利用MCMM技术解决时序难以收敛的问题以及降低了芯片设计周期设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用MCMM技术解决时序难以收敛的问题以及降低了芯片设计周期设计相关的知识,希望对你有一定的参考价值。
参考技术A 描述如今的集成电路(Integrated Circuit,IC)设计往往要求芯片包含多个工作模式,并且在不同工艺角(corner)下能正常工作。工艺角和工作模式的增加,无疑使时序收敛面临极大挑战。本文介绍了一种在多工艺角多工作模式下快速实现时序收敛的技术---MCMM(Multicorner-Multimode)技术,该技术将工艺角和模式进行组合,对时序同时进行分析和优化,到达快速实现时序收敛的目的。该技术应用于一个80万门基于TSMC 0.152μm logic 工艺的电力网载波通信(PLC)芯片设计,设计实例表明,利用MCMM 技术不但可以解决时序难以收敛的问题,而且大大降低了芯片设计周期。
1 引言
随着集成电路工艺的不断发展,芯片受工艺、电压、温度(Process、Voltage、Temperature,PVT)的影响越来越严重,需要使用更多的工艺角来保证芯片在不同条件下能稳定工作;与此同时,随着芯片测试需求的增加和功能的增强,芯片的工作模式也在不断增加,这给芯片版图设计者带来了一系列的困难,其中最困难的当然是如何快速实现时序收敛,缩短设计周期。设计者必须保证芯片在相同工作模式不同工艺角下的时序收敛,当工艺角和工作模式数量多的时候,使用传统的方法来实现时序收敛绝非一件易事,需要大量的人工工作进行大量反复迭代,分析并消除模式之间的影响,有时甚至会出现时序难以收敛的情况。我们实验室设计的PLC 芯片,正是采用了Synopsis 公司IC Compiler 软件的MCMM 设计技术,完全放弃了传统的时序收敛方法,有效加速了实现时序收敛,缩短了设计周期。
2 传统的时序收敛实现方法
在传统的时序收敛和分析方法下,版图设计工程师需要在不同的工作模式之间来回切换设计约束进行分析优化,以满足同一时序路径在不同模式下的时序要求,如图1所示。
从图1中可以看出,这种方法的缺点是版图工具无法同时覆盖到所有模式下的时序,必须以串行的方法来修复各个模式的时序,还必须保证修复过程中模式之间没有影响,这无疑增加了各个模式之间的切换迭代次数和人工手动ECO 的时间。如果芯片的工艺角和模式越多,切换迭代次数就越多,工作量会大到让设计者难以接受的地步。
3 基于MCMM 技术
快速时序收敛实现方法MCMM 技术实现时序收敛的基本思想是,工艺角和模式组成场景(scenario),版图设计软件IC Compiler"吃进"所有scenario 的时序约束,激活关键的scenario,让软件自行评估和优化。同一条违例时序路径可能出现在不同的scenario中,评估这条违例路径在不同scenario中的时序裕量大小,例如一条路径在scenario1 中的裕量为-1,在scenario2中的裕量为-0.2,则认为其在scenario1中的权重更高,在权重最高的scenario1 中进行修复。具体流程如图2所示。
很明显,与传统方法相比,MCMM 技术将时序收敛的处理变以往的"串行"为"并行",并且模式之间的影响完全交给版图软件来分析,省去了人工手动ECO的工作,从而大大减少了时序收敛的迭代次数和设计时间。
4 应用举例
以实验室一款PLC芯片为例,具体介绍如何使用MCMM技术来加速时序收敛。
4.1 scenario 的定义
该芯片有2 种正常工作模式,时钟频率分别是90Mhz和60Mhz,3种DFT 测试模式,分别是shift模式,capture 模式和mbist 模式,需要工作在两个工艺角下,WCCOM 和BCCOM,也就是5种模式2个工艺角组成了10 个scenario,每个scenario 指定对应的寄生模型(TLU+ 文件),worst 和best,如表1所示。在WCCOM工艺角下检查建立时间(setup time),在BCCOM 工艺角下检查保持时间(hold time)。
4.2 基于MCMM 的时序收敛实现
在同时激活10 个scenario 的情况下,会出现服务器内存溢出,死机等状况,导致设计无法顺利进行。我们对这10 个scenario 进行了分析,其中MBIST_MAX,SHIFT_MAX,CAPTURE_MAX,MISSION 60_MAX 这4 个scenario 中,时钟频率最大的是MISSION60_MAX 中的60MHz,其余三个scenario 时钟频率只有10MHz,建立时间裕量都在9.9ns 以上,即使在修复过程中不激活,修复其它scenario 时带来的影响在承受范围之内,也不会对后续的绕线产生影响;在MISSION90_MAX 这个scenario中,时钟频率是90MHz,建立时间虽然没有违例,但是留下的裕量只有0.84ns,不足以抵挡修复其它scenario时带来的影响;剩下的5 个scenario 中,都有保持时间违例,必须进行修复。基于以上分析,我们选择同时激活MISSION90_MAX, MISSION_MIN, MISSION 60_MIN, MBIST_MIN, SHIFT_MIN, CAPTURE_MIN这6个关键scenario 进行时序收敛,具体脚本如下:
set_active_scenarios MISSION90_MAX MISSION90_MIN MISSION60_MIN MBIST_MIN SHIFT_MIN CAPTURE_MIN(激活关键scenario)foreach scenario [all_active_scenarios] current_scenario scenario set_clock_uncertainty -hold 0.2 [all_clocks]set_clock_uncertainty -setup 0.6 [all_clocks] set_prefer -mintcb0152gbwp7twc/DEL015BWP7Ttcb0152gbwp7twc/DEL02BWP7Tset_fix_hold_options -preferred_buffer set_fix_hold [all_clocks](设定每个关键scenario 的时序裕量,用指定的std cell 来修复hold timing)update_clock_latency(更新clock 延迟)psynopt(进行时序修复)
4.3 结果分析
经以上操作,6个scenario 的时序路径同时经过优化之后,结果如表2 所示。
表2中结果表明,几乎所有模式都已经满足了时序要求, 只有MISSION90_MAX 的scenario有setup 时序的违例,为了修复该违例,只需激活该scenario,重新一次“psynopt”就可以到达时序要求。
我们也尝试用传统方法来修复该芯片的时序,由于模式数量多,导致模式间来回切换次数多于20次,加上模式之间时序干扰严重,人工参与分析工作量很大,时序收敛所需要的时间远远多于用MCMM技术所花的时间,MCMM 技术优势非常明显,具体结果如表3所示。
5 结语和展望
本文介绍了IC Compiler 的MCMM 同步优化技术,用一个设计实例阐述该技术的具体实现过程,结果显示大大节省了设计时间,也为版图设计工程师解决了人工分析干预的难题,具有一定的实际应用价值。在设计过程中我们从CTS 阶段后才开始采用MCMM 技术来达到芯片时序收敛的目的,在今后更复杂,要求更高的设计中,把MCMM 技术应用到一些关键步骤中,比如逻辑综合和place 等,并且综合考虑芯片功耗问题。
定义scenario 的具体脚本如下:
create_scenario MISSION90_MAX (建立一个名叫MISSION90_MAXX 的scenario)set_operating_conditions \
-analysis_typeon_chip_variation \-max_library tcb0152gbwp7twc \-max WCCOM(指定时序分析类型和对应corner下的lib 库)set_tlu_plus_files \-max_tluplus ./test/cl0152g_lp6m_worst.tlup \-tech2itf_map ./techfiles/tluplus/star.map_6M(设定相应corner 的RC 寄生模型)source . /netlist /KOALA_ASIC_TOP_compiled_pass3_mission_90_mode_post.sdc(读入该模式的时序约束文件)。
原文链接:http://qikan.cqvip.com/Qikan/Article/Detail?id=49362964
解读顶会ICDE’21论文:利用DAEMON算法解决多维时序异常检测问题
摘要:该论文针对多维时序数据的异常检测问题,提出了基于GAN和AutoEncoder的深度神经网络算法,并取得了当前State of the Art (SOTA)的检测效果。论文是云数据库创新LAB在轨迹分析层面取得的关键技术成果之一。
本文分享自华为云社区《ICDE'21 DAEMON论文解读》,作者:云数据库创新Lab。
导读
本文( DAEMON: Unsupervised Anomaly Detection and Interpretation for Multivariate Time Series)是由华为云数据库创新Lab联合电子科技大学数据与智能实验室发表在顶会ICDE’21的文章。该文章针对多维时序数据的异常检测问题,提出了基于GAN和AutoEncoder的深度神经网络算法,并取得了当前State of the Art (SOTA)的检测效果。ICDE是CCF推荐的A类国际学术会议,是数据库和数据挖掘领域顶级学术会议之一。该论文是华为云数据库创新LAB在轨迹分析层面取得的关键技术成果之一。
1. 摘要
随着IoT时代的到来,越来越多的传感器采集的时序数据被存储在数据库中,而怎么样处理这些海量数据以挖掘其中的价值是近些年来学术界和工业界热门的研究点。本文研究了多指标时序数据的异常检测问题,以诊断产生时序数据的实体可能存在的异常。
本文的主要贡献如下:
- 提出了DAEMON算法,其算法基于自编码器和GAN结构,自编码器用于重构输入时序数据,GAN结构分别用于约束自编码器的中间输出以及自编码器的重构输出以使自编码器结构的训练过程更加鲁棒并且减少过拟合。
- 本文提出了利用多维异常检测的重构结果进行根因定位的方式
- DAEMON算法能够在测试数据集上击败现有算法
2. 背景

3. 算法设计
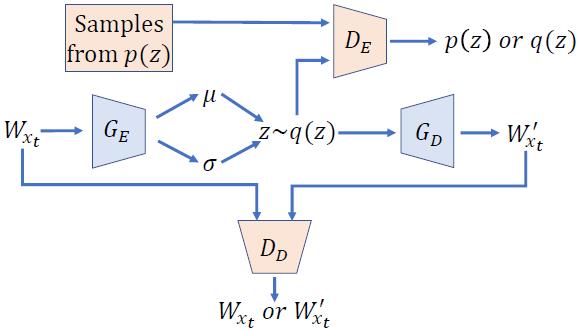
图.1 DAEMON的网络结构
A. 算法结构简介
DAEMON算法的总体网络结构如图.1所示,包含了三个网络模块,变分自编码器G_AGA(其中包含编码器G_EGE和解码器G_DGD,编码器和解码器同时作为两个GAN结构中的生成器), 对应编码器的GAN结构判别器D_EDE以及对应解码器的GAN结构判别器D_DDD。
下面简述一下各个网络结构的具体功能

B. 数据预处理
- 数据清洗:利用spectral residual算法首先清理掉训练数据集中可能存在的异常点,这样一来,VAE将会更准确的学习到时间序列的正常分布。
- 数据归一化:本文利用MINMAX归一化方式对训练以及测试数据进行归一化。
C. 线下训练过程
DAEMON的网络包含三个模块,一个变分自编码器,两个GAN结构的判别器。由于GAN结构网络需要异步训练,因此,DAEMON结构对应了三个异步的训练过程,每个训练规程都对应了各自的优化器以及损失函数。
下面分别介绍各个模块:
GAN结构1:GAN结构1中,生成器对应的是变分自编码器的编码器部分G_EGE,而判别器对应的是D_EDE,此GAN结构的目的是约束生成器的分布q(z)q(z) 。由GAN的标准损失函数公式可以推导出生成器和判别器的损失函数分别为
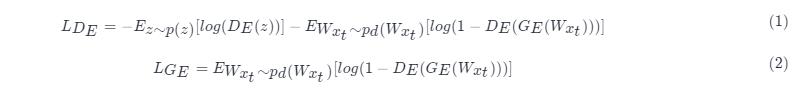
GAN结构2:GAN结构2中,生成器对应的是变分自编码器中的解码器部分G_DGD,判别器对应的是D_DDD,此GAN结构的目的是进一步约束自编码器的输出以让自编码器更好的学习时序数据的正常分布。和上面相似,生成器和判别器的损失函数为

变分自编码器模块:变分自编码器用于数据的重构,其自身的损失函数用输入和输出的一范数距离定义
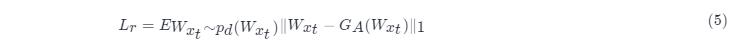
注意。GAN结构1,2中的判别器损失函数都只涉及到判别器本身,在训练的时候,可以直接用(1),(3)进行训练,而生成器的损失函数和变分自编码器的损失函数同时涉及到一个公共的模块,即变分自编码器本身,因此,在训练自编码器网络时,实际上要同时训练三个损失函数,具体的方法为,令三个损失函数的加权和为变分自编码器的损失函数,即
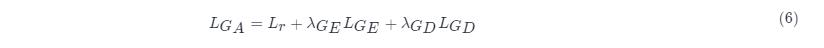
在线下训练时,依次针对公式(1),(3),(6)进行训练。
D. 在线检测过程
在线数据W_{x_t}Wxt输入到检测器后,得到重构W'_{x_t}Wxt′,之后把被检测点x_txt和被检测点的重构x'_txt′做比较以求取异常得分,即
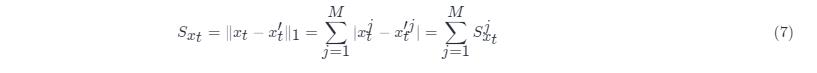
E. 根因分析
从公式(7)中可以看出,异常得分实际上是由每一个维度的误差所加和得出的,因此,在根因定位的时候,直接从S_{x_t}^jSxtj中找出最大的kk个得分对应的指标既可视为根因可能出现的位置。
4. 实验
4.1 环境设定
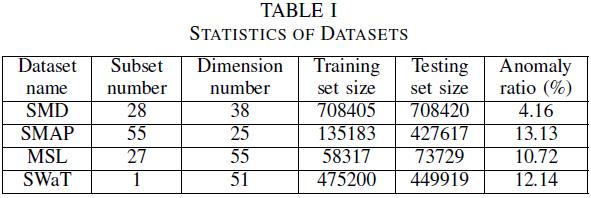
在仿真中,作者对比了四个常用且公开的时序异常检测数据集,即SMD, SMAP, MSL, SWaT数据集。下面是各个数据集的具体指标。
作者在仿真中对比的指标为precision, recall以及F1-score。
在对比算法方面,作者对比了8种现有的算法,其中VAE算法是DAEMON去掉GAN结构后的结构,目的是为了测试GAN约束的有效性。为了体现本文GAN结构的有效性以及创新型,作者还对比了另外两种利用GAN结构的异常检测算法GANomaly以及BeatGAN。其次,OmniAnomaly是业界著名AIOps团队,北大的裴丹教授团队发表在KDD上的异常检测算法。
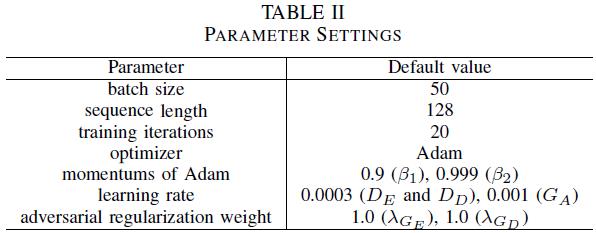
下表是作者公布的参数设置
4.2 检测结果
仿真对比结果如下表所示
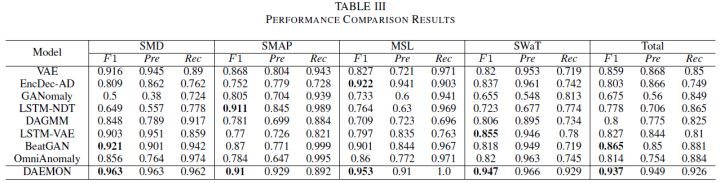
可以看到,在四个公开数据集上,DAEMON都能达到SOTA的效果。
4.3 时间消耗
同时,从训练时间和检测时间来看,DAEMON算法也能在现有算法中达到中上的水平
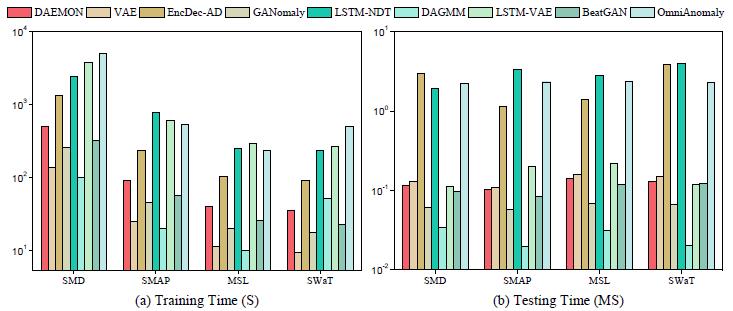
图.2 训练检测时间对比
4.4 根因定位
最后,作者对比了根因定位的准确性,DAEMON也能在对比算法中达到SOTA的性能
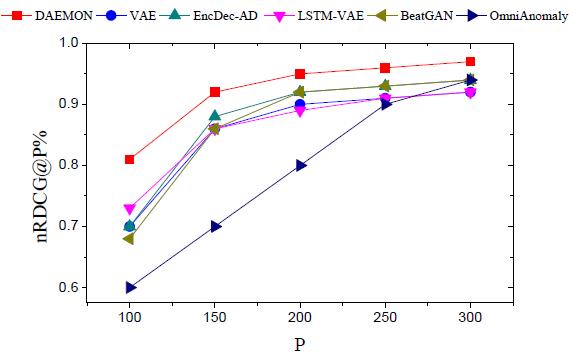
图.3 根因定位准确性对比
5. 应用
本算法已经被集成在华为云时序存储与分析组件GaussDB for Influx中,用于监控指标的异常检测与根因定位。

图.4 DAEMON应用场景
6. 总结
在论文中,作者针对多维时序异常检测问题提出了基于变分自编码器以及GAN的DAEMON算法,经过测试,DAEMON算法可以在公开数据集上达到SOTA的性能,并且也能达到SOTA的根因定位能力。其次,DAEMON的训练,检测时间效率也能在现有算法中达到中上水平。
华为云数据库创新lab官网:https://www.huaweicloud.com/lab/clouddb/home.html
以上是关于利用MCMM技术解决时序难以收敛的问题以及降低了芯片设计周期设计的主要内容,如果未能解决你的问题,请参考以下文章