mysql中一个update语句如何去写
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql中一个update语句如何去写相关的知识,希望对你有一定的参考价值。
假如我现在又个表 字段名称为sync_count 我现在要update update的条件是 如果这个字段的结果大于100 那么就减去100再加30 如果是小于100的就直接加30 这个语句该怎么写 求大神指点 谢谢了
UPDATE [LOW_PRIORITY] [IGNORE] tbl_name
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_definition]
[ORDER BY ...]
[LIMIT row_count]
其次,多表的UPDATE语句:
UPDATE [LOW_PRIORITY] [IGNORE] table_references
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_definition]
UPDATE语法可以用新值更新原有表行中的各列。
SET子句指示要修改哪些列和要给予哪些值。WHERE子句指定应更新哪些行。
如果没有WHERE子句,则更新所有的行。如果指定了ORDER BY子句,则按照被指定的顺序对行进行更新。
LIMIT子句用于给定一个限值,限制可以被更新的行的数目。
UPDATE语句支持以下修饰符:
1,如果您使用LOW_PRIORITY关键词,则UPDATE的执行被延迟了,直到没有其它的客户端从表中读取为止。
2,如果您使用IGNORE关键词,则即使在更新过程中出现错误,更新语句也不会中断。
如果出现了重复关键字冲突,则这些行不会被更新。如果列被更新后,新值会导致数据转化错误,则这些行被更新为最接近的合法的值。
如果您在一个表达式中通过tbl_name访问一列,则UPDATE使用列中的当前值。
例如,把年龄列设置为比当前值多一:
代码如下:
mysql> UPDATE persondata SET age=age+1;
UPDATE赋值被从左到右评估。
例如,对年龄列加倍,然后再进行增加:
代码如下:
mysql> UPDATE persondata SET age=age*2, age=age+1;
如果您把一列设置为其当前含有的值,则MySQL会注意到这一点,但不会更新。
如果您把被已定义为NOT NULL的列更新为NULL,则该列被设置到与列类型对应的默认值,并且累加警告数。
对于数字类型,默认值为0;对于字符串类型,默认值为空字符串(\'\');对于日期和时间类型,默认值为“zero”值。
UPDATE会返回实际被改变的行的数目。Mysql_info() C API函数可以返回被匹配和被更新的行的数目,以及在UPDATE过程中产生的警告的数量。
您可以使用LIMIT row_count来限定UPDATE的范围。LIMIT子句是一个与行匹配的限定。
只要发现可以满足WHERE子句的row_count行,则该语句中止,不论这些行是否被改变。
如果一个UPDATE语句包括一个ORDER BY子句,则按照由子句指定的顺序更新行。
您也可以执行包括多个表的UPDATE操作。table_references子句列出了在联合中包含的表。
例子:
代码如下:
SQL>UPDATE items,month SET items.price=month.price
WHERE items.id=month.id;
说明:以上代码显示出了使用逗号操作符的内部联合,但是multiple-table UPDATE语句可以使用在SELECT语句中允许的任何类型的联合,比如LEFT JOIN。
注释:不能把ORDER BY或LIMIT与multiple-table UPDATE同时使用。
在一个被更改的multiple-table UPDATE中,有些列被引用。您只需要这些列的UPDATE权限。有些列被读取了,但是没被修改。您只需要这些列的SELECT权限。
如果您使用的multiple-table UPDATE语句中包含带有外键限制的InnoDB表,则MySQL优化符处理表的顺序可能与上下层级关系的顺序不同。
在此情况下,语句无效并被 回滚。同时,更新一个单一表,并且依靠ON UPDATE功能。
该功能由InnoDB提供,用于对其它表进行相应的修改。
目前,不能在一个子查询中更新一个表,同时从同一个表中选择。
update语句的几种基本用法
A. 使用简单的 UPDATE
下列示例说明如果从 UPDATE 语句中去除 WHERE 子句,所有的行会受到什么影响。
下面这个例子说明,如果表 publishers 中的所有出版社将总部搬迁到佐治亚州的亚特兰大市,表 publishers 如何更新。
代码如下:
UPDATE publishers
SET city = \'Atlanta\', state = \'GA\'
本示例将所有出版商的名字变为 NULL。
复制代码 代码如下:
UPDATE publishers
SET pub_name = NULL
也可以在更新中使用计算值。本示例将表 titles 中的所有价格加倍。
代码如下:
UPDATE titles
SET price = price * 2
B.把 WHERE 子句和 UPDATE 语句一起使用
WHERE 子句指定要更新的行例如,在下面这个虚构的事件中,北加利福尼亚更名为 Pacifica(缩写为 PC),而奥克兰的市民投票决定将其城市的名字改为 Bay City。这个例子说明如何为奥克兰市以前的所有居民(他们的地址已经过时)更新表 authors。
代码如下:
UPDATE authors
SET state = \'PC\', city = \'Bay City\'
WHERE state = \'CA\' AND city = \'Oakland\'
必须编写另一个语句来更改北加利福尼亚其它城市的居民所在的州名。
C.通过 UPDATE 语句使用来自另一个表的信息
本示例修改表 titles 中的 ytd_sales 列,以反映表 sales 中的最新销售记录。
复制代码 代码如下:
UPDATE titles
SET ytd_sales = titles.ytd_sales + sales.qty
FROM titles, sales
WHERE titles.title_id = sales.title_id
AND sales.ord_date = (SELECT MAX(sales.ord_date) FROM sales)
这个例子假定,一种特定的商品在特定的日期只记录一批销售量,而且更新是最新的。如果不是这样(即如果一种特定的商品在同一天可以记录不止一批销售量),这里所示的例子将出错。例子可正确执行,但是每种商品只用一批销售量进行更新,而不管那一天实际销售了多少批。这是因为一个 UPDATE 语句从不会对同一行更新两次。
对于特定的商品在同一天可销售不止一批的情况,每种商品的所有销售量必须在 UPDATE 语句中合计在一起,如下例所示:
代码如下:
UPDATE titles
SET ytd_sales =
(SELECT SUM(qty)
FROM sales
WHERE sales.title_id = titles.title_id
AND sales.ord_date IN (SELECT MAX(ord_date) FROM sales))
FROM titles, sales
D. 将 UPDATE 语句与 SELECT 语句中的 TOP 子句一起使用
这个例子对来自表 authors 的前十个作者的 state 列进行更新。
代码如下:
UPDATE authors
SET state = \'ZZ\'
FROM (SELECT TOP 10 * FROM authors ORDER BY au_lname) AS t1
WHERE authors.au_id = t1.au_id
以上就是mysql update语句用法的全部内容 参考技术A 可以分成两句update语句来执行:
update table_name set sync_count=sync_count-100+30 where sync_count>100;
update table_name set sync_count=sync_count+30 where sync_count<100; 参考技术B update yourtablename set sync_count=(case when sync_count>100 then sync_count -100 + 30 else sync_count + 30 end) 参考技术C update 表名 set sync_count = if(sync_count > 100,sync_count -100 + 30, sync_count + 30);本回答被提问者采纳
[MySQL] update语句的redo log过程
update语句是如何执行 , 如何将执行后的新数据持久化在磁盘中
可以假设两种情境:
1. 假设MySQL在更新之后只更新内存中的数据就返回,然后再某一时刻进行IO将数据页持久化。这样所有操作都是在内存中,可以想象此时的MySQL性能是特别高的。但是,如果在更新完内存又还没有进行持久化的这段时间,MySQL宕机了,那么我们的数据就丢失了。
2. 另外一种情况:每次MySQL将内存中的页更新好后,立刻进行IO,只有数据落盘后才返回。此时我们可以保证数据一定是正确的。但是,每一次的操作,都要进行IO,此时MySQL的效率变得非常低。
我们来看看MySQL是如何做到保证性能的情况下,还保证数据不丢的。
update 表 set a = 1 where id = 1;
如何保证数据一致性
重做日志(redo log)
这里要介绍一个很重要的日志模块,称为rodo log(重做日志)。重做日志是InnoDB引擎特有的。
重做日志在更新数据的时候,会记录在哪个数据页更新了什么数据,并且只要成功的在重做日志记录了这次更新,不需要将内存中的数据页写回磁盘,就可以认为这次更新已经完成了。
1. MySQL里有一个名词,叫WAL技术,WAL的全称是Write-Ahead-Logging,它的关键点就是先写日志,再写磁盘,也就是说只要保证了日志的落盘,数据就一定正确。此时只要保存了日志,就算此时MySQL宕机了,没有将数据页写回磁盘,也可以在之后利用日志进行恢复。
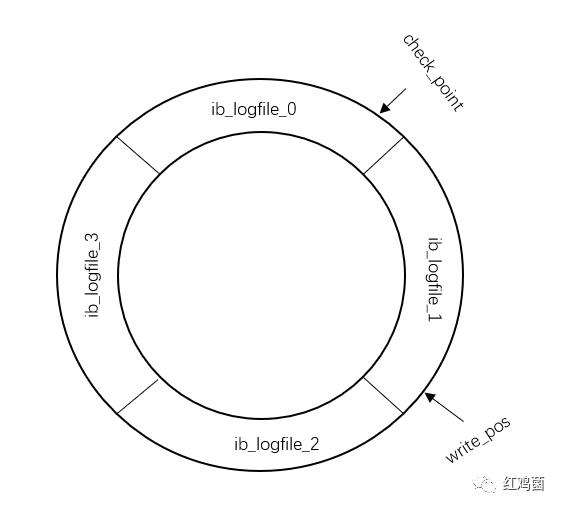
但是,InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB。固定大小也就造成了一个问题,redo log是会被写满的。
2. InnoDB采取了循环写的方式。注意看,这里有两个指针。write_pos表示当前写的位置,只要有记录更新了,write_pos就会往后移动。而check_point表示检查点,只要InnoDB将check_point指向的修改记录更新到了磁盘中,check_point将会往后移动。
如果我们把这一行数据所在的内存页更新好了,并且写入了rodo log中,此时将返回修改成功的提示。然后在rodo log中表现为记录了在某一个内存页的更新记录
此时在磁盘中,数据a未改变,在内存中,a改为了1,在rodo log中记录了这个内存页的更新记录,write_pos往后移动。
3. 只有成功的写回了磁盘,check_point才可以往后移动。这个设计,使得rodo log是可以无限重复使用的。
以上是关于mysql中一个update语句如何去写的主要内容,如果未能解决你的问题,请参考以下文章