目标检测系列 Mask R-CNN—FPN
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测系列 Mask R-CNN—FPN相关的知识,希望对你有一定的参考价值。
参考技术AFaster R-CNN 使用标准的 Resnet 网络结构作为基础网络,来提取特征,提取大小不同的特征图来用来解决图像识别中目标的尺度问题,也就是相当在一系列尺寸不同(从小到大尺寸不同)的图片上进行特征提取来图像识别。
随着隐含层递增,隐含输出的特征图的大小减小一半,特征响应图通道数(深度)增加一倍。如图所示,我们从 resnet-50 架构的 4 个特征响应图中提取了特征(第1层,第2层,第3层,第4层输出)。
在 FPN 网络中最终输出的特征图,使用一种称为从 上至下路径 (top-bottom path)的方法。从最小的特征图通过上采样得到更大尺寸的通道数为 256 的特征响应图。然后逐个元素地将其添加到上一次迭代的上采样输出中。这样好处是不会丢失信息,不同大小尺寸特征图都会融合之后,保留各个层的特征响应图的信息。
此过程的所有输出都经过 卷积层以创建最终的 4 个特征图(P2,P3,P4,P5。第五个特征图(P6) 是通过对 P5 进行 max pooling 而生成的特征图。注意,在这里我们一定要对尺寸格外小心,上采样操作涉及的最小尺寸特征图是 (w/32,h / 32)。这里需要确保输入张量(tensor)的尺寸可被 32 整除。
这里通过一个例子来说明,假设图片大小为 w = 800 和 h = 1080。将宽和高同时除以 32 w/32 = 25,h/32 = 33.75,得到的特征图的大小为 (25,33)。接下来在上采样时,特征图尺寸将为 (50,66),应该将其逐元素添加到另一个尺寸为 (50,67) 的特征图中,因为两个 tensor 只有维度保持一致才能进行相加,所以这里因为维度不一致无法相加(合并)而会抛出错误。这是我们在使用 FPN 时,输入 tensor 应为 32 的倍数的原因。
目标检测论文解读11——Mask R-CNN
目的
让Faster R-CNN能做实例分割的任务。
方法
模型的结构图如下。
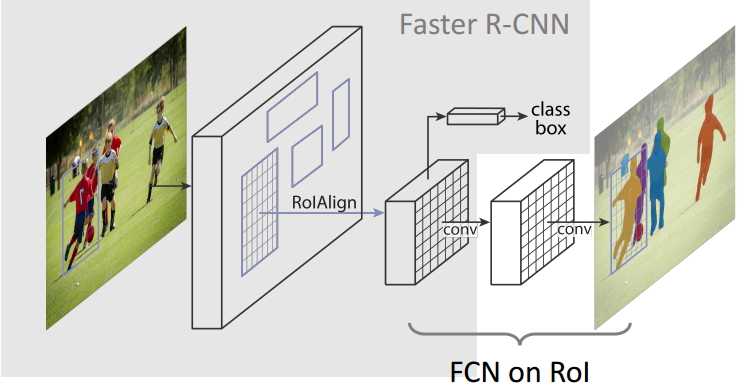
与Faster R-CNN相比,主要有两点变化。
(1) 用RoI Align替代RoI Pool。
首先回顾一下RoI Pool,流程为:将RPN产生的原图侯选框映射到CNNs输出的feature map上,显然原图比feature map大,所以映射后的像素坐标可能会有小数,这里的做法是用近邻插值法,通俗讲,坐标四舍五入。
而这种做法肯定会带来一些空间位置上的小误差,而我们后面的实例分割是逐像素的,接受不了这种误差,因此采用RoI Align,用双线性插值法替代近邻插值法(具体可以参考博客:https://zhuanlan.zhihu.com/p/49832888)
(2)添加了一个基于FCN的Mask分支,用来对feature map上的RoI进行实例分割。
经过RoI Align得到的feature map,经过几层卷积,最终得到一个m*m的二值特征图,object与background,逐像素分类即可。这里之所以采用FCN,是因为我们最终所做的实例分割,需要保留空间信息;如果最后一层接FC的话得到的就是一维向量。
总结
Mask R-CNN的实例分割效果很好,尤其对于那种目标偏小的图片效果也很好,主要是因为他是先通过前面的RoI Align把目标给框出来了,后面实例分割的话是在包含目标的小框中进行的。
以上是关于目标检测系列 Mask R-CNN—FPN的主要内容,如果未能解决你的问题,请参考以下文章