CDH 配置 Sentry 服务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH 配置 Sentry 服务相关的知识,希望对你有一定的参考价值。
参考技术AHive -> 配置 -> 搜索 sentry -> 勾选Sentry -> 保存更改 -> 重启服务
HDFS -> 配置 -> 搜索 acl -> 启用访问控制列表和Sentry同步 -> 保存更改 -> 重启服务
Hue中集成了一个安全模块用来界面化操作Sentry。设置Hue以管理Sentry权限时,请确保正确设置了用户和组。连接到Sentry的每个Hue用户必须与服务器操作系统中的用户相同,以便Sentry可以对Hue用户进行身份验证。Hue中的用户group也同样要与本地操作系统中的用户group相同。
Hue -> 配置 -> 搜索 sentry -> 勾选Sentry -> 保存更改
Sentry -> 配置 -> 搜索 admin -> 勾选Sentry -> 保存更改 -> 重启服务
为Hive启用Sentry后会导致HiveServer2的部分属性无法在客户端运行时进行修改。具体受限制的属性参数如下,当然你依旧可以在HiveServer2服务端进行参数修改。
保护Hive Metastore是非常重要的。如果你的集群没有启用Kerberos,请将sentry.hive.testing.mode属性设置为true,以允许Sentry使用较弱的身份验证机制。
注意:
Cloudera强烈建议不要在生产环境中配置该参数。该参数仅适用于Sentry的测试模式,可以用于你的测试环境
Hive-> 配置 -> 搜索 sentry-site.xml-> 添加下面配置 -> 保存更改 -> 重启服务
当HiveServer2和Beeline客户端不在同一台主机时,不能使用ADD JAR命令。作为替代的,在加载jar包时只能通过在Hive服务中配置hive.reloadable.aux.jars.path路径。启用Sentry时,创建永久函数和临时函数的过程存在一些差异。
参考:
https://www.cloudera.com/documentation/enterprise/latest/topics/sg_sentry_service_config.html
为CDH 5.7集群添加Kerberos身份验证及Sentry权限控制
转载请注明出处:http://www.cnblogs.com/xiaodf/
4. 为CDH 5集群添加Kerberos身份验证
4.1 安装sentry
1、点击“操作”,“添加服务”;
2、选择sentry,并“继续”;
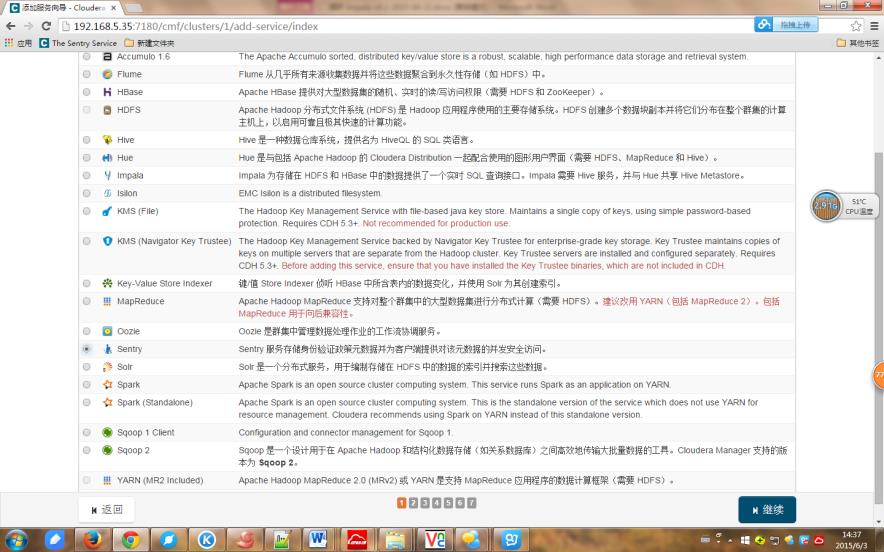
3、选择一组依赖关系
4、确认新服务的主机分配
5、配置存储数据库;
在mysql中创建对应用户和数据库:
mysql>create database sentry default character set utf8 collate utf8_general_ci; mysql>grant all on sentry.* to \'admin\'@\'server35\' identified by \'111111\'; mysql>flush privileges;
6、测试连接

7、创建Sentry数据表,启动Sentry服务
4.2 详细部署过程
4.2.1 安装Cloudera Manager和CDH
如果您尚未执行此操作,Cloudera 强烈建议您首先安装和配置 Cloudera Manager Server 和 Cloudera Manager Agent 以及 CDH 来设置一个功能完备的 CDH 群集,然后再开始执行以下步骤来实施 Hadoop 安全功能。
4.2.2 如果您使用的是 AES-256 加密,请安装 JCE 策略文件(推荐不使用AES-256加密)
如果您使用的是 CentOS 或 RHEL 5.5 或更高版本(默认情况下对票证使用 AES-256 加密),您必须在所有群集和 Hadoop 用户主机上安装 Java Cryptography Extension (JCE) 无限制强度权限策略文件。可通过两种方法执行此操作:
1、 在 Cloudera Manager Admin Console 中,导航到主机页面。向群集添加新主机向导和重新运行升级向导都使您能够选择让 Cloudera Manager 为您安装 JCE 策略文件。
2、 您可以按照 jce_policy-x.zip 文件中包含的 README.txt 文件中的 JCE 策略文件安装说明进行操作。
注意:您可以通过从 kdc.conf 或 krb5.conf 文件的 supported_enctypes 字段中删除 aes256-cts:normal 来将 Kerberos 配置为不使用 AES-256。请注意,在更改 kdc.conf 文件之后,您需要重启 KDC 和 kadmin 服务器,这些更改才会生效。您可能还需要重新创建或更改相关主体的密码,可能包括 Ticket Granting Ticket 主体(例如,krbtgt/EXAMPLE.COM@EXAMPLE.COM)。如果在执行所有这些步骤之后仍在使用 AES- 256,这是因为在创建 Kerberos 数据库时存在 aes256-cts:normal 设置。要解决此问题,请创建新的 Kerberos 数据库,然后重启 KDC 和 kadmin 服务器。
4.2.3 为 Cloudera Manager Server 获取或创建 Kerberos 主体
为了能在集群中创建和部署host principals和keytabs,Cloudera Manager Server必须有一个Kerberos principal来创建其他的账户。如果一个principal的名字的第二部分是admin(例如, username/admin@YOUR-LOCAL-REALM.COM ),那么该principal就拥有administrative privileges。
在KDC server主机上,创建一个名为[cloudra-scm]的principal,并为其设置密码。执行命令:
[root@vmw201 ~]# kadmin.local Authenticating as principal root/admin@HADOOP.COM with password. Kadmin.local: addprinc -pw cloudera-scm-1234 cloudera-scm/admin@HADOOP.COM WARNING: no policy specified for cloudera-scm/admin@HADOOP.COM; defaulting to no policy Principal "cloudera-scm/admin@HADOOP.COM" created.
输入listprincs可以看到创建了一个名为cloudera-scm/admin@HADOOP.COM的principal:

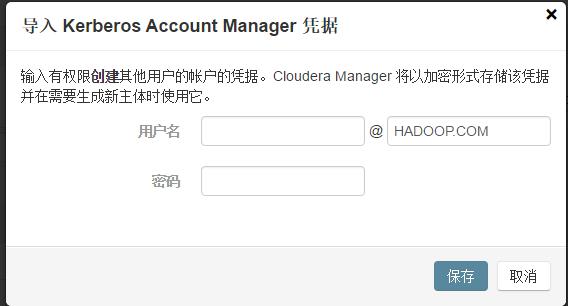
4.2.4 导入KDC Account Manager凭据
1、在 Cloudera Manager Admin Console 中,选择管理 > 安全 > Kerberos凭据。

2、导航到凭据选项卡并单击导入 Kerberos Account Manager 凭据。

3、在导入 Kerberos Account Manager 凭据对话框中,针对可以在 KDC 中为 CDH 群集创建主体的用户输入用户名和密码。这是您在4.1.3中:为 Cloudera Manager Server 获取或创建 Kerberos 主体 中创建的用户/主体。Cloudera Manager 会将用户名和密码加密到 Keytab 中,并在需要时使用它来创建新的主体。
4.2.5 在cloudera Manager Admin Console中配置Kerberos默认领域
1、在 Cloudera Manager Admin Console 中,选择管理 > 设置。
2、单击Kerberos类别,然后在 Kerberos 安全领域字段中为群集输入您在 krb5.conf 文件中配置的 Kerberos 领域(例如 EXAMPLE.COM 或 HADOOP.EXAMPLE.COM)、KDC Server主机、Kerberos加密类型。
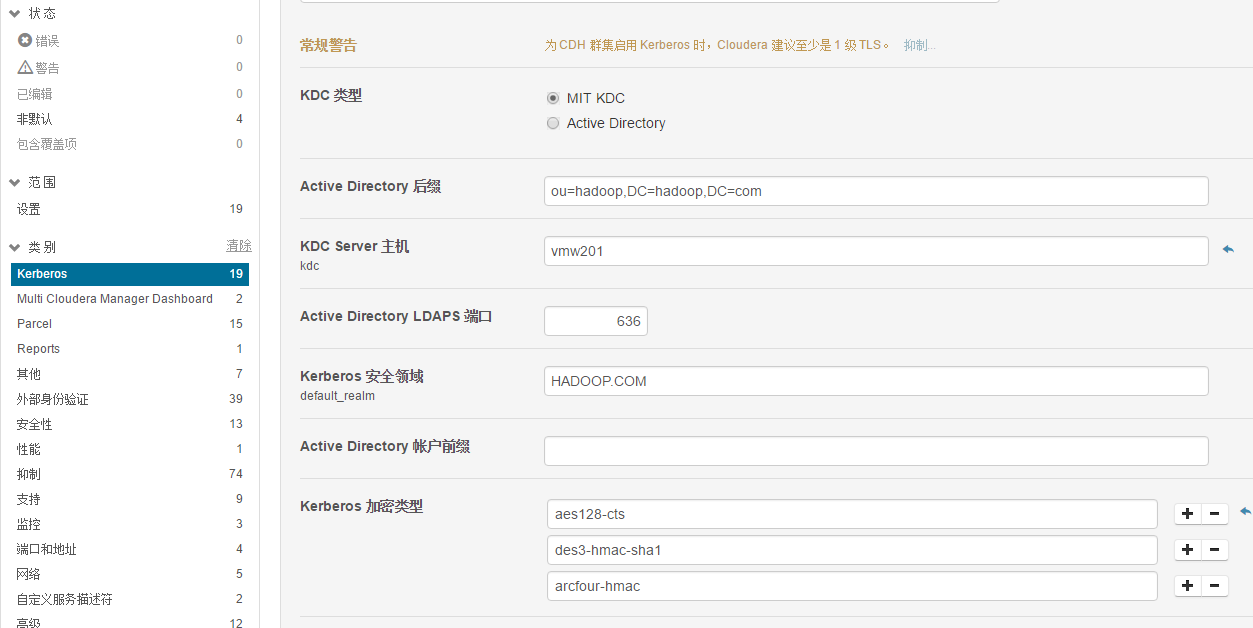
3、 单击保存更改。
4.2.6 停止所有服务
1、在主页上,单机集群名称右侧的  ,停止所有服务。
,停止所有服务。
2、在主页上,单击 Cloudera Management Service 右侧的 ,选择停止。
,选择停止。
4.2.7 启用 HDFS安全性
1、点击主页上的HDFS,选择配置
2、修改下面参数
hadoop.security.authentication ---> kerberos hadoop.security.authorization ---> true dfs.datanode.data.dir.perm ---> 700 dfs.datanode.address --->1004 dfs.datanode.http.address --->1006 Hadoop.security.group.mapping->org.apache.hadoop.security.ShellBasedUnixGroupsMapping
3、单击保存更改
4.2.8 启用HBASE安全性
1、点击主页上的HBASE,选择配置
2、修改下面参数
hbase.security.authentication ---> Kerberos hbase.security.authorization ---> true
3、 单击保存
4.2.9 启用kafka安全性
1、单击主页上的kafka,选择配置。
2、修改下面参数
kerberos.auth.enable ---> true security.inter.broker.protocol ---> SASL_PLAINTEXT
3、单击保存
4.2.10 启用zookeeper安全性
1、单击主页上的zookeeper,选择配置。
2、修改下面参数
enableSecurity ---> true
3、单击保存
4.2.11 Hive开启sentry服务以及开启Hive安全性
1、在“Sentry 服务”中选择“Sentry”
2、修改下面参数
Hive.warehouse.subdir.inherit.perms-->true
3、选择hive-site.xml 的 Hive 服务高级配置代码段(安全阀),增加如下配置:
<property> <name>sentry.hive.testing.mode</name> <value>false</value> </property>
4、选择“范围”中的“HiveServer2”,修改如下配置:
hive.server2.enable.impersonation, hive.server2.enable.doAs-->false
5、选择hive-site.xml 的 HiveServer2 高级配置代码段(安全阀),添加如下配置
<property> <name>hive.security.authorization.task.factory</name> <value>org.apache.sentry.binding.hive.SentryHiveAuthorizationTaskFactoryImpl</value> </property>
6、选择hive-site.xml 的 Hive Metastore Server 高级配置代码段(安全阀),添加如下参数:
<property> <name>hive.metastore.client.impl</name> <value>org.apache.sentry.binding.metastore.SentryHiveMetaStoreClient</value> <description>Sets custom Hive Metastore client which Sentry uses to filter out metadata.</description> </property> <property> <name>hive.metastore.pre.event.listeners</name> <value>org.apache.sentry.binding.metastore.MetastoreAuthzBinding</value> <description>list of comma separated listeners for metastore events.</description> </property> <property> <name>hive.metastore.event.listeners</name> <value>org.apache.sentry.binding.metastore.SentryMetastorePostEventListener</value> <description>list of comma separated listeners for metastore, post events.</description> </property> <property> <name>hive.metastore.filter.hook</name> <value>org.apache.sentry.binding.metastore.SentryMetaStoreFilterHook</value> </property>
4.2.12 配置yarn
在“允许的系统用户”参数“allowed.system.users”中添加hive用户
Yarn->配置->min.user.id修改为合适的值,当前为0
4.2.13 配置sentry
管理员组(sentry.service.admin.group)和允许的连接用户(sentry.service.allow.connect)中添加admin用户和组;
选择“服务范围”,修改管理员组,将默认“hive”、“impala”、“hue”删除,并增加“admin”。
在sentry-site.xml 的 Sentry 服务高级配置代码段(安全阀)中添加如下参数:
<property> <name>sentry.service.processor.factories</name> <value>org.apache.sentry.provider.db.service.thrift.SentryPolicyStoreProcessorFactory,org.apache.sentry.hdfs.SentryHDFSServiceProcessorFactory</value> </property> <property> <name>sentry.policy.store.plugins</name> <value>org.apache.sentry.hdfs.SentryPlugin</value> </property> <property> <name>sentry.hdfs.integration.path.prefixes</name> <value>/user/hive/warehouse</value> </property>
4.2.14 等待“生成凭据”命令完成
在 Cloudera Manager 中为任何服务启用安全保护之后,将自动触发称为“生成凭据”的命令。您可以在显示正在运行的命令的屏幕右上角看到该命令的进度。请等待此命令完成(通过内含“0”的灰色框表示)。
4.2.15 使 Hue 能够使用 Cloudera Manager 与 Hadoop 安全一起工作
如果您使用的是 Hue 服务,那么您必须向 Hue 服务添加 Kerberos Ticket Renewer 的角色实例,以使 Hue 能够使用 Cloudera Manager 与安全的 Hadoop 群集一起正常工作。
Hue Kerberos Ticket Renewer 仅为主体 hue/<hostname>@HADOOP.COM续订 Hue 服务的票证。然后,将使用该 Hue 主体为 Hue 内的应用程序(如 Job Browser、File Browser 等)模拟其他用户。其他服务(如 HDFS 和 MapReduce)不使用 Hue Kerberos Ticket Renewer。它们将在启动时获取票证,并使用这些票证获取各种访问权限的委派令牌。每个服务根据需要处理自己的票证续订。
1. 转到Hue服务。
2. 单击实例选项卡。
3. 单击添加角色实例按钮。
4. 为与Hue Server相同的主机分配Kerberos Ticket Renewer序角色实例。
5. 在向导完成后,状态将显示已完成,并且 Kerberos Ticket Renewer 角色实例已配置。Hue 服务现在将与安全的 Hadoop 群集一起工作。
4.2.16启动所有服务
启动所有服务,在主页上,单击群集名称右侧的 并选择启动。
启动 Cloudera Management Service,在主页上,单击Cloudera Management Service右侧的 并选择启动。
4.2.17 部署客户端配置
在主页,单击群集名称右侧的 ,并选择部署客户端配置。
,并选择部署客户端配置。
4.2.18 创建 HDFS 超级用户主体
要为用户创建主目录,您需要对超级用户帐户具有访问权限。在 HDFS 中,运行 NameNode 进程的用户帐户(默认情况下为 hdfds)是一个超级用户。在安装 CDH 的过程中,CDH 会自动在每个群集主机上创建 hdfs 超级用户帐户。当为 HDFS 服务启用 Kerberos 时,您无法通过 sudo -u hdfs 命令访问 hdfs 超级用户帐户。要在 Kerberos 处于启用状态时能够访问 hdfs 超级用户帐户,您必须创建一个 Kerberos 主体或 AD 用户,并且其第一个或唯一一个组成部分必须是 hdfs。或者,您也可以指定其成员属于超级用户的超级用户组。
在kadmin.local或kadmin shell 中,键入以下命令来创建名为hdfs的Kerberos主体:
kadmin: addprinc hdfs@HADOOP.COM
此命令会提示您为 hdfs 主体创建密码。请使用强密码,因为此主体对 HDFS 中的所有文件提供超级用户访问权限。
要作为 hdfs 超级用户运行命令,您必须为 hdfs 主体获取 Kerberos 凭据。要执行此操作,请运行以下命令并提供密码:
$ kinit hdfs@HADOOP.COM
指定超级用户组
要指定超级用户组而不使用默认 hdfs 帐户,请按照以下步骤进行操作:
1.导航到HDFS服务 > 配置选项卡。
2.在“搜索”字段中键入超级用户以显示超级用户组属性。
3.将默认supergroup的值更改为适合您的环境的组名称。
4.单击保存更改。
为使此更改生效,您必须重启群集。
4.2.19 为每个用户帐户获取或创建 Kerberos 主体
在您的群集上配置和启用 Kerberos 之后,您和其他所有 Hadoop 用户都必须具有 Kerberos 主体或 Keytab 才能获取被允许访问该群集和使用 Hadoop 服务的 Kerberos 凭据。在此过程的下一步中,您需要创建自己的 Kerberos 主体,以便验证 Kerberos 安全是否正在您的群集上工作。如果您和其他 Hadoop 用户已经有 Kerberos 主体或 Keytab,或者您的 Kerberos 管理员可以提供它们,那么您可以直接跳到下一步。
在 kadmin.local 或 kadmin shell 中,使用以下命令为您的帐户创建主体,请将 username 替换为用户名:
kadmin: addprinc username@HADOOP.COM
4.2.20为每个用户准备群集
在您和其他用户可以访问群集之前,您必须执行一些任务来为每个用户准备主机。
1. 确保群集中的所有主机都有一个linux用户帐户并且该帐户的名称与用户的主体名称的第一个组成部分相同。例如,如果用户的主体名称是 joe@HADOOP.COM,则每个框中应存在linux帐户joe。
2. 为每个用户帐户在 HDFS 上的 /user 下创建一个子目录(例如 /user/joe)。将该目录的所有者和组更改为该用户。
$ hadoop fs -mkdir /user/joe $ hadoop fs -chown joe /user/joe
4.2.21为 Hadoop 角色的 HTTP Web Console 启用身份验证(可选)
HDFS、MapReduce 和 YARN 角色的 Web Console 的访问身份验证可通过相应的服务的配置选项启用。要启用此身份验证,请执行以下操作:
1.从群集选项卡中,选择要为其启用身份验证的服务(HDFS、MapReduce 或 YARN)。
2.单击配置选项卡。
3.展开服务范围 > 安全,选中启用 HTTP Web Console 的身份验证属性,然后保存您所做的更改。
将触发一个命令来生成新的所需凭据。
4. 在命令完成后,请重启该服务的所有角色。
4.2.22 确认Kerberos在集群上正常工作
登录到某一个节点后,切换到hdfs用户,然后用kinit来获取credentials
现在用’hadoop dfs -ls /’应该能正常输出结果
用kdestroy销毁credentials后,再使用hadoop dfs -ls /会发现报错
4.3 kafka使用SASL验证
kafka目前支持的机制有GSSAPI(Kerberos)和PLAIN ,在以上步骤中,Kafka brokers的SASL已配置,接下来配置Kafka客户端
4.3.1 生成jaas文件
客户端(生产者,消费者,connect,等等)用自己的principal认证集群(通常用相同名称作为运行客户端的用户)。因此,获取或根据需要创建这些principal。然后,为每个principal创建一个JAAS文件,KafkaClient描述了生产者和消费者客户端如何连接到broker。下面是一个客户端使用keytab的配置例子(建议长时间运行的进程)。在/etc/kafka/目录下创建kafka_client_jaas.conf文件
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/kafka/conf/kafka_client.keytab"
principal="kafka-client-1@HADOOP.COM";
};
创建kafka-client-1@HADOOP.COM
kadmin:addprinc -randkey kafka-client-1 kadmin:xst -k /etc/kafka/conf/kafka_client.keytab kafka-client-1
在使用producer和consumer java接口时,要在代码main方法中,加入
System.setProperty(“java.security.auth.login.config”,”/etc/kafka/kafka_client_jaas.conf”);
保证程序可以读取到jaas文件。
在producer和consumer的config里加入
props.put("sasl.kerberos.service.name", "kafka");
props.put("sasl.mechanism", " GSSAPI");
props.put("security.protocol", "SASL_PLAINTEXT");
对于java程序配置到以上步骤就可以了,以下步骤可以跳过。
对于命令行工具,比如kafka-console-consumer 或 kafka-console-producer,kinit连同 “useTicketCache=true”使用,如:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useTicketCache=true;
};
4.3.2 通过JAAS作为JVM参数(每个客户端的JVM)
在/opt/cloudera/parcels/KAFKA/lib/kafka/bin/kafka-run-class.sh文件中JVM performance options参数的KAFKA_JVM_PERFORMANCE_OPTS中加入
-Djava.security.auth.login.config=/etc/kafka/kafka_client_jaas.conf
4.3.3 生成producer.properties和consumer.properties文件
在/etc/kafka/conf/目录下生成producer.properties和consumer.properties
security.protocol=SASL_PLAINTEXT (or SASL_SSL) sasl.mechanism=GSSAPI sasl.kerberos.service.name=kafka
4.3.4 使用命令行工具进行生产消费
本文档中使用到的kafka parcel版本为2.0.2-1.2.0.2.p0.5,部署kerberos后,要使用新生产者:
kafka-console-producer --broker-list 172.16.18.201:9092 –topic test --producer.config config/producer.properties
新消费者:
kafka-console-consumer --bootstrap-server 172.16.18.201:9092 --topic test --new-consumer --from-beginning --consumer.config config/consumer.properties
5. HDFS权限控制
5.1HDFS启用 ACL
默认情况下,ACL 在集群上被禁用。要启用,将 dfs.namenode.acls.enabled 属性设为 true(在 NameNode 的 hdfs-site.xml 中)。
dfs.namenode.acls.enabled-->TRUE
5.2使用 Cloudera Manager 启用 HDFS-Sentry 插件
1. 在服务范围类别下,转到安全。
2. 选中启用 Sentry 同步复选框。
3 .使用 Sentry 同步路径前缀属性列出应强制实施 Sentry 权限前缀的 HDFS 路径。可以指定多个 HDFS 路径前缀。默认情况下,该属性指向 user/hive/warehouse 并且必须始终为非空。此处列出的 HDFS 地区以外的表就不会出现 HDFS 权限同步。
4. 单击保存更改。
5. 重新启动群集。请注意,在群集重新启动后,可能还需要两分钟让权限同步生效。
5.3测试 Sentry 同步插件
直接在 HDFS 中访问表文件。例如:
列出文件夹中的文件,并验证在 HDFS(包括 ACL)中显示的文件权限是否与 Sentry 中配置的相匹配。
运行科访问这些文件的 MapReduce、Pig 或 Spark 作业。选择除 HiveServer2 和 Impala 以外的任何工具。
6. Kafka权限控制
6.1启动kafka acl
6.1.1在cm主页中点击kafka,点击配置 > 高级

6.1.2 配置kakfa.properties的kafka Broker高级配置代码段(安全阀)
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer super.users=User:kafka;
User:kafka默认对应principal:kafka@HADOOP.COM(超级账户,具有为其他账户赋予权限的权利)
6.2 命令行界面
6.2.1 kafka-acl支持选项
Kafka认证管理CLI(和其他所有的CLI)可以在bin目录中找到。CLI脚本名是kafka-acls.sh。以下列出了所有脚本支持的选项:
选项 描述 默认 类型选择 --add 添加一个acl Action --remove 移除一个acl Action --list 列出acl Action --authorizer Authorizer的完全限定类名 Kafka.security.auth. SimpleAclAuthorizer Configuration --authorizer -properties Key=val,传给authorizer进行初始化,例如:zookeeper.connect=localhost:2181 Configuration --cluster 指定集群作为资源。 Resource --topic [topic name] 指定topic作为资源 Resource --group [group-name] 指定consumer-group作为资源 Resource --allow -principal 添加到允许访问的ACL中,Principal是Principal Type:name格式,可以指定多个 Principal --deny -principal 添加到拒绝访问的ACL中,Principal是Principal Type:name格式,可以指定多个 Principal --allow-host --allow-principal中的princiapl的IP的地址被访问。 如果--allow-principal指定的默认值是*,则意味着指定“所有主机” Host --deny-host --deny-principal中的princiapl的IP的地址被访问。 如果--allow-principal指定的默认值是*,则意味着指定“所有主机” Host --produce 为producer角色添加/删除acl。生成acl,允许在topic上WRITE, DESCRIBE和CREATE集群。 Convenience --consumer 为consumer角色添加/删除acl。生成acl,允许在topic上READ, DESCRIBE和consumer-group上READ。 Convenience
6.2.2 添加acl
假设你要添加一个acl “允许198.51.100.0和User:Alice对主题是Test-Topic有Read和Write的执行权限” 。通过执行下列选项
kafka-acls --authorizer-properties zookeeper.connect=172.16.18.201:2181/kafka --add --allow-principal User:Alice --allow-host 172.16.18.202 ---operation Read --operation Write --topic Test-topic
默认情况下,所有的principal在没有一个明确的对资源操作访问的acl都是拒绝访问的。在极少的情况下,定义了acl允许访问所有,但一些principal我们将必须使用 --deny-principal 和 --deny-host选项。例如,如果我们想让所有用户读取Test-topic,只拒绝IP为198.51.100.3的User:BadBob,我们可以使用下面的命令:
kafka-acls --authorizer-properties zookeeper.connect=172.16.18.201:2181/kafka --add --allow-principal User:* --allow-host * --deny-principal User:BadBob --deny-host 198.51.100.3 --operation Read --topic Test-topic
需要注意的是--allow-host和deny-host仅支持IP地址(主机名不支持)。上面的例子中通过指定--topic [topic-name]作为资源选项添加ACL到一个topic。同样,用户通过指定--cluster和通过指定--group [group-name]消费者组添加ACL。
6.2.3 删除acl
删除和添加是一样的,--add换成--remove选项,要删除第一个例子中添加的,可以使用下面的命令:
kafka-acls --authorizer-properties zookeeper.connect=172.16.18.201:2181/kafka --remove --allow-principal User:Alice --allow-host 172.16.18.202 --operation Read --operation Write --topic Test-topic
6.2.4 acl列表
我们可以通过指定与资源--list选项列出任何资源的ACL,alc列表存储在zookeeper中。要列出Test-topic,我们可以用下面的选项执行CLI所有的ACL:
kafka-acls --authorizer-properties zookeeper.connect=172.16.18.201:2181/kafka --list --topic Test-topic
6.2.5 添加或删除作为生产者或消费者的principal
acl管理添加/移除一个生产者或消费者principal是最常见的使用情况,所以我们增加更便利的选项处理这些情况。为主题Test-topic添加一个生产者User:Alice,我们可以执行以下命令的生产:
kafka-acls --authorizer-properties zookeeper.connect=172.16.18.201:2181/kafka --add --allow-principal User:Alice --producer --topic Test-topic
同样,添加Alice作为主题Test-topic的消费者,用消费者组为Group-1,我们只用 --consumer 选项:
kafka-acls --authorizer-properties zookeeper.connect=172.16.18.201:2181/kafka --add --allow-principal User:Bob --consumer --topic test-topic --group Group-1
注意,消费者的选择,我们还必须指定消费者组。从生产者或消费者角色删除主体,我们只需要通过--remove选项。
以上是关于CDH 配置 Sentry 服务的主要内容,如果未能解决你的问题,请参考以下文章
0031-如何在CDH启用Kerberos的情况下安装及使用Sentry
CDH-Kerberos环境下使用flume消费带Sentry认证的kafka数据保存到hdfs中