什么是68-95-99.7 规律
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是68-95-99.7 规律相关的知识,希望对你有一定的参考价值。
我现在在国外学习高3的数学,看到一个不明白的地方,68-95-99.7 rule and z-scores 谢谢回答的人。
68-95-99.7规律就是经验法则,具体介绍如下:
经验法则是正态分布中决定平均值与标准差的统计法则。根据此法则,68%的数据分布在第一个标准差的范围内,95%的数据分布在第二个标准差的范围内,99.7%的数据分布在第三个标准差的范围内。因此它也被称为68-95-99.7或三σ法则。
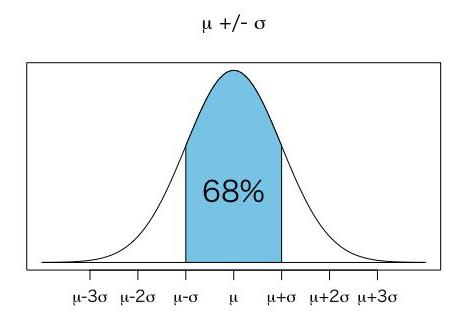
单模分布下正负三个标准差内的几率
在不是正态分布的情形下,也有另一个对应的三西格马定律,即使是在非正态分布的情形下,至少会有88.8%的几率会在正负三个标准差的范围内,这是依照切比雪夫不等式的结果。
若是单模分布(unimodal distributions)下,正负三个标准差内的几率至少有95%,若一些符合特定条件的分布,几率至少会到98%。
参考技术A 正态分布的"68-95-99.7法则"在实际应用上,常考虑一组数据具有近似于正态分布的机率分布。若其假设正确,则约68%数值分布在距离平均值有1个标准差之内的范围,约95%数值分布在距离平均值有2个标准差之内的范围,以及约99.7%数值分布在距离平均值有3个标准差之内的范围。称为"68-95-99.7法则"或"经验法则".
参考资料:http://blog.sina.com.cn/s/blog_562a1ba00100d55i.html
本回答被提问者和网友采纳什么是机器学习
零、什么是机器学习
利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定场景的决策
- 解决的问题:
未来不确定场景的决策 - 怎么解决问题
利用计算机从历史数据中挖出的规律来解决问题 - 机器学习要素
- 主体
主体是计算机 - 数据
数据量越大,找出的规律越精准 - 规律
通过算法,找到规律,机器学习系统利用规律自动生成落地方案
- 主体
一、机器学习的源动力
- 从历史数据中找出规律,把这些规律用到对未来场景的预测与决定;
- 用数据替代专家
- 经济驱动,数据变现
二、机器学习算法分类
-
分类方法一
- 有监督学习
- 分类算法
- 回归算法
- 无监督学习
- 聚类算法
- 半监督学习(强化学习)
- 有监督学习
-
算法分类方法二
- 分类与回归
- 聚类
- 标注
- 算法分类方法三
- 生成模型
- 判别模型
三、机器学习常见算法
| 序号 | 挖掘主题 | 算法 |
|---|---|---|
| 1 | 分类 | C4.5 |
| 2 | 聚类 | K-Means |
| 3 | 统计学习 | SVM |
| 4 | 关联分析 | Apriori |
| 5 | 统计学习 | EM |
| 6 | 链接挖掘 | PageRank |
| 7 | 集装与推进 | AdaBoost |
| 8 | 分类 | kNN |
| 9 | 分类 | Naiive Bayes |
| 10 | 分类 | CART |
- 其他常见算法
- FP-Growth
- 逻辑回归
- RF、GBDT
- 推荐算法
- LDA
- Word2Vector
- HMM、CRF
- 深度学习
机器学习解决问题步骤
- 确定目标
- 业务需求
- 数据
- 特征工程
- 训练模型
- 定义模型
- 定义损失函数
- 优化算法
- 模型评估
- 交叉验证
- 效果评估
以上是关于什么是68-95-99.7 规律的主要内容,如果未能解决你的问题,请参考以下文章