Roberta: Bert调优
Posted 张雨石
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Roberta: Bert调优相关的知识,希望对你有一定的参考价值。
最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,文章大部分都发布在公众号【雨石记】上,欢迎关注公众号获取最新文章。
- Transformer:Attention集大成者
- GPT-1 & 2: 预训练+微调带来的奇迹
- Bert: 双向预训练+微调
- Bert与模型压缩
- Transformer + AutoML: 进化的Transformer
- Bert变种
- GPT-3
- 更多待续
Overall
Bert出来以后,迅速引爆了NLP领域,出现了很多的针对模型的改进。然而,Roberta用实力表明,只对原来的Bert模型调优就可以有明显的提升。
Roberta,是Robustly Optimized BERT Approach的简称。
Robustly用词很赞,既有“鲁棒的”,又有”体力的”。Roberta是一片实验为基础的论文,有点体力活的意思,但是结果又非常的鲁棒可信赖。
先来回顾一下Bert中的一些细节:
- 在输入上,Bert的输入是两个segment,其中每个segment可以包含多个句子,两个segment用[SEP]拼接起来。
- 模型结构上,使用Transformer,这点跟Roberta是一致的。
- 学习目标上,使用两个目标:
- Masked Language Model(MLM): 其中15%的token要被Mask,在这15%里,有80%被替换成[Mask]标记,有10%被随机替换成其他token,有10%保持不变。
- Next Sentence Prediction: 判断segment对中第二个是不是第一个的后续。随机采样出50%是和50%不是。
- Optimizations:
- Adam, beta1=0.9, beta2=0.999, epsilon=1e-6, L2 weight decay=0.01
- learning rate, 前10000步会增长到1e-4, 之后再线性下降。
- dropout=0.1
- GELU激活函数
- 训练步数:1M
- mini-batch: 256
- 输入长度: 512
- Data
- BookCorpus + English Wiki = 16GB
Roberta在如下几个方面对Bert进行了调优:
- Masking策略——静态与动态
- 模型输入格式与Next Sentence Prediction
- Large-Batch
- 输入编码
- 大语料与更长的训练步数
Masking策略——静态与动态
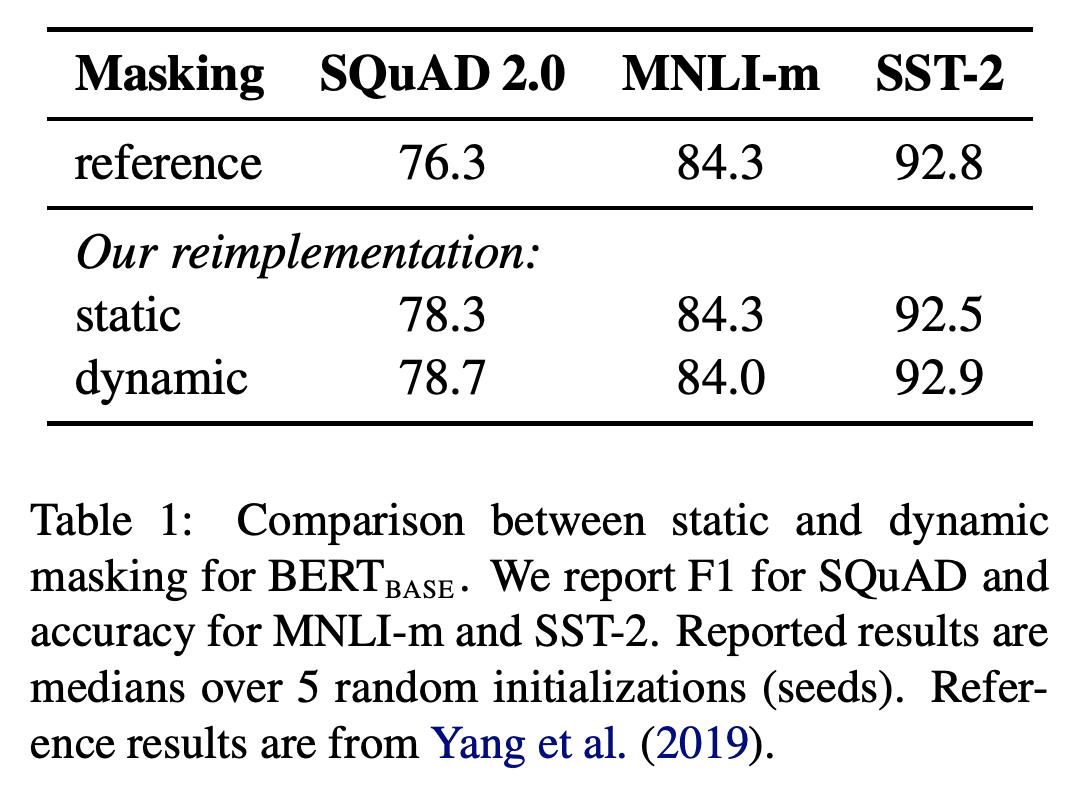
原来的Bert中是在训练数据中静态的标上Mask标记,然后在训练中是不变的,这种方式就是静态的。
Roberta尝试了一种动态的方式,说是动态,其实也是用静态的方式实现的,把数据复制10份,每一份中采用不同的Mask。这样就有了10种不同的Mask数据。
从结果中,可以看到动态mask能带来微小的提升。
模型输入格式与Next Sentence Prediction
Bert的模型输入中是由两个segment组成的,因而就有两个问题:
- 两个segment是不是必要?
- 为什么是segment而不是单个的句子?
因此设置了四个实验:
- Segment-Pair + NSP
- Sentence-Pair + NSP: 只用了sentence以后,输入的长度会变少,为了使得每一步训练见到的token数类似,在这里会增大batch size
- Full-Sentence: 每一个样本都是从一个文档中连续sample出来的,如果跨过文档边界,就添加一个[SEP]的标记,没有NSP损失。
- Doc-Sentence: 类似于Full-Sentence,但是不会跨过文档边界。
从实验结果中可以看到,改用Sentence-Pair会带来一个较大的损失。猜测是因为这样无法捕捉long-term的依赖。
另外,Full-Sentence和Doc-Sentence能够带来微小的提升,说明NSP不是必须的。
这点跟Bert中的消融实验结论相反,但是请注意它们的输入还是不同的,原始Bert中的输入是Segment-Pair,有50%/50%的采样,而Full/Doc-Sentence中则是从文章中连续sample来的句子。
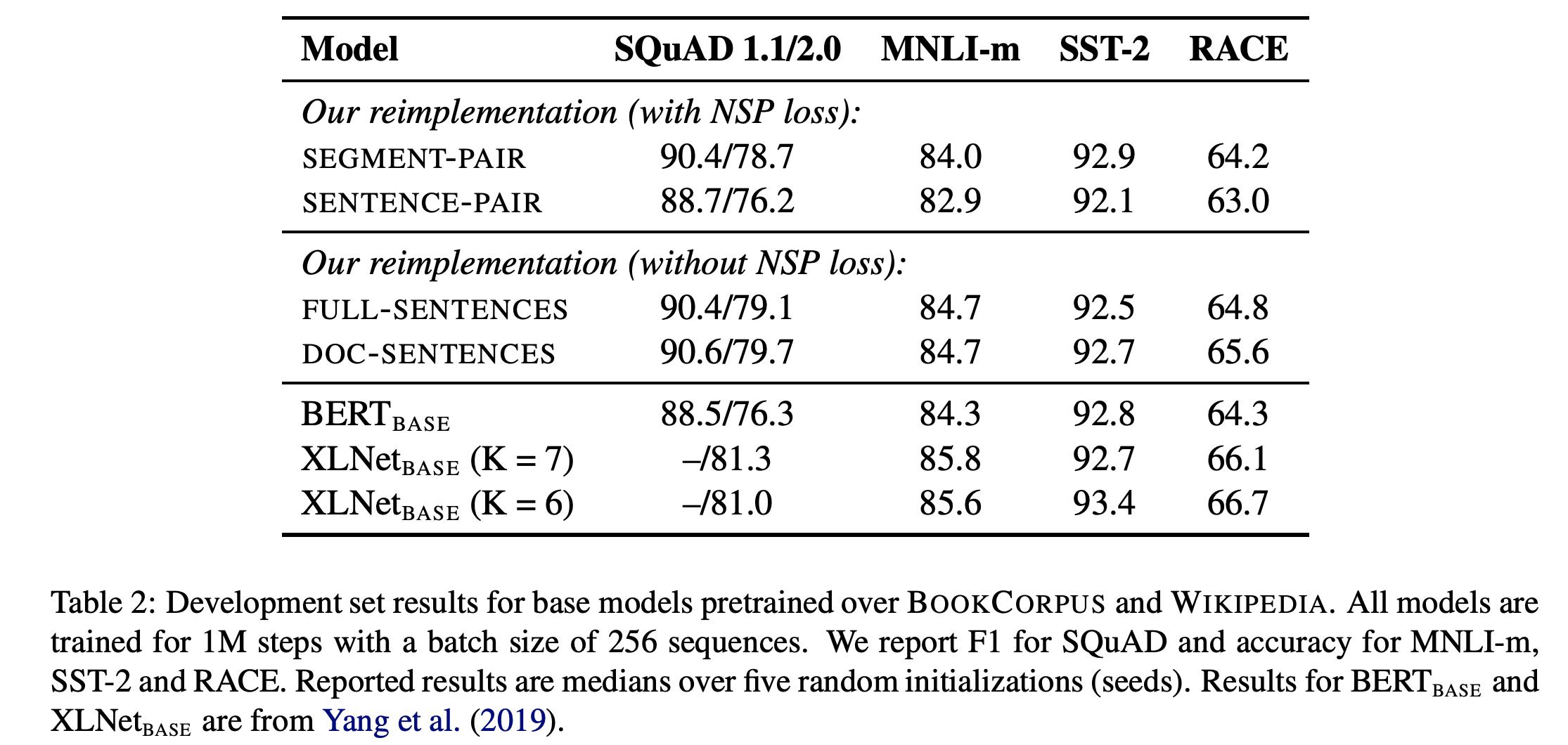
因为Doc-Sentence会导致不同的batch_size(因为要保证每个batch见到的token数类似),所以在Roberta中,使用Full-Sentence模式。
Large-Batch
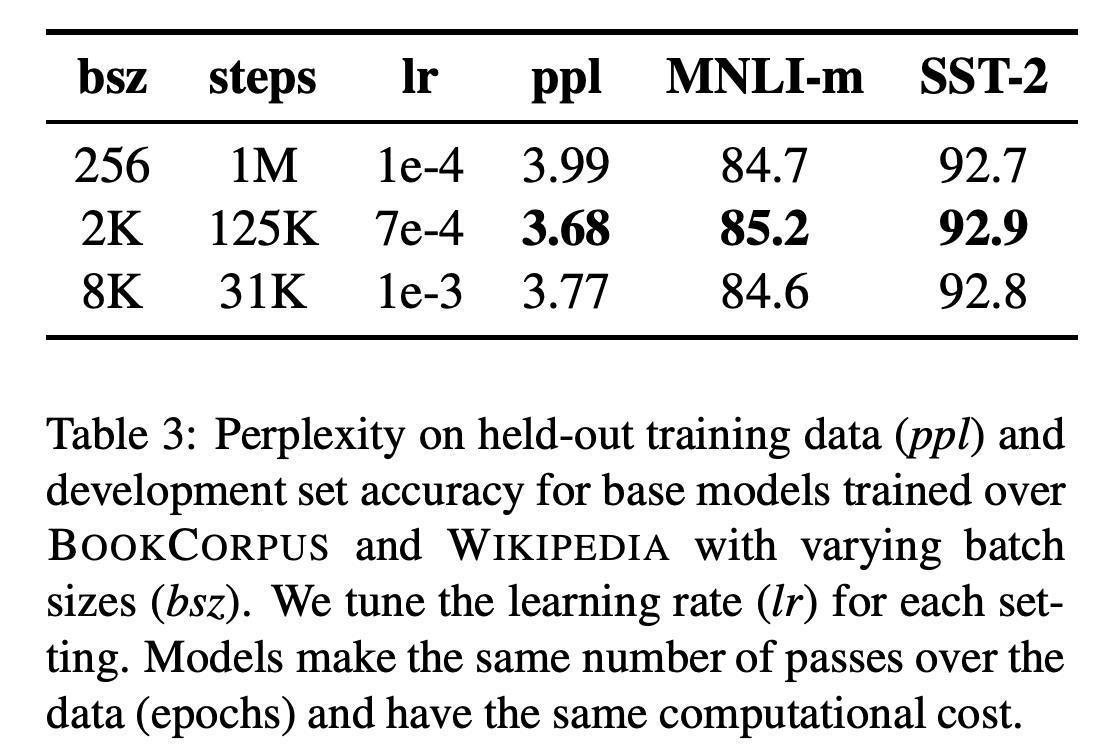
现在越来越多的实验表明增大batch_size会使得收敛更快,最后的效果更好。原始的Bert中,batch_size=256,同时训练1M steps。
在Roberta中,实验了两个设置:
- batch_size=2k, 训练125k steps。
- batch_size=8k, 训练31k steps。
从结果中看,batch_size=2k时结果最好。
输入编码
不管是GPT还是Bert,都是用的BPE的编码方式,BPE是Byte-Pair Encoding的简称,是介于字符和词语之间的一个表达方式,比如hello,可能会被拆成“he”, “ll”, “o”, 其中BPE的字典是从语料中统计学习到的。
原始Bert中,采用的BPE字典是30k, Roberta中增大到了50K,相对于Bertbase和Bertlarge会增加15M/20M的参数。
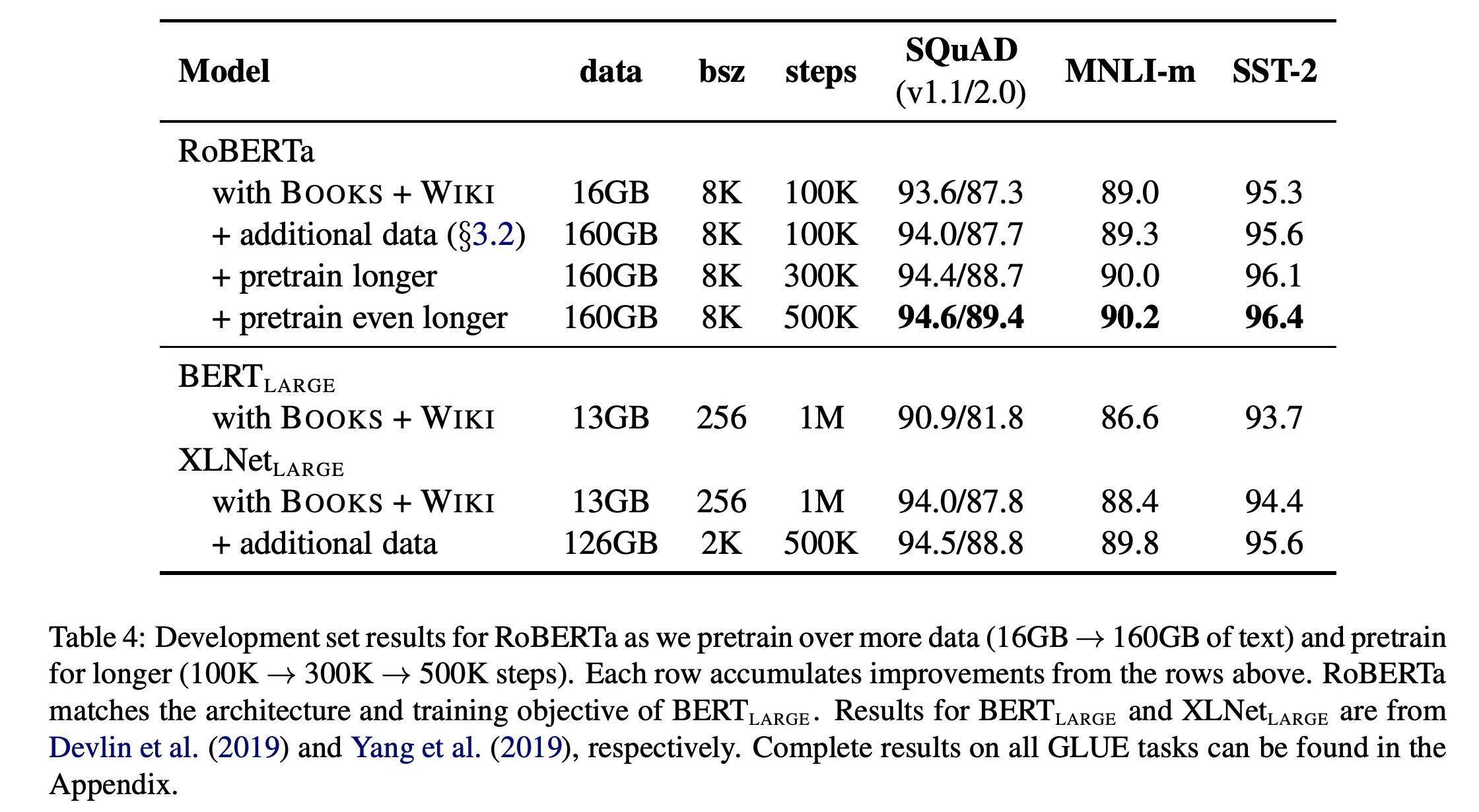
增大语料和训练步数
增大语料和训练步数还是能带来比较大的提升的。
Roberta
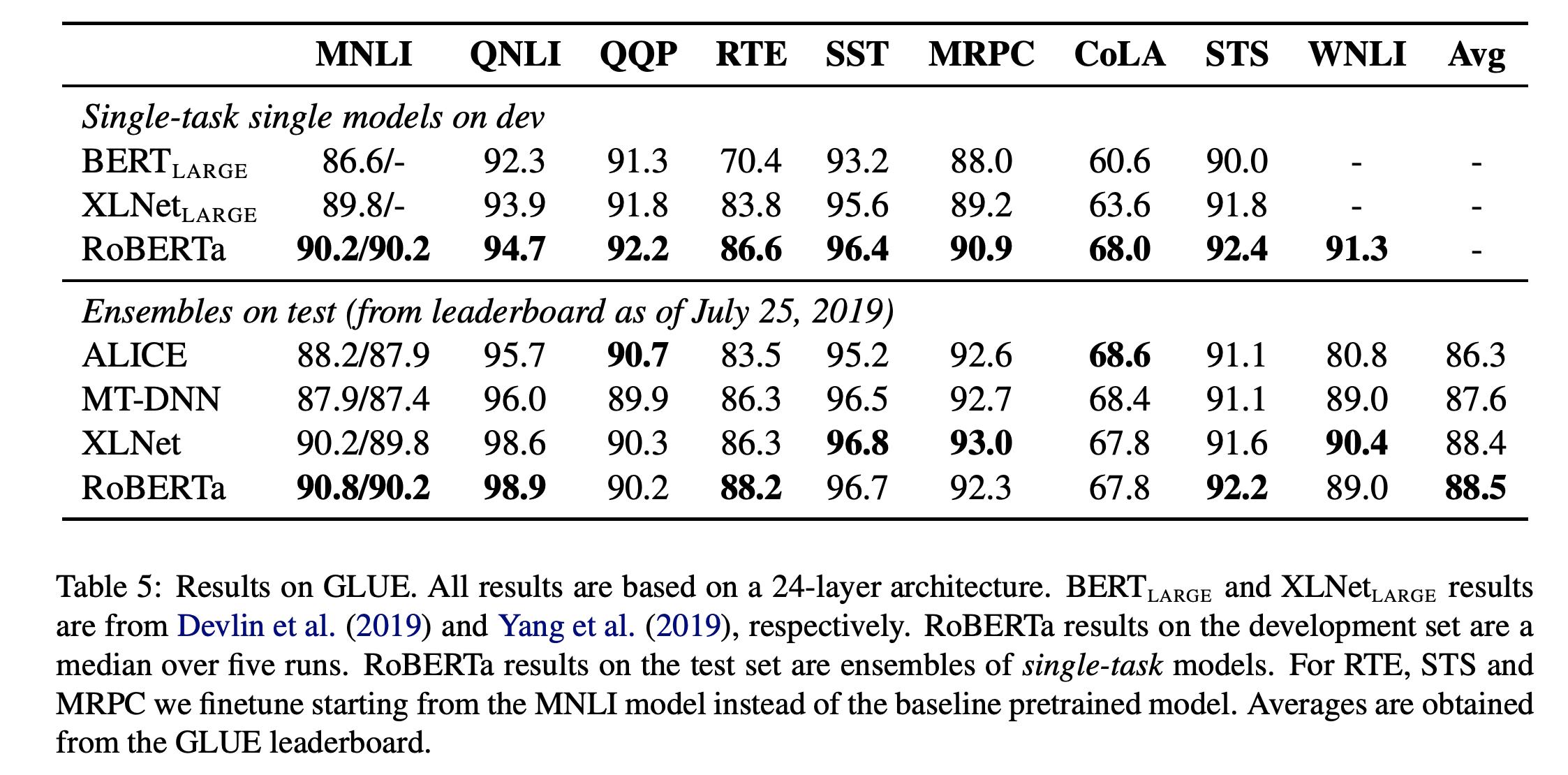
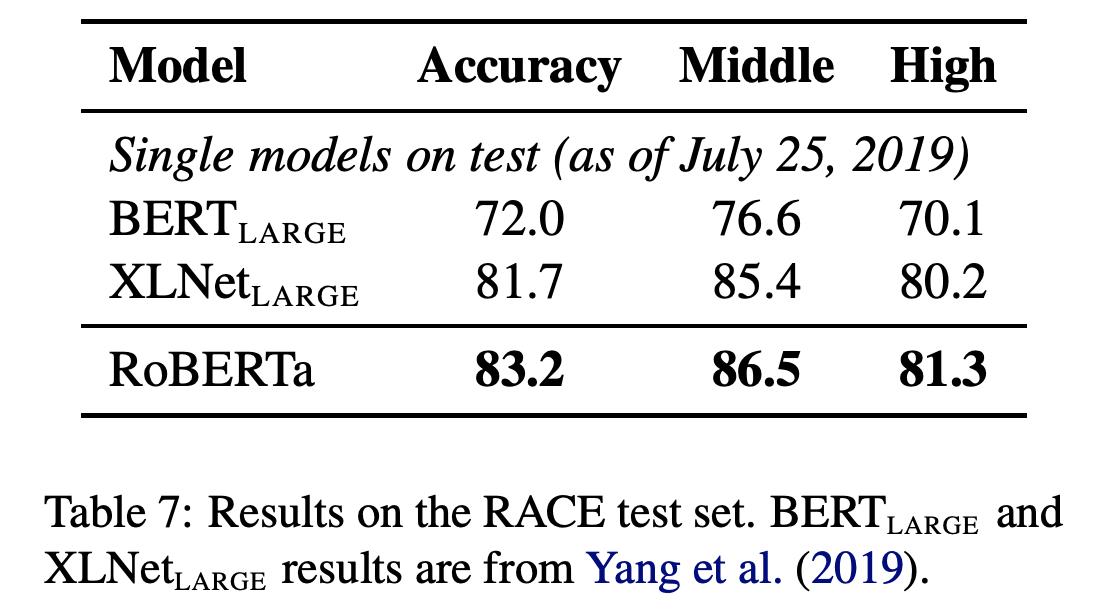
就是上面所有改进的总和。可以看到,在各项任务中的提升还是很大的。Roberta的训练在1024个 V100GPU上训练一天左右。
思考与总结
从上面的各种实验结果中看,可以得到如下结论:
- NSP不是必须的loss
- Mask的方式虽不是最优但是已接近。
- 增大batch size和增大训练数据能带来较大的提升。
由于Roberta出色的性能,现在很多应用都是基于Roberta而不是原始的Bert去微调了。
勤思考, 多提问是Engineer的良好品德。
提问如下:
- 继续增大数据集,还有没有可能提升?数据集的量与所带来的提升是一个什么分布?
- 不管是Bert还是Roberta,训练时间都很长,如何进行优化?
回答后续公布,欢迎关注公众号【雨石记】

参考文献
- [1]. Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
以上是关于Roberta: Bert调优的主要内容,如果未能解决你的问题,请参考以下文章