关于在Linux中摘取网页
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于在Linux中摘取网页相关的知识,希望对你有一定的参考价值。
我经常浏览网页,偶尔发现一些很好的网页想要摘录下来(怕过段时间之后失效),有什么比较好的办法呢?
平常使用 Zim 比较多,这货是不支持复制粘贴的……
特别要注意的是,这是在Linux下,不要给我推荐 window的软件。最好是开源的。
看清楚这个补充才回答,随便粘贴只会浪费大家时间。
这个貌似不错。等我再看看有没有更好的办法
参考技术A 你说的摘录是保存源文件呢还是截图啊。追问保存文字信息,最好排版都一样。但是不希望真的保存为 html 文件,因为很难编辑。而且很零散
追答用浏览器的保存网页,保存全部是最好的。也可以使用下载全站的软件。html格式的文件很容易编辑的呀。
追问汗……编辑的时候得人肉解析他的格式吧……
追答直接在dw里面编辑就可以了呀。你也可以复制到word里面呀。
Python+Selenium练习篇之1-摘取网页上全部邮箱
前面已经介绍了Python+Selenium基础篇,通过前面几篇文章的介绍和练习,Selenium+Python的webUI自动化测试算是入门了。接下来,我计划写第二个系列:练习篇,通过一些练习,了解和掌握一些Selenium常用的接口或者方法。
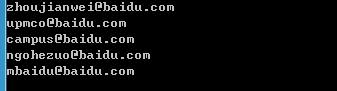
练习场景:在某一个网页上有些字段是我们感兴趣的,我们希望摘取出来,进行其他操作。但是这些字段可能在一个网页的不同地方。例如,我们需要在关于百度页面-联系我们,摘取全部的邮箱。
思路拆分:
1. 首先,需要得到当前页面的source内容,就像,打开一个页面,右键-查看页面源代码。
2. 找出规律,通过正则表达式去摘取匹配的字段,存储到一个字典或者列表。
3. 循环打印字典或列表中内容,Python中用 for 语句实现。
技术角度实现相关方法:
1. 查看页面的源代码,在Selenium中有driver.page_source 这个方法得到
2. Python中利用正则,需要导入re模块
3. for email in emails :
print email
想法技术角度方法都找到,我们新建一个extract_email.py 文件,输入如下代码:
# coding=utf-8
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("http://home.baidu.com/contact.html")
# 得到页面源代码
doc = driver.page_source
emails = re.findall(r\'[\\w]+@[\\w\\.-]+\',doc) # 利用正则,找出 xxx@xxx.xxx 的字段,保存到emails列表
# 循环打印匹配的邮箱
for email in emails:
print (email)
解释:
在python正则表达式语法中,Python中字符串前面加上 r 表示原生字符串,用\\w表示匹配字母数字及下划线。re模块下findall方法返回的是一个匹配子字符串的列表。
运行结果:
以上是关于关于在Linux中摘取网页的主要内容,如果未能解决你的问题,请参考以下文章