getSecondNodes(healthTreeNode.getLabel()));
});
//获取三级节点
healthTreeNodes.forEach(healthTreeNode->{
healthTreeNode.getChildren().forEach(second->{
second.setChildren(getThirdNodes(second.getLabel()));
});
});
//获取四级节点
healthTreeNodes.forEach(healthTreeNode->{
healthTreeNode.getChildren().forEach(second->{
second.getChildren().forEach(third->{
third.setChildren(getFourthNodes(third.getLabel()));
});
});
});
return healthTreeNodes;
}
@Override
public List<TreeData> getFirstNodes() {
return treeDataDao.getAllFirstNodes();
}
@Override
public List<TreeData> getSecondNodes(String firstNodeName) {
return treeDataDao.getAllSecondNodes(firstNodeName);
}
@Override
public List<TreeData> getThirdNodes(String secondNodeName) {
return treeDataDao.getAllThirdNodes(secondNodeName);
}
@Override
public List<TreeData> getFourthNodes(String thirdNodeName) {
return treeDataDao.getALlFourthNodes(thirdNodeName);
}
}
controller层代码
@CrossOrigin注解解决前后端通过AJAX传输数据时跨域的问题,@RestController注解表明这是一个符合restful规范的,前后端交互的接口。@GetMapper注解表明使用get请求获取数据
package com.sdu.nurse.controller;
import com.sdu.nurse.entity.TreeData;
import com.sdu.nurse.service.TreeDataService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@CrossOrigin
@RestController
@RequestMapping("treeDate")
public class TreeDataController
{
@Autowired
private TreeDataService treeDataService;
@GetMapping("nodes")
public List<TreeData> getAllTreeNodes(){
return treeDataService.getAllTreeNodes();
}
}
3.3 知识树的JSON表示
使用postman工具对后端接口进行测试,返回的知识树的部分结构如下
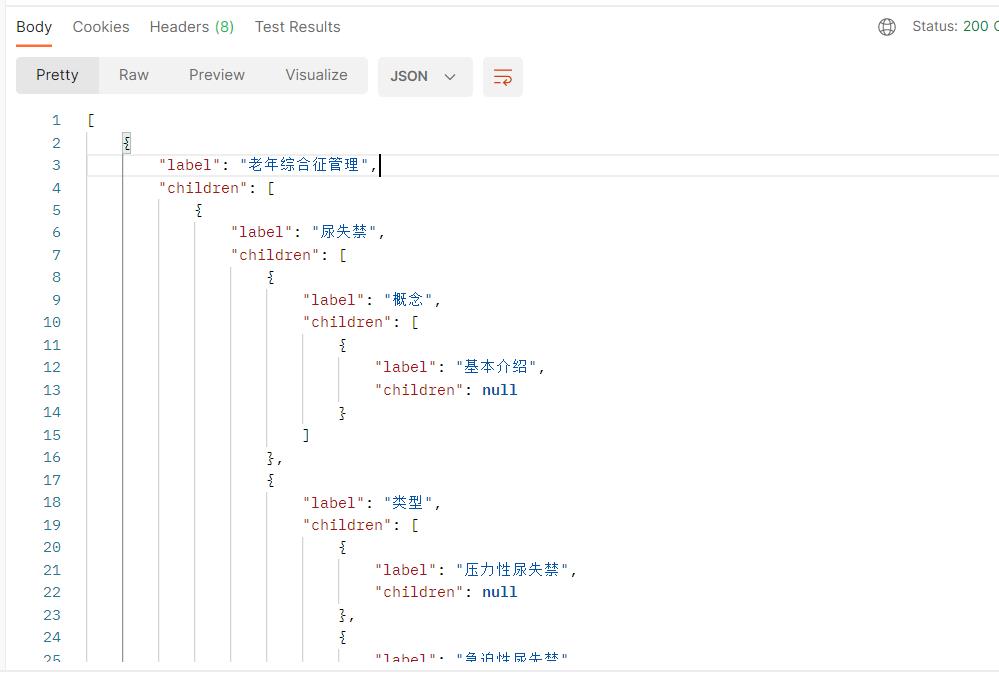
将此JSON返回到前端,结合element ui的树形控件,即可实现树形数据的呈现与选择
四、总结
由于本项目的主要功能之一就是方便老年人查看关于老年疾病的各种类型和详细信息,因此获取知识图谱的树状数据是该系统很重要的一项功能,经过小组讨论与分工,最终决定由我完成树形结构获取及树形数据具体展示的源代码分析。本项目关于知识图谱的内容还是比较清晰的,除了本篇博客以外,之后还会有一篇补充博客对获取具体叶子节点对应的具体知识数据进行分析。
以上是关于知识图谱:方法、实践与应用笔记-第2章 知识图谱表示与建模的主要内容,如果未能解决你的问题,请参考以下文章