Kylin 维度高级设置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kylin 维度高级设置相关的知识,希望对你有一定的参考价值。
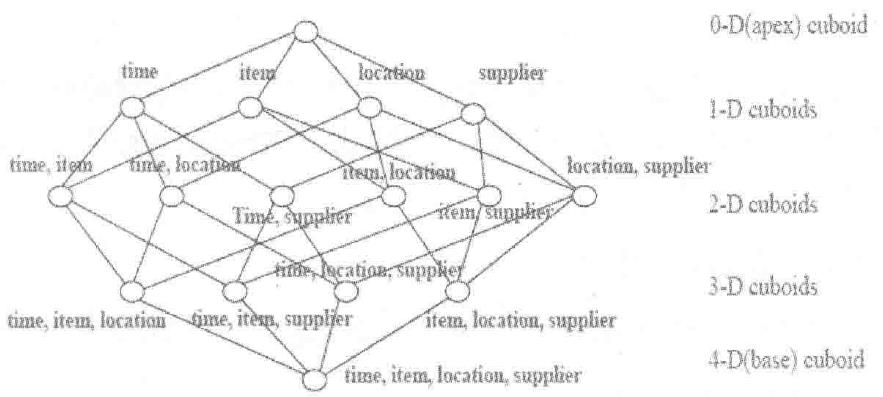
参考技术AApache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2^N 个 Cuboid, 如图所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个 Cuboid。
随着维度数目的增加 Cuboid 的数量会爆炸式地增长,不仅占用大量的存储空间还会延长 Cube 的构建时间。为了缓解 Cube 的构建压力,减少生成的 Cuboid 数目,占用存储空间,同时提高查询性能,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括 聚合组(Aggregation Group) 、 联合维度(Joint Dimension) 、 层级维度(Hierachy Dimension) 和 必要维度(Mandatory Dimension) 等。
用户根据自己关注的维度组合,可以划分出自己关注的组合大类,这些大类在 Apache Kylin 里面被称为聚合组。上面的例子如果用户仅仅关注维度 AB 组合和维度 CD 组合,那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图所示,生成的 Cuboid 数目从 16 个缩减成了 8 个。
用户关心的聚合组之间可能包含相同的维度,例如聚合组 ABC 和聚合组 BCD 都包含维度 B 和维度 C。这些聚合组之间会衍生出相同的 Cuboid,例如聚合组 ABC 会产生 Cuboid BC,聚合组 BCD 也会产生 Cuboid BC。这些 Cuboid不会被重复生成,一份 Cuboid 为这些聚合组所共有,如图所示。
有了聚合组用户就可以粗粒度地对 Cuboid 进行筛选,获取自己想要的维度组合。
假设创建一个交易数据的 Cube,包含了以下一些维度:顾客 ID(buyer_id)、交易日期(cal_dt)、付款方式(pay_type)和买家所在的城市(city)。分析师有时候需要通过分组聚合 city 、cal_dt 和 pay_type 来获知不同消费方式在不同城市的应用情况;有时候,需要通过聚合 city 、cal_dt 和 buyer_id,来查看顾客在不同城市的消费行为。
在上述的实例中,推荐建立两个聚合组:
聚合组 1: [cal_dt, city, pay_type]
聚合组 2: [cal_dt, city, buyer_id]
在不考虑其他干扰因素的情况下,这样的聚合组将节省不必要的 3 个 Cuboid(参考上图): [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id],节省了存储资源和构建的执行时间。
Case 1:
将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case2:
将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case3:
如果有一条不常用的查询
不存在匹配的 Cuboid [pay_type, buyer_id],此时,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
用户有时并不关心维度之间各种细节的组合方式,例如用户的查询语句中仅仅会出现 group by A, B, C,而不会出现 group by A, B 或者 group by C 等等这些细化的维度组合。这一类问题就是联合维度所解决的问题。
例如将维度 A、B 和 C 定义为联合维度,Apache Kylin 就仅仅会构建 Cuboid ABC,而 Cuboid AB、BC、A 等等Cuboid 都不会被生成。最终的 Cube 结果如图所示,Cuboid 数目从 16 减少到 4。
假设创建一个交易数据的 Cube,包含了以下一些维度:交易日期(cal_dt)、交易城市(city),顾客性别(sex_id)和支付类型(pay_type) 等。分析师常用的分析方法为通过按照交易时间、交易地点和顾客性别来聚合,获取不同城市男女顾客间不同的消费偏好。
在上述的实例中,推荐在已有的聚合组中建立一组联合维度:
聚合组:[cal_dt, city, sex_id,pay_type]
联合维度: [cal_dt, city, sex_id]
在不考虑其他干扰因素的情况下,将创建 4 个 Cuboid(参考上图三): [cal_dt, city, sex_id, pay_type]、[cal_dt, city, sex_id]、[pay_type] 和 [*],节省了存储资源和构建的执行时间。
Case 1:
从Cuboid [cal_dt, city, sex_id]中获取数据
Case2:
如果有一条不常用的查询
不存在匹配的 Cuboid [cal_dt, city]。此时,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
用户选择的维度中常常会出现具有层级关系的维度。例如对于国家(country)、省份(province)和城市(city)这三个维度,从上而下来说国家/省份/城市之间分别是一对多的关系。也就是说,用户对于这三个维度的查询可以归类为以下三类:
基于ABCD四个维度的场景,假设维度 A 代表国家,维度 B 代表省份,维度 C 代表城市,那么ABC 三个维度可以被设置为层级维度,生成的Cube 如图所示,Cuboid 数目从 16 减小到 8。
Cuboid [A,C,D]=Cuboid[A, B, C, D],Cuboid[B, D]=Cuboid[A, B, D],因而 Cuboid[A, C, D] 和 Cuboid[B, D] 就不必重复存储。
假设创建一个交易数据的 Cube,包含了以下一些维度:交易城市(city),交易省(province),交易国家(country)和支付类型(pay_type)等。分析师可以通过按照交易城市、交易省份、交易国家和支付类型来聚合,获取不同层级的地理位置消费者的支付偏好。
在上述的实例中,建议在已有的聚合组中建立一组层级维度(国家country/省province/城市city),包含的维度和组合方式:
聚合组:[country, province, city,pay_type]
层级维度: [country, province, city]
Case 1:
从城市维度获取消费偏好
将从 Cuboid [country, province, city, pay_type] 中获取数据。
Case 2:
从省级维度获取消费偏好
将从Cuboid [country, province, pay_type] 中获取数据。
Case 3:
从国家维度获取消费偏好
将从Cuboid [country, pay_type] 中获取数据。
用户有时会对某一个或几个维度特别感兴趣,所有的查询请求中都存在 group by 这个维度,那么这个维度就被称为必要维度,只有包含此维度的 Cuboid 会被生成。假设维度A是必要维度,那么生成的 Cube 如图所示,维度数目从16变为9。
假设创建一个交易数据的 Cube,包含了以下一些维度:交易时间(order_dt)、交易地点(location)、交易商品(product)和支付类型(pay_type)等。其中,交易时间就是一个被高频作为分组条件(group by)的维度。 如果将交易时间 order_dt 设置为必要维度,只有带有 order_dt 的 Cuboid 会被创建
Kylin工作原理体系架构
核心思想:预计算。
对多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube,并存在HBase中,供查询时直接访问
将高复杂度的聚合运算、多表连接……操作转换成对预计算结果的查询。决定了Kylin拥有很好的快速查询、高并发能力
理论基础:空间换时间
Cuboid:Kylin中将维度任意组合成为一个Cuboid
Cube:Kylin中将所有维度组合成为一个Cube,即包含所有的Cubeid

为了更好地使用Hadoop大数据环境,Kylin从通常用来做数据仓库的HIve中读取源数据,使用Mapreduce作为Cube构建的引擎,并将于计算结果保存在HBase中,对外暴露Restful API/JEBC/ODBC的查询接口。
Kylin支持标准的ANSI SQL,所以可以和常用分析工具(Tableau、Excel)进行无缝对接
restful api:
符合REST架构设计的API。
RESTful架构,就是目前最流行的一种互联网软件架构。它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用
REST,即Representational State Transfer的缩写
如果一个架构符合REST原则,就称它为RESTful架构
什么是RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
JDBC
(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序
ODBC
开放数据库连接(Open Database Connectivity,ODBC)是微软公司开放服务结构(WOSA,Windows Open Services Architecture)中有关数据库的一个组成部分,它建立了一组规范,并提供了一组对数据库访问的标准API(应用程序编程接口)。
这些API利用SQL来完成其大部分任务。ODBC本身也提供了对SQL语言的支持,用户可以直接将SQL语句送给ODBC。
开放数据库互连(ODBC)是Microsoft提出的数据库访问接口标准。
开放数据库互连定义了访问数据库API的一个规范,这些API独立于不同厂商的DBMS,也独立于具体的编程语言(但是Microsoft的ODBC文档是用C语言描述的,许多实际的ODBC驱动程序也是用C语言写的。)
ODBC规范后来被X/OPEN和ISO/IEC采纳,作为SQL标准的一部分,具体内容可以参考《ISO/IEC 9075-3:1995 (E) Call-Level Interface (SQL/CLI)》等相关的标准文件。
ANSI SQL
“美国国家标准化组织(ANSI)”是一个核准多种行业标准的组织。
SQL作为关系型数据库所使用的标准语言,最初是基于IBM的实现在1986年被批准的。
1987年,“国际标准化组织(ISO)”把ANSI SQL作为国际标准。
体系架构:
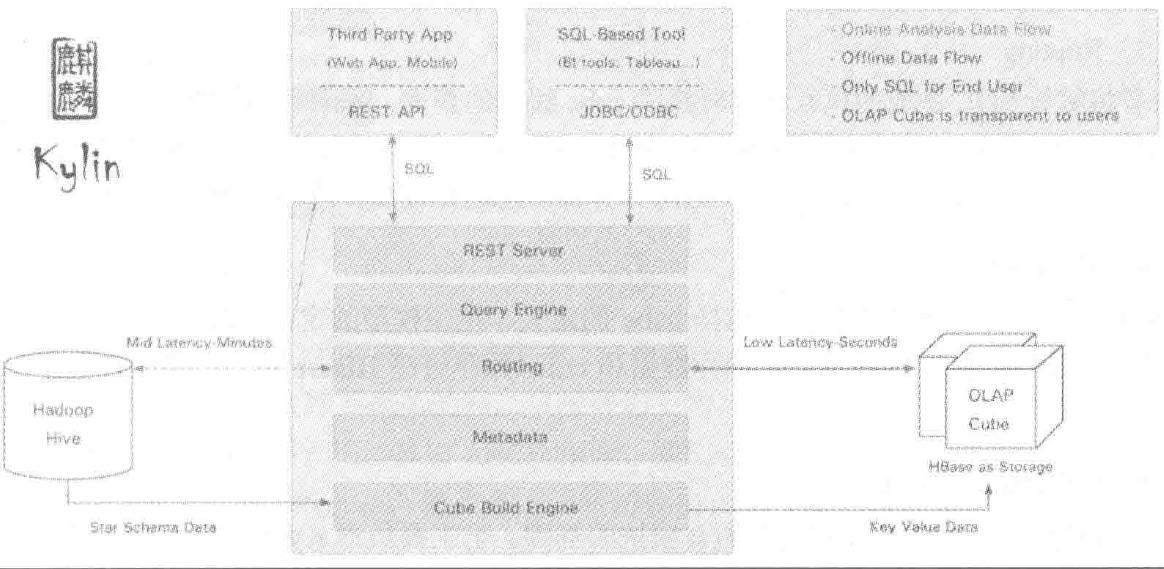
Kylin是一个MOLAP(多维在线联机分析处理)系统,将Hive中的数据进行预计算,利用Hadoop的Mapreduce分布式计算框架来实现
Kylin获取的表是星型模型结构的。目前建模时,只支持一张事实表,多张维表。
如果业务需求比较复杂,就要考虑在Hive中进行进一步处理。(比如生成一张大的宽表,或者采用View代替)
HBase:Kylin中用来存储OLAP分析的Cube数据的地方,实现多维数据集的交互式查询



Cube构建
Layer Cubing:按照dimension数量从大到小的顺序,从Base Cuboid开始,依次基于上一层Cubeid的结果进行再聚合。每一层的计算都是一个单独的MapReduce任务
逐层算法,启动N+1轮MapReduce计算:
第一轮,读取原始数据RawData,去掉不相关的列,只保留相关的列。同时对维度列进行压缩编码(此处,计算出ABCD组合,即base cuboid)
此后每一轮MapReduce,输入是上一轮的输出,以重用之前的计算结果,去掉要聚合的维度,算出新的Cuboid,直到最后算出所有的Cubeid

1.5.x开始引入Fast(in-mem) cubing算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压力。
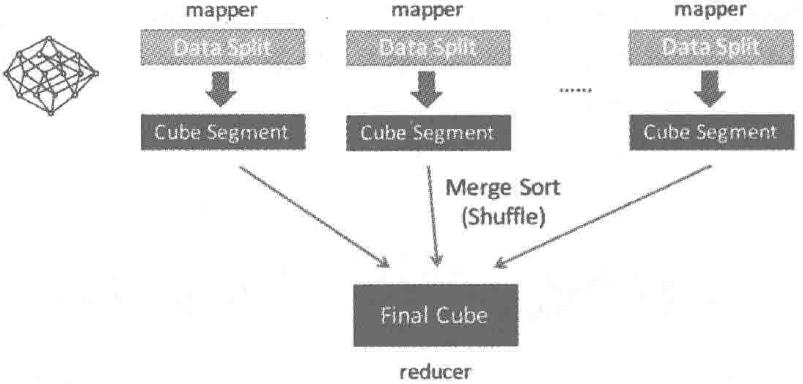
MapReduce的计算结果最终保存到HBase中,HBase中每行记录的Rowkey由dimention组成,measure会保存再Column family中。为了减少存储代价,会对dimension和measure进行编码。
Kylin的Sql查询
Cube构建完成后,可以查询维度对应的度量值了。
查询时,SQL语句被SQL解析器翻译成一个解析计划,从这个计划可以准确知道用户要查哪些表,怎样join起来,有哪些过滤条件。Kylin用这个计划去匹配找寻到合适的Cube
如果有Cube命中,这个计划会发送到存储引擎,翻译成对存储(默认HBase)相应的Scan操作
group by、过滤条件的列,用来找到Cuboid,过滤条件会被转换成Scan的开始、结束值,以缩小Scan的范围
Scan的result、Rowkey会被反向解码成各个dimension的值,Value会被解码成Metrics值,同时利用HBase列存储的特性,可以保证Kylin有良好的快速响应、高并发
Kylin的特性、生态圈
1.可扩展、超快OLAP引擎
2.Hadoop ANSI SQL 接口
3.交互式查询能力
4.多维立方体MOLAP Cube
5.与BI工具(Tableau)无缝整合
6.其他特性

LDAP:
LDAP是轻量目录访问协议,英文全称是Lightweight Directory Access Protocol,一般都简称为LDAP。
它是基于X.500标准的,但是简单多了并且可以根据需要定制。与X.500不同,LDAP支持TCP/IP,这对访问Internet是必须的。
LDAP的核心规范在RFC中都有定义,所有与LDAP相关的RFC都可以在LDAPman RFC网页中找到。
LDAP目录以树状的层次结构来存储数据。如果你对自顶向下的DNS树或UNIX文件的目录树比较熟悉,也就很容易掌握LDAP目录树这个概念了。就象DNS的主机名那样,
LDAP目录记录的标识名(Distinguished Name,简称DN)是用来读取单个记录,以及回溯到树的顶部。
Kylin生态圈
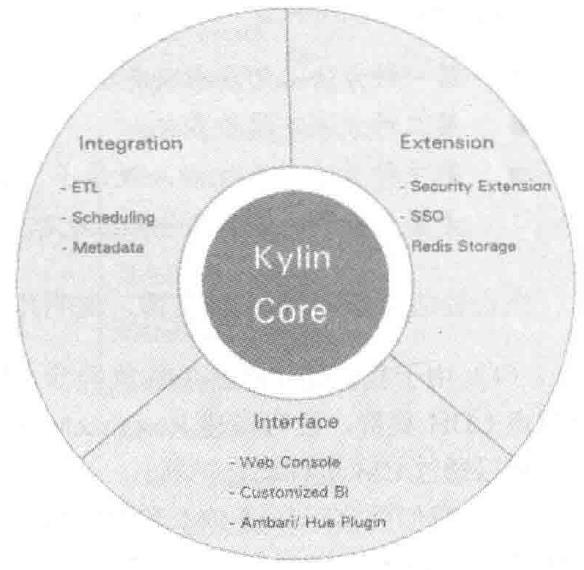
ETL: Extract-Transform-Load
用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
以上是关于Kylin 维度高级设置的主要内容,如果未能解决你的问题,请参考以下文章