NLP-词向量:如何理解TF-IDF?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP-词向量:如何理解TF-IDF?相关的知识,希望对你有一定的参考价值。
参考技术A TF-IDF(term frequency–inverse document frequency)是一种统计方法,用来衡量字词对于文本的重要程度。字词的重要性随着它在当前文本中出现的频率成正比,随着它在语料库中其他文本中出现的频率成反比,因此TD-IDF也经常被用来提取文本的特征。
本文主要讲解什么是TF-IDF以及TF-IDF提取词向量的实现过程。
TF顾名思义就是词频,即
表示某词在一个文本中出现的频率,一般而言,某词在文本中出现的频率越高,那么可以认为该词对于文本的重要程度比较高(当然,类似于 啊/了/的 之类的停用词不算,本次讨论的词中假设已经去除了停用词),比如在本篇文章中反复提到 TF ,那么可以直观的认可 TF 对于本文的重要性。但是...但是...请考虑如下场景:
有三个文本 构成一个语料库 ,需要提取每一个文本的特征,假设
按照TF的理论:
那么问题来了 ,那这样 还能作为特征词吗?能!那如何处理这种 脚踏两只船 的情况呢? 权重 !没毛病,就是 权重 ,也就是下文的IDF。
IDF((inverse document frequency),叫做逆文档频率,用来衡量词在语料库中的常见程度。通俗的来讲,就是衡量词在语料库中的权重,比如上文提到 脚踏两只船 的家伙,权重就可以少一点,更为甚者,就更少一点,反之,如果 一夫一妻 的,作为嘉奖,给予最大权重,算是满分。下面亮出公式:
以TF-IDF方式提取词向量
词向量
自然语言处理(NLP)
NLP中最细粒度的是词语(word),词语组成句子,句子再组成段落、章节和文档。所以NLP的核心问题就是:如何理解word
如何理解word
由于目标是与计算机对接,其核心就是如何给计算机描述一个word,有以下两种描述方式:
One-hot Representation
Distributional Representation
One-hot Representation
采用稀疏存储,把每个词表示成一个很长的向量,向量长度是词表大小,向量中只有一个值是1,其余全是0
缺点:稀疏且高维度
没有语义信息
Distributional Representation
分布式表示:对于每一个词,用低维稠密的向量来表示,每个维度可以表示该词在这个维度的分布情况
注意:向量长度可以自己指定
word2vec是由谷歌科学家Mikolov在2013年所提出来的算法,其算法解决了如何将word映射成一个能保持语义信息的向量

word2vec采用Skip-Gram语言模型:learning word representations by predicting its nearby words
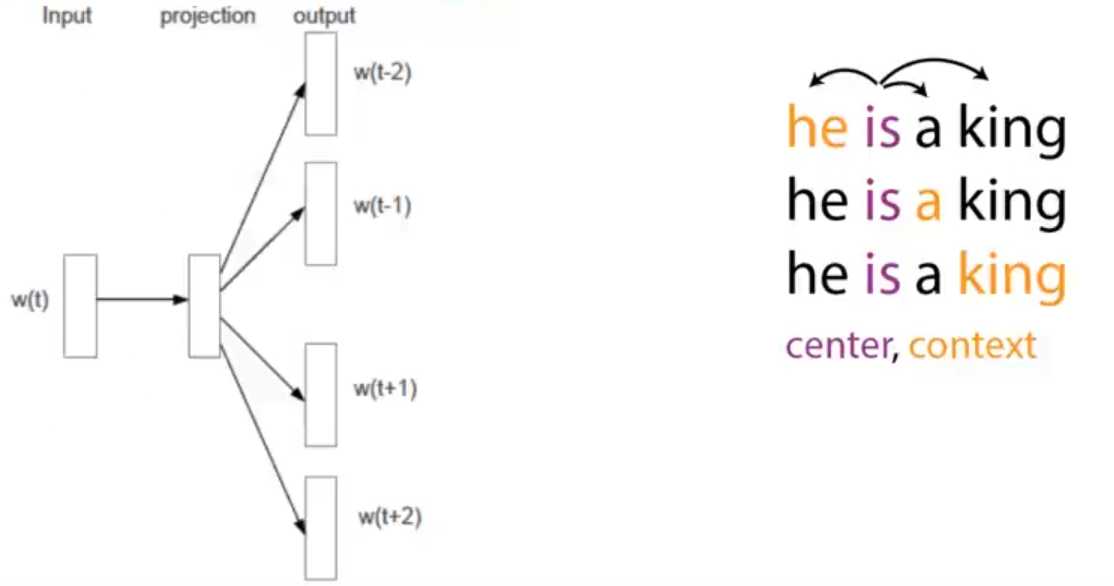

进行优化
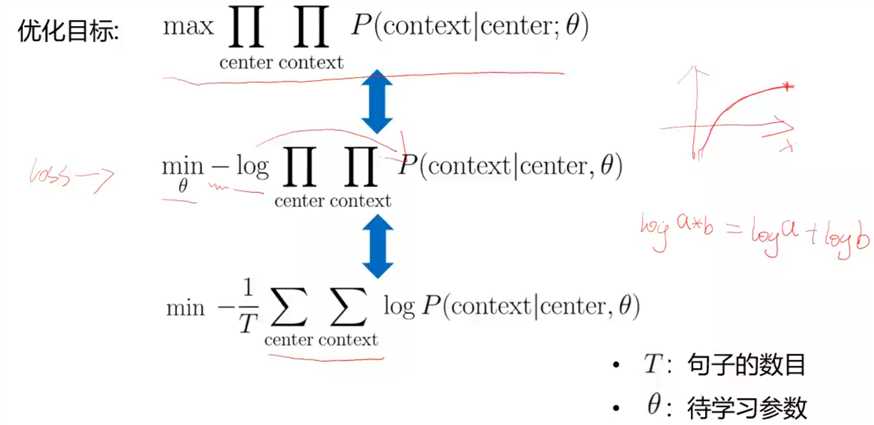
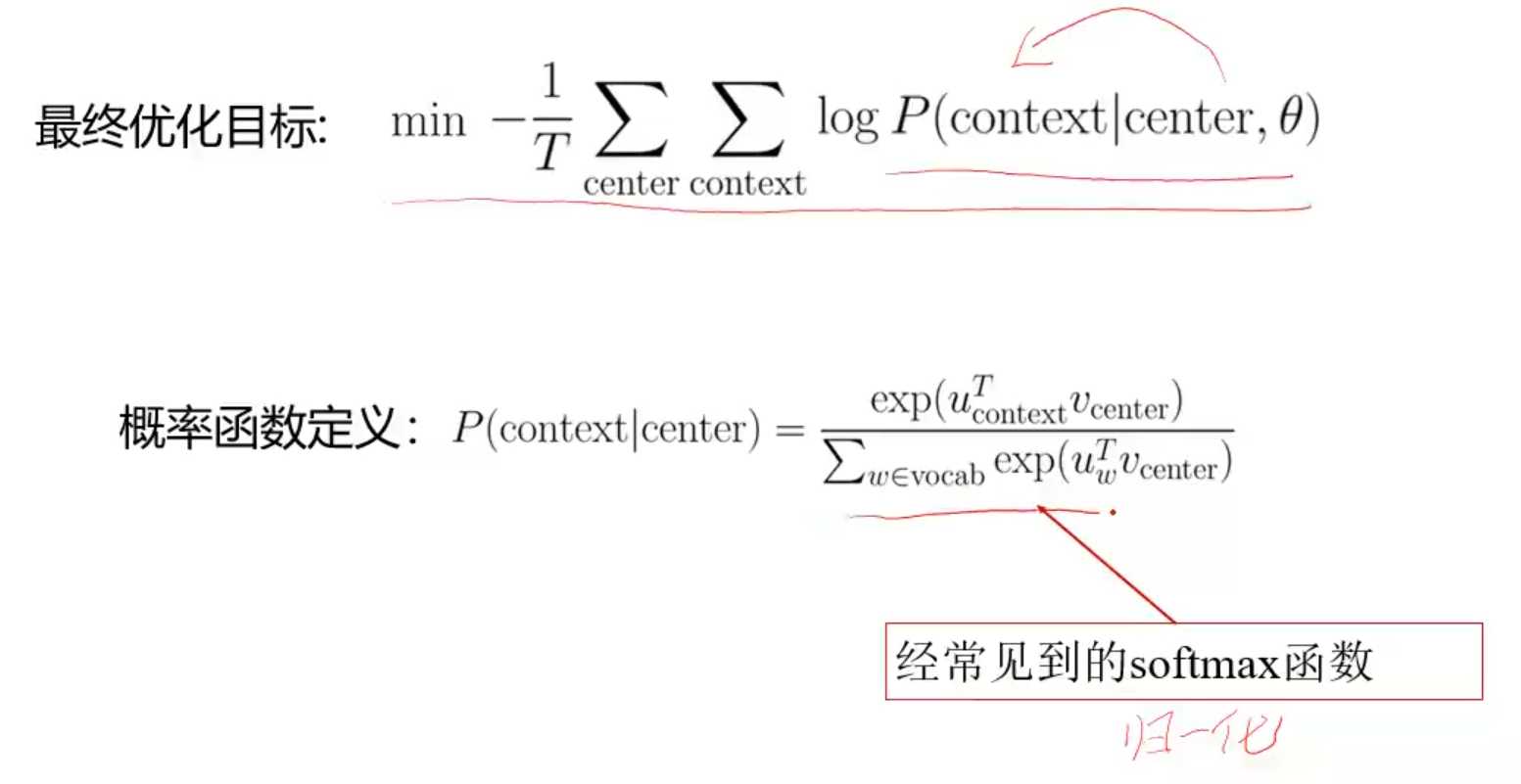
Word2vec应用
有非常多的应用,比如搜索,文档分类,推荐等等
代表性工作:谷歌的神经翻译机,将Cn^2个翻译模型简化为一个模型(传说中的巴别通天塔)
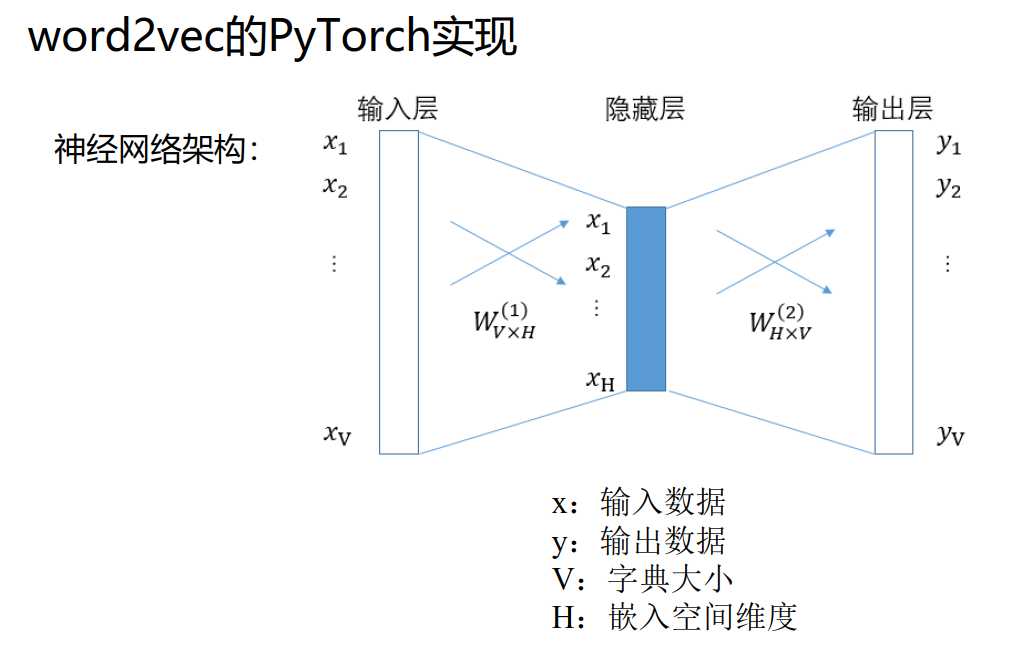

以上是关于NLP-词向量:如何理解TF-IDF?的主要内容,如果未能解决你的问题,请参考以下文章