CDH下安装HDFS服务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH下安装HDFS服务相关的知识,希望对你有一定的参考价值。
参考技术A Hadoop 分布式文件系统 (HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。进入Cloudera Manager管理页面
选择需要添加服务的集群,添加服务
继续
分配HDFS中的角色
继续
维护着文件系统树及整棵树内所有的文件和目录,HDFS 文件系统中处理客服端读写请求、管理数据块(Block )的映射信息、配置副本策略等管理工作
DataNode 执行实际操作。DataNode 表示实际存储的数据块,同时可以执行数据块的读写操作
要作用是定期将编辑日志和元数据信息合并,防止编辑日志文件过大,并且能保证其信息与namenode信息保持一致。它不是NameNode的备份,但可以做备份,其主要工作是帮助NameNode合并editslog,减少NameNode的启动时间。
允许HDFS作为客户端本地文件系统的一部分挂载在本地文件系统
基于HTTP操作hadoop hdfs文件系统
CDH-Kerberos环境下使用flume消费带Sentry认证的kafka数据保存到hdfs中
前提:
1.kerberos环境可用
2.flume服务可用
3.kafka服务可用并做了sentry权限管理
4.hdfs服务可用并集成了sentry权限管理
1 配置flume
打开CDH-Flume服务界面,点击配置,搜索配置。输入agent配置内容(注意代理名称要和配置文件中的一致!!!)
配置文件内容 :
testkafka.channels = c1
testkafka.sources = s1
testkafka.sinks = k1
testkafka.sources.s1.type =org.apache.flume.source.kafka.KafkaSource
testkafka.sources.s1.kafka.bootstrap.servers=beta2.hadoop.com:9092,beta3.hadoop.com:9092,beta4.hadoop.com:9092
testkafka.sources.s1.kafka.topics = xt_test_flume2hdfs
testkafka.sources.s1.kafka.consumer.group.id = flume-consumer
testkafka.sources.s1.kafka.consumer.security.protocol= SASL_PLAINTEXT
testkafka.sources.s1.kafka.consumer.sasl.mechanism= GSSAPI
testkafka.sources.s1.kafka.consumer.sasl.kerberos.service.name= kafka
testkafka.sources.s1.channels = c1
testkafka.channels.c1.type = memory
testkafka.sinks.k1.type = hdfs
testkafka.sinks.k1.channel = c1
testkafka.sinks.k1.hdfs.kerberosKeytab= /flume-keytab/xiet.keytab
testkafka.sinks.k1.hdfs.kerberosPrincipal= xiet@BETA.COM
testkafka.sinks.k1.hdfs.path =/user/xiet/kafka-test20181102
testkafka.sinks.k1.hdfs.filePrefix = events-
testkafka.sinks.k1.hdfs.writeFormat = Text配置文件中,指定了kafka的验证方式,为SASL_PLAINTEXT,需要配置Jaas.conf文件
写入HDFS需要kerberos认证,并且认证账户需要有写入路径的写入权限
在配置页面搜索:Flume Agent 的 Java 配置选项
配置agent的java配置,指定flume权限认证的配置,此处配置为/flume-keytab/flume_jaas.conf,要在相应的agent服务器创建此文件并配置。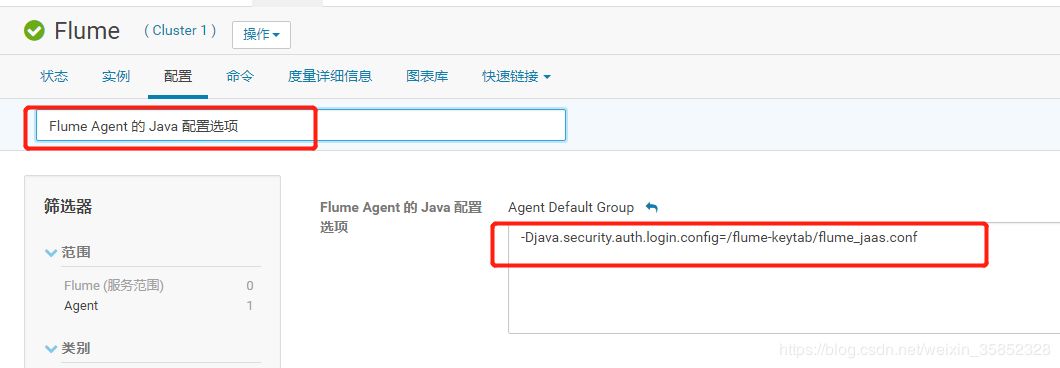
到此在CM上的配置完毕,接下来到agent所在的服务器中配置flume的认证文件
/flume-keytab/flume_jaas.conf
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
serviceName="kafka"
keyTab="flume.keytab"
principal="flume/beta4.hadoop.com@BETA.COM";
};2 kafka配置
创建角色flume
赋予相关topic权限给flume
此处的topic和consumer group和上一小节中的flume配置中保持一致!
[root@beta4 run-kafka]# kafka-sentry -cr -r flume
[root@beta4 run-kafka]# kafka-sentry -arg -r flume -g flume
[root@beta4 run-kafka]# kafka-sentry -gpr -r flume -p "Topic=xt_test_flume2hdfs->action=all"
[root@beta4 run-kafka]# kafka-sentry -gpr -r flume -p "CONSUMERGROUP=flume-consumer->action=all"3 测试
完成上两小节的配置后,确保kafka和flume启动并为最新的配置项。
开始测试:
往topic中生产数据:
[root@beta4 run-kafka]# sh run.sh
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
0 xiet0
1 xiet1
2 xiet2
3 xiet3
4 xiet4
5 xiet5
6 xiet6
7 xiet7
8 xiet8
9 xiet9 在这里我发送了十条数据到kafka中,在cm查看flume的日志信息
显示成功,再到hue中查看hdfs目录
写入成功,测试完成!
---------------------
来源:CSDN
原文:https://blog.csdn.net/weixin_35852328/article/details/83661279
版权声明:本文为博主原创文章,转载请附上博文链接!
以上是关于CDH下安装HDFS服务的主要内容,如果未能解决你的问题,请参考以下文章
0005-Windows Kerberos客户端配置并访问CDH