GMTC—《微信客户端怎样应对弱网络》
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GMTC—《微信客户端怎样应对弱网络》相关的知识,希望对你有一定的参考价值。
参考技术A在ppt中主要讲了在弱网络环境下,业界和微信是如何实践的,有底层的TCP扩展技术的使用,也有应用层的优化。在底层TCP的实践中,主要讲了TCP快速重传,Snoop TCP使用,HARQ使用,TLP的使用和ER算法等。在应用层中,主要有复合连接,协议合并,渐进发图等。
我们熟悉的快速重传算法FR(Fast Recovery)是在收到3个duplicate ACK时就开启重传,而不用等到RTO超时。
在这种快速重传,在只丢一个包时有效,当真实情况是丢了多个包时,后面几个丢包只能依靠超时重传了。超时一个,ssthreah减半,tcp传输速度呈指数下降。于是有了使用SACK的FACK(Forward Acknowledgment)快速恢复算法。
SACK信息是通过TCP头的选项部分提供的,信息分两种,一种标识是否支持SACK,是在TCP握手时发送;另一种是具体的SACK。TCP握手的前两个包中,通过SACK允许选项来表明自己是否支持此功能。如果收到的数据块序列号大于期待的序列号,说明中间包被丢弃或延迟,此时发送SACK告知发送方具体网络丢包的情况。SACK选项可以使TCP发送方只发送丢失的数据而不用发送后续全部数据,提高了数据的传输效率。
备注: 要使用SACK特性,需要tcp两端同时支持才行。
因为移动环境,会使tcp链路的状态时好时坏,进而会频繁触发tcp拥塞控制,会使网络状况更加糟糕。因而引入了Snoop协议。
Snoop 实现的具体过程是:在基站,引人一个 Snoop 探察模块,该模块运行于链路层之上,监视每个tcp 连接在两个方向上的所有分组。Snoop模块会监视每一个通过tcp连接传送的包,并对没有被接收端确认的数据包进行缓存,当Snoop模块检测到超时或者收到重复ack时,就认为发生丢包,于是Snoop就从自己的缓冲区中取出丢失的包进行重传,对于重复的ack,snoop会阻止其传回发送端,从而避免发送端不断启动快速重传和拥塞避免算法,进而改善无线链路的tcp性能。
在无线传输环境下,信道噪声和由于移动性带来的衰落以及其他用户带来的干扰使得信道传输质量很差,所以应该对数据分组加以保护来抑制各种干扰。这种保护主要是采用前向纠错编码(FEC)。与TCP的自动重传技术(ARQ)结合,即HARQ(Hybrid Automatic Repeat Request ) 混合自动重传请求。
在tcp快速重传算法中,需要有多个重复的ACK来触发,但在如果尾包发生丢失,但是如果发生了尾丢包,由于尾包后面没有更多的数据包,也就没有办法触发任何的dupack。为解决这种尾丢包的问题,诞生了TLP(TCP Tail Loss Probe)算法。
TLP算法的详细过程可以参考 这里 。目前TLP算法在腾讯中使用较多,开启TCP后,能列表页打开速度测试中,能比原先最大提升 20% 。
另外Early Retransmit(ER)算法与TLP的目的和方式相似,都是为了解决在没有足够重复ACK的情况来触发快速重传。
小结: 虽然TCP不断改进,越来越适合移动互联网,但从RFC制定到Kernel层实现到用户覆盖很还漫长,新特性接纳慢。而QUIC协议可以算是另辟蹊径的方式,为移动互联网量身定制,但在 quic_toy 性能测试中,quic还没有达到能和tcp相提并论的水平。
通过建立多个连接,来更快找到可用的链路。截图来自ppt。
在腾讯的测试中,复合连接能使连接成功率提升5%。
其核心思想就是减少客户端向服务端发起的请求数,将一些非关键请求合并起来,由关键请求上传,之后由服务端将非关键请求异步完成。
使用Progressive JPEG编码方式,在网络差的情况下,能够传输一部分数据,就能让用户看到并不清晰的图片,提升用户体验。其流程如下(图片来自ppt)
tcp的优化特性真的好多,可以挑一些特性做一个性能对比。quic协议的toy测试是两年前的,打算自己重新测试一下看看。复合连接和渐进发图都是不错的点子,可以我司的产品中尝试实践。
程序员应该怎样应对“扯皮”
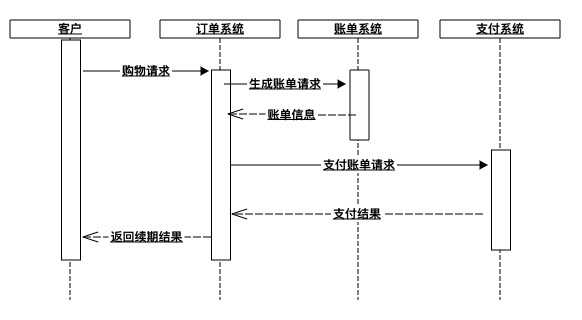
- 如果我接住了这个“烫手的山芋”,肯定要花费大量的时间去研究上游的业务来重现问题,最后发现问题是出在账单部门,那么我的时间基本上算是白费了。
- 如果直接把“球”踢回去却不给出解决方案的建议,那么上游的同事可能也会比较迷茫,还会说我推卸责任,甚至可能亮“板砖”。软件行业不同部门之间的互殴咱也不是没见过,这个行业绝对属于高危行业。
- 而给出了合理的建议之后,订单部门的同事只需在他的领域内提供出边界数据就OK了。有了边界数据,应该找谁来负责就柳暗花明了。大家谁都不越界,谁都不背锅。
- 遇到责任不明确的跨业务领域的“扯皮”,关键要明确边界(接口)数据。如果没有边界(接口)数据,应该本着上游负责制。上游找到证据可以“踢”给下游,如果没有证据,“下游”应该踢回去,以避免不必要的浪费时间。
- 系统设计时,对于接口数据(我调别人以及别人调我)可以视情况保存一下,以避免扯皮时没有证据。本例中订单部门之所以没保存,是因为情况不允许。
以上是关于GMTC—《微信客户端怎样应对弱网络》的主要内容,如果未能解决你的问题,请参考以下文章